




Diego del Alamo
@delalamo.xyz
Computational protein engineering & synthetic biochemistry at Takeda
Opinions my own
https://linktr.ee/ddelalamo
Opinions my own
https://linktr.ee/ddelalamo
Anyway, if anyone in academia has some spare time & compute, I'd love to see if the MD-trained NNs are any better than the vanilla models at multi-state prediction, as it wasn't tested in the paper (model weights have a non-commercial license so they're off-limits to me)

November 17, 2025 at 3:22 PM
Anyway, if anyone in academia has some spare time & compute, I'd love to see if the MD-trained NNs are any better than the vanilla models at multi-state prediction, as it wasn't tested in the paper (model weights have a non-commercial license so they're off-limits to me)
A randomly valuable thing that the simplefold authors did was fine-tune all six structure prediction models on MD-ATLAS data, and honestly I can't tell if there's any benefit to scaling these things if the goal is ensemble prediction

November 17, 2025 at 3:22 PM
A randomly valuable thing that the simplefold authors did was fine-tune all six structure prediction models on MD-ATLAS data, and honestly I can't tell if there's any benefit to scaling these things if the goal is ensemble prediction
Has this idea of sampling neighbors from an inverse cubic distribution been used in protein structure GNNs at all since the idea was first presented in the Chroma paper ~3 years ago? I thought it was incredibly clever and expected it to catch on, but haven't seen it since
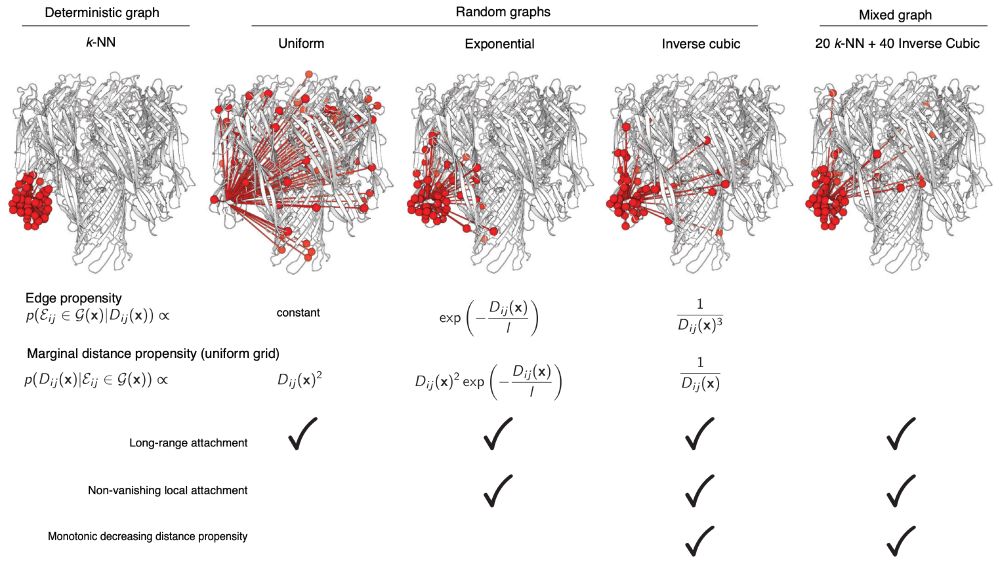
November 16, 2025 at 9:01 PM
Has this idea of sampling neighbors from an inverse cubic distribution been used in protein structure GNNs at all since the idea was first presented in the Chroma paper ~3 years ago? I thought it was incredibly clever and expected it to catch on, but haven't seen it since
Biomolecular diffusion models aren't able to reproduce the equilibrium dynamics of the simulations they're trained on arxiv.org/pdf/2506.17139

November 14, 2025 at 3:37 PM
Biomolecular diffusion models aren't able to reproduce the equilibrium dynamics of the simulations they're trained on arxiv.org/pdf/2506.17139
Very cool paper that samples unique conformations by adding a guidance term to diffusion-based protein structure prediction to steer away from already-sampled states. Important caveat: doesn't work with mAbs because it only looks at helices and sheets
openreview.net/pdf/dd8aa97e...
openreview.net/pdf/dd8aa97e...

November 7, 2025 at 6:29 PM
Very cool paper that samples unique conformations by adding a guidance term to diffusion-based protein structure prediction to steer away from already-sampled states. Important caveat: doesn't work with mAbs because it only looks at helices and sheets
openreview.net/pdf/dd8aa97e...
openreview.net/pdf/dd8aa97e...
An absolutely fascinating edge case from BoltzGen: apparently it loves to design ubiquitins, but only when the prompted sequence is 73-76 AAs long! Reminds of a method from Possu Huang's group (forget which) that designed TIM barrels with lots of enthusiasm

October 27, 2025 at 5:03 PM
An absolutely fascinating edge case from BoltzGen: apparently it loves to design ubiquitins, but only when the prompted sequence is 73-76 AAs long! Reminds of a method from Possu Huang's group (forget which) that designed TIM barrels with lots of enthusiasm
Why do inverse folding methods hate aromatics so much? From the BoltzGen paper

October 27, 2025 at 3:36 PM
Why do inverse folding methods hate aromatics so much? From the BoltzGen paper
Boltz is now a separate institution? ...

October 27, 2025 at 1:19 AM
Boltz is now a separate institution? ...
Love this preprint and glad to see the field converge on a specific, highly descriptive term for this phenomenon

October 14, 2025 at 5:57 PM
Love this preprint and glad to see the field converge on a specific, highly descriptive term for this phenomenon
New job! Senior scientist in AI/ML at Takeda. The plan is to do some fun stuff with biomolecular foundation models
October 13, 2025 at 8:59 PM
New job! Senior scientist in AI/ML at Takeda. The plan is to do some fun stuff with biomolecular foundation models
Another one - PDB 8F2X chain H (3.5 Å resolution, shown in gold). Totally different authors. Seems like aromatics immediately before the conserved J-gene tryptophan throws off assignment in this area; 7czv has a phenylalanine before the tryptophan

October 9, 2025 at 12:51 PM
Another one - PDB 8F2X chain H (3.5 Å resolution, shown in gold). Totally different authors. Seems like aromatics immediately before the conserved J-gene tryptophan throws off assignment in this area; 7czv has a phenylalanine before the tryptophan
If you've been including PDB 9DMQ chain F with ANARCI/AbNum-derived numbering in your training set for learning something like CDR design, then you'll be surprised to learn that the CDRH3 is only 7 AAs long and encompasses exclusively the region in green opig.stats.ox.ac.uk/webapps/sabd...

October 9, 2025 at 12:39 PM
If you've been including PDB 9DMQ chain F with ANARCI/AbNum-derived numbering in your training set for learning something like CDR design, then you'll be surprised to learn that the CDRH3 is only 7 AAs long and encompasses exclusively the region in green opig.stats.ox.ac.uk/webapps/sabd...
The entire J-gene of PDB 7czv (3.3 Å, shown in salmon) seems to have fallen victim to a register/misassignment error, with the C-terminal valines (right) and tryptophan (center-left) on the wrong side of the beta sheet compared to where they would be expected to be
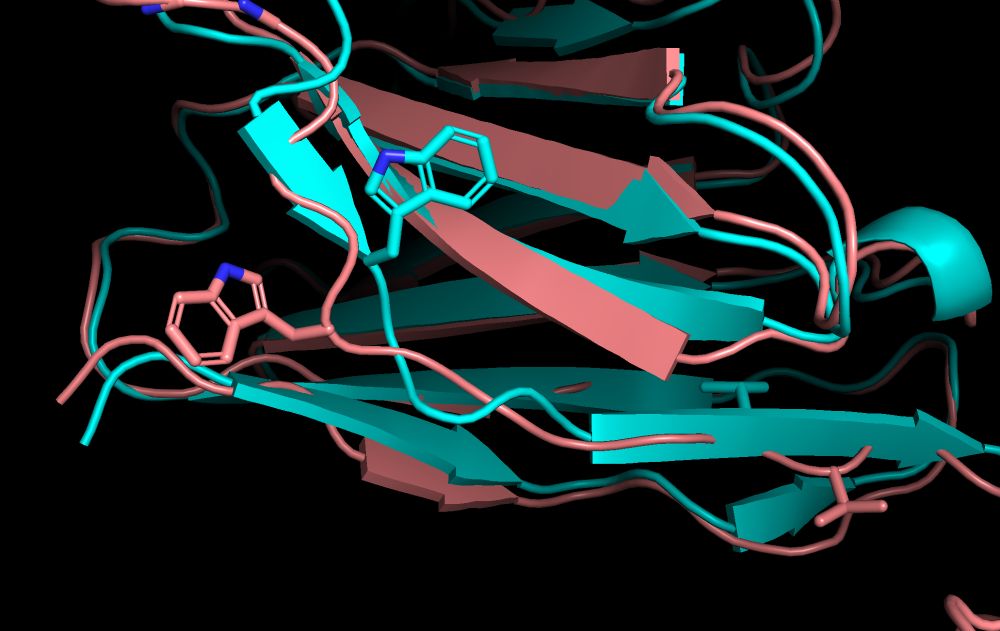
October 6, 2025 at 8:41 PM
The entire J-gene of PDB 7czv (3.3 Å, shown in salmon) seems to have fallen victim to a register/misassignment error, with the C-terminal valines (right) and tryptophan (center-left) on the wrong side of the beta sheet compared to where they would be expected to be
The worst offender I've found so far is PDB 5OMM chain C on Sabdab, which has many unassigned residues despite being 1.7 Å resolution. For example its C-terminal VTVSS starts at IMGT pos 115 instead of pos 124. Probably AbNum/ANARCI struggling w/ the gaps
opig.stats.ox.ac.uk/webapps/sabd...
opig.stats.ox.ac.uk/webapps/sabd...

October 4, 2025 at 10:28 PM
The worst offender I've found so far is PDB 5OMM chain C on Sabdab, which has many unassigned residues despite being 1.7 Å resolution. For example its C-terminal VTVSS starts at IMGT pos 115 instead of pos 124. Probably AbNum/ANARCI struggling w/ the gaps
opig.stats.ox.ac.uk/webapps/sabd...
opig.stats.ox.ac.uk/webapps/sabd...

September 24, 2025 at 2:31 PM
Yep. Reminds me of the bar plot error bars that were just capital Ts

September 19, 2025 at 12:29 PM
Yep. Reminds me of the bar plot error bars that were just capital Ts
Protein language models can predict epistasis (non-additivity of multiple point mutations) if predictions are nonlinearly transformed first www.biorxiv.org/content/10.1...

September 19, 2025 at 11:20 AM
Protein language models can predict epistasis (non-additivity of multiple point mutations) if predictions are nonlinearly transformed first www.biorxiv.org/content/10.1...
I posted this on the other site and will repost here: something is fishy with Fig 2F results on inverse folding performance (left). Variance is way too low. Compare that to my results preprinted earlier this year (right). Definitely causing me to scrutinize other results in this paper more closely


September 18, 2025 at 5:10 PM
I posted this on the other site and will repost here: something is fishy with Fig 2F results on inverse folding performance (left). Variance is way too low. Compare that to my results preprinted earlier this year (right). Definitely causing me to scrutinize other results in this paper more closely
This was a great read! If it were up to me, this specific part of rule #4 would be expanded into a full Opinion piece, because proteins for structural characterization are definitely not sampled IID from uniprot/wherever

September 13, 2025 at 3:21 PM
This was a great read! If it were up to me, this specific part of rule #4 would be expanded into a full Opinion piece, because proteins for structural characterization are definitely not sampled IID from uniprot/wherever
Time to test their claim that diffusion is competitive with hallucination in generating realistic backbones of huge (>800 AA) proteins...
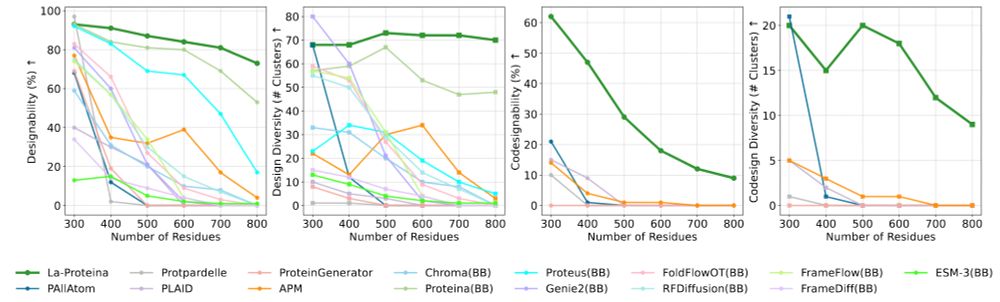
September 11, 2025 at 7:02 PM
Time to test their claim that diffusion is competitive with hallucination in generating realistic backbones of huge (>800 AA) proteins...
An analysis of scaling laws in paired antibody LMs, which mostly learn the composition of germline sequences. Authors conclude that an 650M parameter NN (the sweet spot for generalist PLMs) would require 5.5 M sequences, about ~3x what is publicly available today www.biorxiv.org/content/10.1...

September 8, 2025 at 11:43 AM
An analysis of scaling laws in paired antibody LMs, which mostly learn the composition of germline sequences. Authors conclude that an 650M parameter NN (the sweet spot for generalist PLMs) would require 5.5 M sequences, about ~3x what is publicly available today www.biorxiv.org/content/10.1...
I wonder if there are scientists who keep a running list of urgent scientific questions that are currently unanswerable due to technological limitations, & whether the innovation required in such cases overlaps at all with the products being released on an almost weekly basis now

September 4, 2025 at 5:47 PM
I wonder if there are scientists who keep a running list of urgent scientific questions that are currently unanswerable due to technological limitations, & whether the innovation required in such cases overlaps at all with the products being released on an almost weekly basis now
Unrelated to Bio/ML and highly irresponsible, please enjoy
September 3, 2025 at 10:28 PM
Unrelated to Bio/ML and highly irresponsible, please enjoy
So far the only use case I've found for this is as an auto-generating reference list, but it requires that each citation to be its own note with bibtex info in the YAML frontmatter. Example below



September 1, 2025 at 8:58 AM
So far the only use case I've found for this is as an auto-generating reference list, but it requires that each citation to be its own note with bibtex info in the YAML frontmatter. Example below
Happy storrow drive day to all who celebrate




September 1, 2025 at 8:40 AM
Happy storrow drive day to all who celebrate