



Reposted by Debjit Paul

🚨New Preprint!
In multilingual models, the same meaning can take far more tokens in some languages, penalizing users of underrepresented languages with worse performance and higher API costs. Our Parity-aware BPE algorithm is a step toward addressing this issue: 🧵
In multilingual models, the same meaning can take far more tokens in some languages, penalizing users of underrepresented languages with worse performance and higher API costs. Our Parity-aware BPE algorithm is a step toward addressing this issue: 🧵

August 11, 2025 at 12:28 PM
🚨New Preprint!
In multilingual models, the same meaning can take far more tokens in some languages, penalizing users of underrepresented languages with worse performance and higher API costs. Our Parity-aware BPE algorithm is a step toward addressing this issue: 🧵
In multilingual models, the same meaning can take far more tokens in some languages, penalizing users of underrepresented languages with worse performance and higher API costs. Our Parity-aware BPE algorithm is a step toward addressing this issue: 🧵
Super excited to share that our paper "A Logical Fallacy-Informed Framework for Argument Generation" has received the Outstanding Paper Award 🎉🎉 at NAACL 2025!
Paper: aclanthology.org/2025.naacl-l...
Code: github.com/lucamouchel/...
#NAACL2025
Paper: aclanthology.org/2025.naacl-l...
Code: github.com/lucamouchel/...
#NAACL2025
May 1, 2025 at 1:41 PM
Super excited to share that our paper "A Logical Fallacy-Informed Framework for Argument Generation" has received the Outstanding Paper Award 🎉🎉 at NAACL 2025!
Paper: aclanthology.org/2025.naacl-l...
Code: github.com/lucamouchel/...
#NAACL2025
Paper: aclanthology.org/2025.naacl-l...
Code: github.com/lucamouchel/...
#NAACL2025
Reposted by Debjit Paul

Lots of great news out of the EPFL NLP lab these last few weeks. We'll be at @iclr-conf.bsky.social and @naaclmeeting.bsky.social in April / May to present some of our work in training dynamics, model representations, reasoning, and AI democratization. Come chat with us during the conference!
February 25, 2025 at 9:18 AM
Lots of great news out of the EPFL NLP lab these last few weeks. We'll be at @iclr-conf.bsky.social and @naaclmeeting.bsky.social in April / May to present some of our work in training dynamics, model representations, reasoning, and AI democratization. Come chat with us during the conference!
Reposted by Debjit Paul
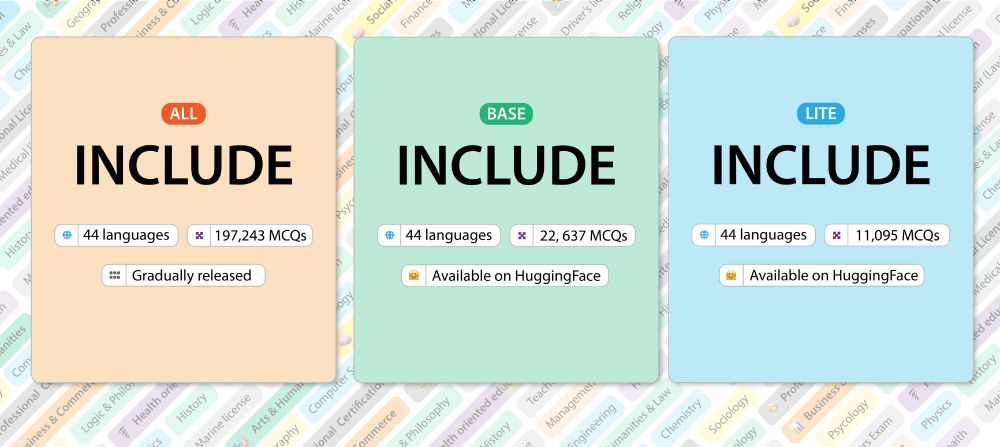
Translating MMLU is great, but global users of multilingual #LLMs don't care all that much about an LLM's understanding of US Law!
Our new #NLProc work centers multilingual #LLM evaluations toward regional knowledge in 44 languages.
Our new #NLProc work centers multilingual #LLM evaluations toward regional knowledge in 44 languages.

🚀 Introducing INCLUDE 🌍: A multilingual LLM evaluation benchmark spanning 44 languages!
Contains *newly-collected* data, prioritizing *regional knowledge*.
Setting the stage for truly global AI evaluation.
Ready to see how your model measures up?
#AI #Multilingual #LLM #NLProc
Contains *newly-collected* data, prioritizing *regional knowledge*.
Setting the stage for truly global AI evaluation.
Ready to see how your model measures up?
#AI #Multilingual #LLM #NLProc
December 2, 2024 at 4:26 PM
Reposted by Debjit Paul
