


Yingtian (David) Tang
@davidtyt.bsky.social
8/🖼️ Big Picture
Optimizing to model world dynamics leads to brain-like representations.
🧠 The visual system isn't a patchwork of modules — it’s a unified system built on shared core principles.
Optimizing to model world dynamics leads to brain-like representations.
🧠 The visual system isn't a patchwork of modules — it’s a unified system built on shared core principles.
July 30, 2025 at 1:39 PM
8/🖼️ Big Picture
Optimizing to model world dynamics leads to brain-like representations.
🧠 The visual system isn't a patchwork of modules — it’s a unified system built on shared core principles.
Optimizing to model world dynamics leads to brain-like representations.
🧠 The visual system isn't a patchwork of modules — it’s a unified system built on shared core principles.
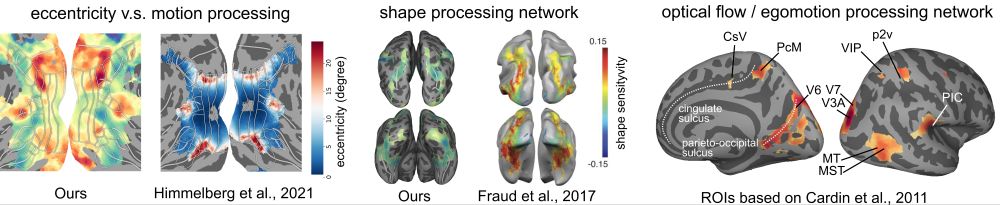
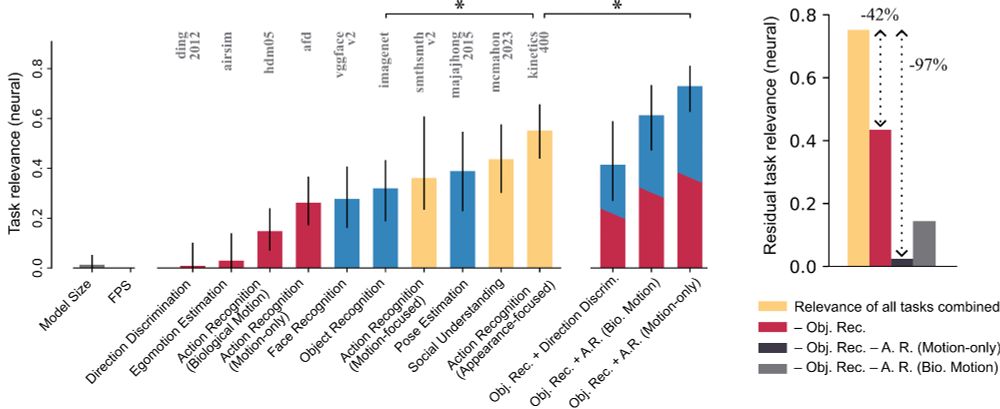
7/🧠 Finding 4
We introduce task-based functional localization.
It:
1. Recovers many prior neuroscience results in a unified way
2. Reveals new structure in action understanding pathways
A novel scalable approach to functional brain mapping.
We introduce task-based functional localization.
It:
1. Recovers many prior neuroscience results in a unified way
2. Reveals new structure in action understanding pathways
A novel scalable approach to functional brain mapping.
July 30, 2025 at 1:38 PM
7/🧠 Finding 4
We introduce task-based functional localization.
It:
1. Recovers many prior neuroscience results in a unified way
2. Reveals new structure in action understanding pathways
A novel scalable approach to functional brain mapping.
We introduce task-based functional localization.
It:
1. Recovers many prior neuroscience results in a unified way
2. Reveals new structure in action understanding pathways
A novel scalable approach to functional brain mapping.
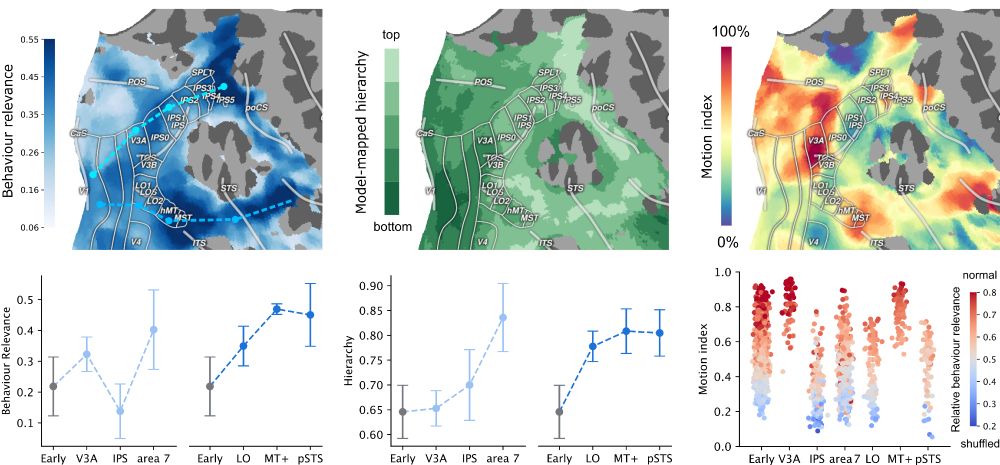
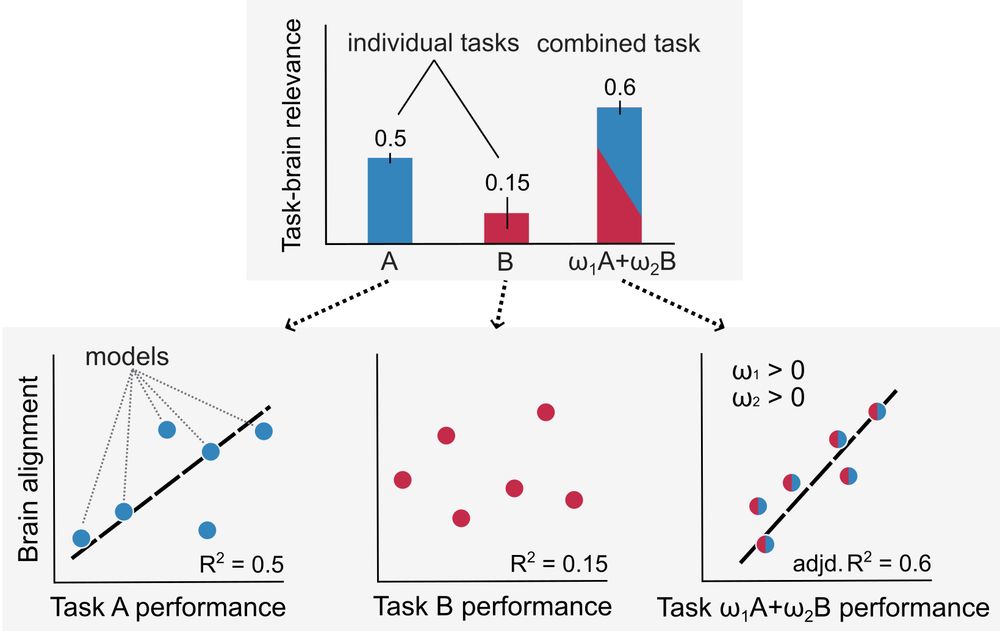
6/🌀 Finding 3
Putting observations together:
• Single-objective models align with all regions and behaviors
• Cortex shows hybrid, smooth representation transitions
💡 A new perspective: the brain may implement a shared feature backbone — reused for diverse tasks, just like a “foundation model”.
Putting observations together:
• Single-objective models align with all regions and behaviors
• Cortex shows hybrid, smooth representation transitions
💡 A new perspective: the brain may implement a shared feature backbone — reused for diverse tasks, just like a “foundation model”.
July 30, 2025 at 1:37 PM
6/🌀 Finding 3
Putting observations together:
• Single-objective models align with all regions and behaviors
• Cortex shows hybrid, smooth representation transitions
💡 A new perspective: the brain may implement a shared feature backbone — reused for diverse tasks, just like a “foundation model”.
Putting observations together:
• Single-objective models align with all regions and behaviors
• Cortex shows hybrid, smooth representation transitions
💡 A new perspective: the brain may implement a shared feature backbone — reused for diverse tasks, just like a “foundation model”.
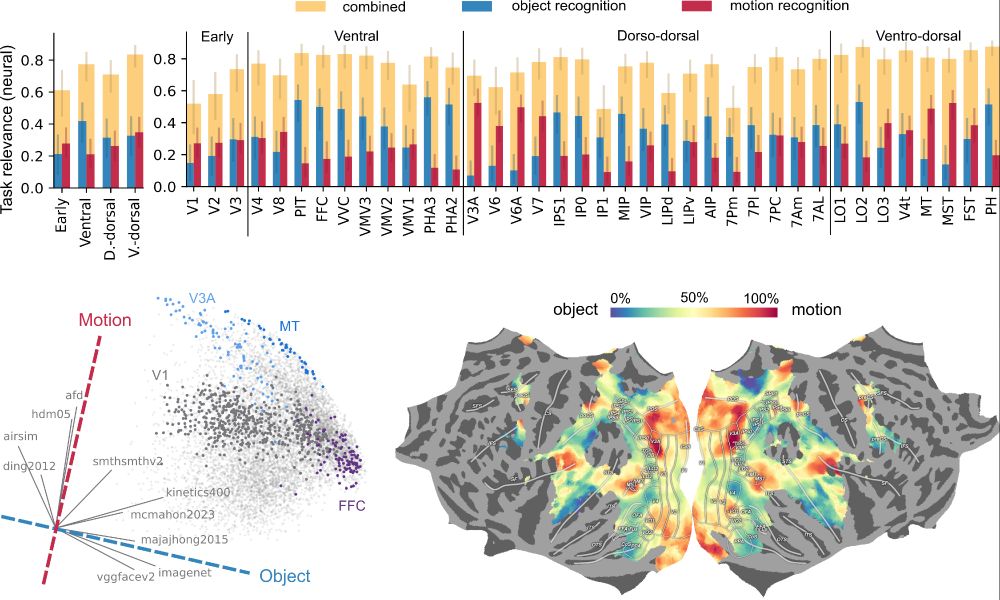
5/🌐 Finding 2.2
These two aren’t isolated — they’re:
• Blended across ventral & dorsal streams
• Smoothly mapped across the cortex
So, the visual system isn’t modular — it’s highly distributed, and the classic stream separation theory appears oversimplified.
These two aren’t isolated — they’re:
• Blended across ventral & dorsal streams
• Smoothly mapped across the cortex
So, the visual system isn’t modular — it’s highly distributed, and the classic stream separation theory appears oversimplified.
July 30, 2025 at 1:36 PM
5/🌐 Finding 2.2
These two aren’t isolated — they’re:
• Blended across ventral & dorsal streams
• Smoothly mapped across the cortex
So, the visual system isn’t modular — it’s highly distributed, and the classic stream separation theory appears oversimplified.
These two aren’t isolated — they’re:
• Blended across ventral & dorsal streams
• Smoothly mapped across the cortex
So, the visual system isn’t modular — it’s highly distributed, and the classic stream separation theory appears oversimplified.
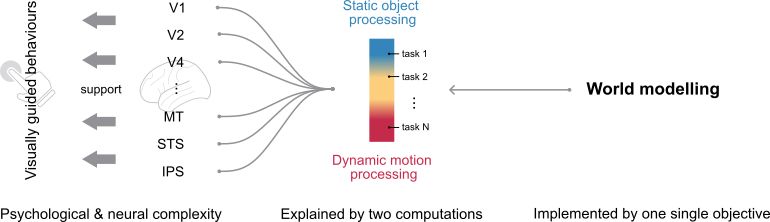
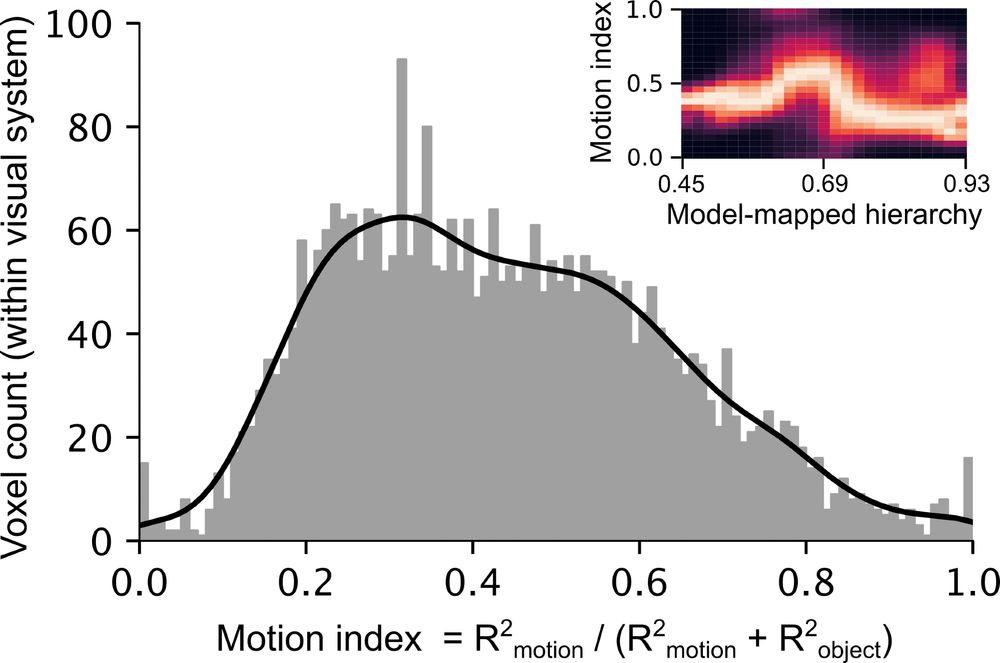
4/🌐 Finding 2.1
So, what does the brain actually compute during dynamic vision?
Across 10 cognitive tasks (e.g., pose, social cues, action), just two suffice to explain brain-like representations:
• Object form
• Appearance-free motion
So, what does the brain actually compute during dynamic vision?
Across 10 cognitive tasks (e.g., pose, social cues, action), just two suffice to explain brain-like representations:
• Object form
• Appearance-free motion
July 30, 2025 at 1:35 PM
4/🌐 Finding 2.1
So, what does the brain actually compute during dynamic vision?
Across 10 cognitive tasks (e.g., pose, social cues, action), just two suffice to explain brain-like representations:
• Object form
• Appearance-free motion
So, what does the brain actually compute during dynamic vision?
Across 10 cognitive tasks (e.g., pose, social cues, action), just two suffice to explain brain-like representations:
• Object form
• Appearance-free motion
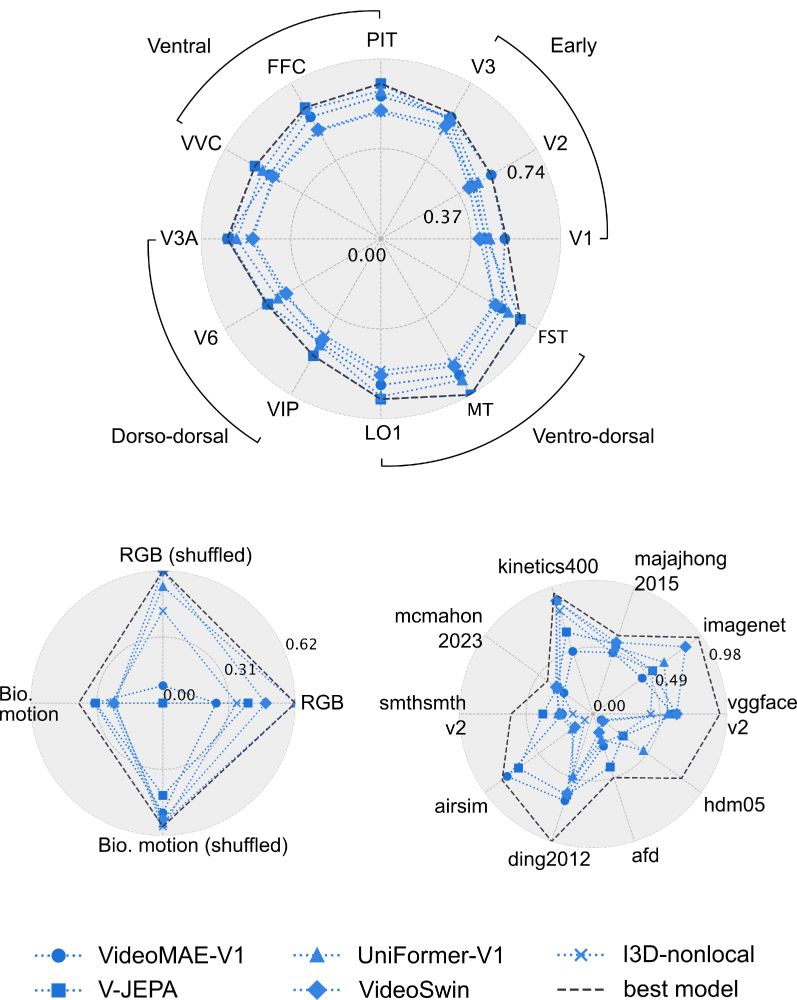
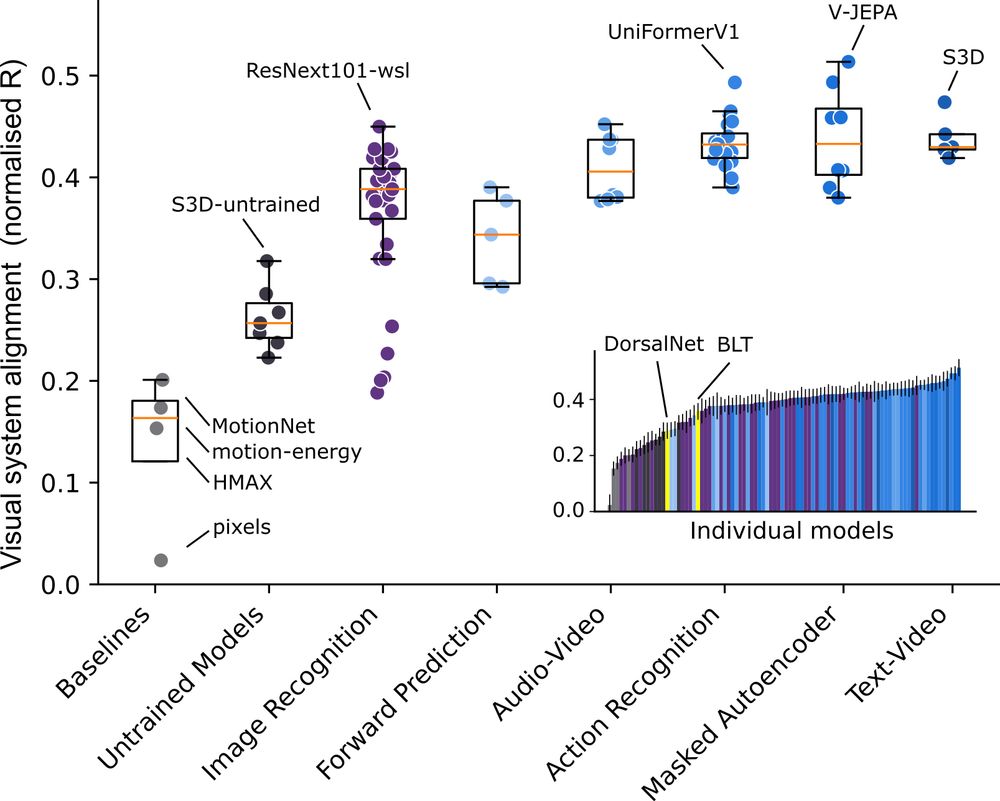
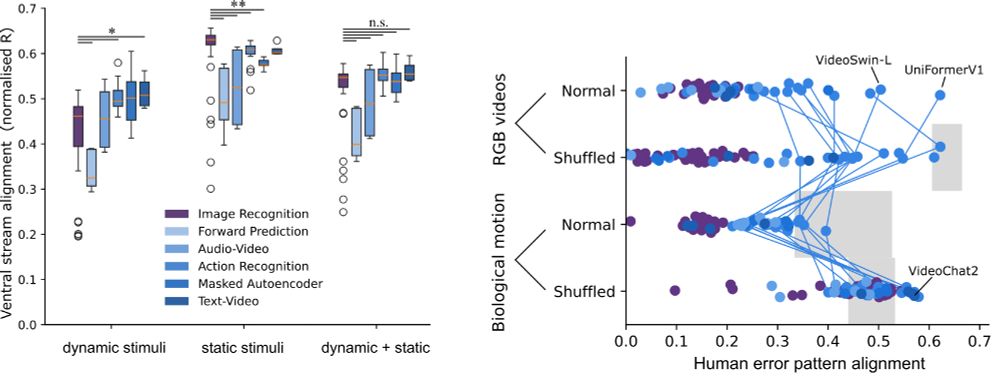
3/📊 Finding 1
✅ Dynamic models > static image models > classic vision models
✅ Across both dorsal & ventral regions
✅ Across neural & behavioral alignment
Best match to brain: V-JEPA.
In general, learning world dynamics give alignment to the whole visual system.
✅ Dynamic models > static image models > classic vision models
✅ Across both dorsal & ventral regions
✅ Across neural & behavioral alignment
Best match to brain: V-JEPA.
In general, learning world dynamics give alignment to the whole visual system.
July 30, 2025 at 1:35 PM
3/📊 Finding 1
✅ Dynamic models > static image models > classic vision models
✅ Across both dorsal & ventral regions
✅ Across neural & behavioral alignment
Best match to brain: V-JEPA.
In general, learning world dynamics give alignment to the whole visual system.
✅ Dynamic models > static image models > classic vision models
✅ Across both dorsal & ventral regions
✅ Across neural & behavioral alignment
Best match to brain: V-JEPA.
In general, learning world dynamics give alignment to the whole visual system.
2/🧪 Approach
We benchmarked diverse video models, each with a different pretraining objective.
Then: tested how well they predict human fMRI responses to natural movies.
🧠 ~10,000 voxels, whole visual system.
We benchmarked diverse video models, each with a different pretraining objective.
Then: tested how well they predict human fMRI responses to natural movies.
🧠 ~10,000 voxels, whole visual system.
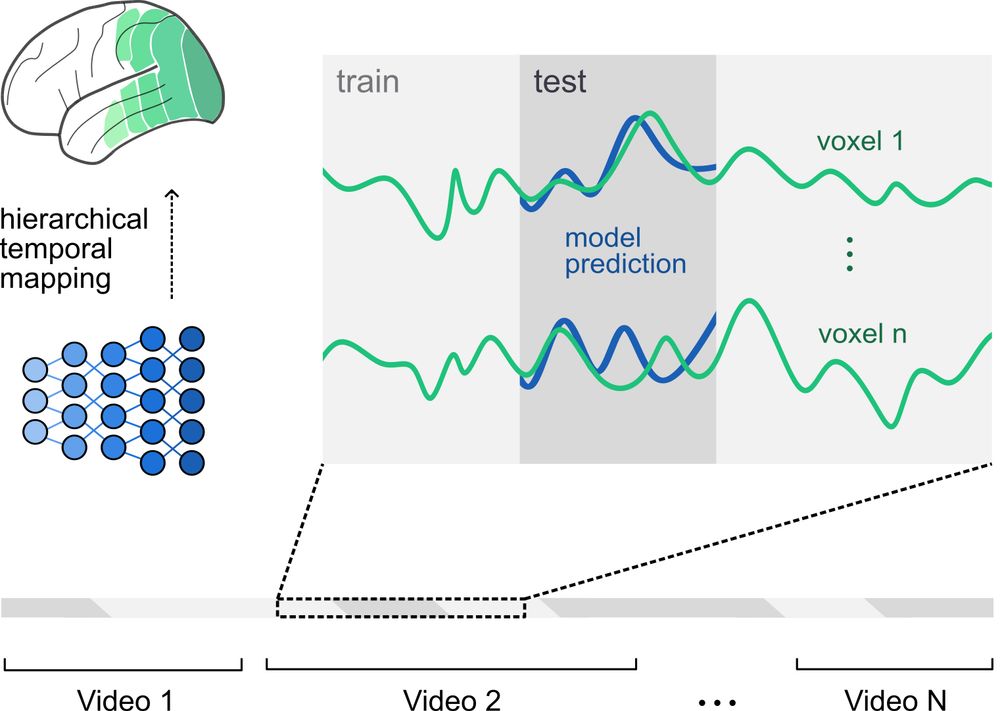
July 30, 2025 at 1:34 PM
2/🧪 Approach
We benchmarked diverse video models, each with a different pretraining objective.
Then: tested how well they predict human fMRI responses to natural movies.
🧠 ~10,000 voxels, whole visual system.
We benchmarked diverse video models, each with a different pretraining objective.
Then: tested how well they predict human fMRI responses to natural movies.
🧠 ~10,000 voxels, whole visual system.
1/🔍 Motivation
The brain is thought to process vision through two streams:
🖼 Ventral — objects, form, identity
🧭 Dorsal — motion, spatial layout, actions
Image models explain ventral well. But: what about dorsal? Can one model do both?
The brain is thought to process vision through two streams:
🖼 Ventral — objects, form, identity
🧭 Dorsal — motion, spatial layout, actions
Image models explain ventral well. But: what about dorsal? Can one model do both?
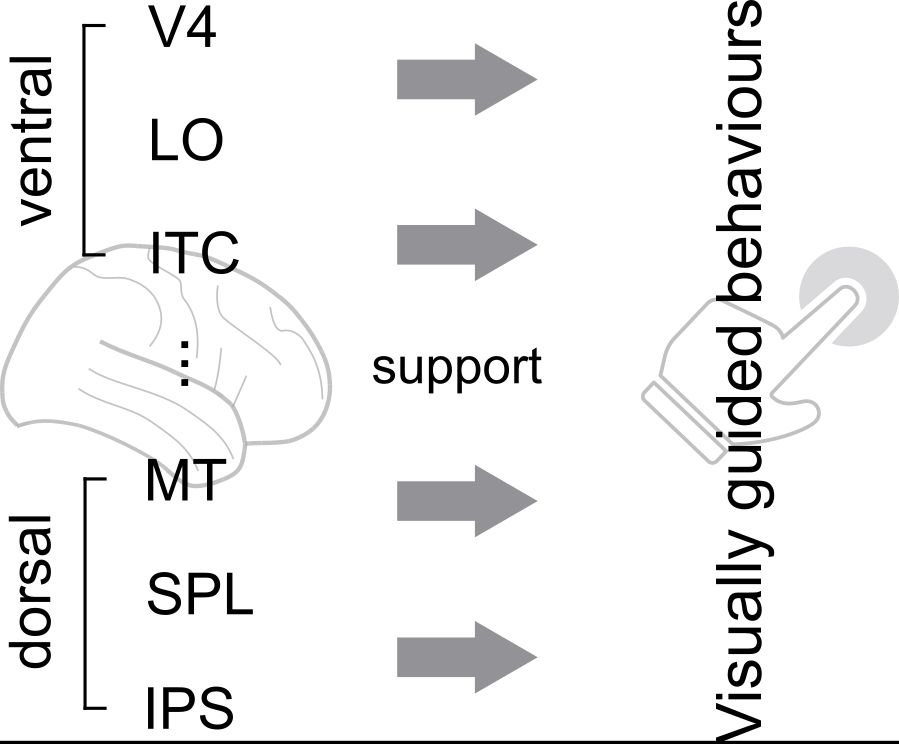
July 30, 2025 at 1:33 PM
1/🔍 Motivation
The brain is thought to process vision through two streams:
🖼 Ventral — objects, form, identity
🧭 Dorsal — motion, spatial layout, actions
Image models explain ventral well. But: what about dorsal? Can one model do both?
The brain is thought to process vision through two streams:
🖼 Ventral — objects, form, identity
🧭 Dorsal — motion, spatial layout, actions
Image models explain ventral well. But: what about dorsal? Can one model do both?