


David Schlangen
@davidschlangen.bsky.social
Prof of Computational Linguistics / NLP @ Uni Potsdam, Germany. Working on embodied / multimodal / conversational AI. In a way. Also affiliated w/ DFKI Berlin (German Research Center for AI).
(That animation in the first post? That's claude trying, and failing, to fully explore a maze in the MapWorld game.)
July 20, 2025 at 11:21 AM
(That animation in the first post? That's claude trying, and failing, to fully explore a maze in the MapWorld game.)
We'd love for other people to use it to test the interaction / agentic abilities of their models, and/or to build new fun and challenging games / interactions!
github.com/clp-research...
github.com/clp-research...
»
github.com/clp-research...
github.com/clp-research...
»

GitHub - clp-research/clembench: Collection of games to be run with the clemcore framework
Collection of games to be run with the clemcore framework - clp-research/clembench
github.com
July 20, 2025 at 11:21 AM
We'd love for other people to use it to test the interaction / agentic abilities of their models, and/or to build new fun and challenging games / interactions!
github.com/clp-research...
github.com/clp-research...
»
github.com/clp-research...
github.com/clp-research...
»
Thanks to a recent short-term grant, we've been able to focus on code quality and ease of use for benchmarking and extensibility. (Exploring new games is a fun programming lab activity, which we've run several times by now!) Here's a writeup of the current state: arxiv.org/abs/2507.08491
»
»

A Third Paradigm for LLM Evaluation: Dialogue Game-Based Evaluation using clembench
There are currently two main paradigms for evaluating large language models (LLMs), reference-based evaluation and preference-based evaluation. The first, carried over from the evaluation of machine l...
arxiv.org
July 20, 2025 at 11:21 AM
Thanks to a recent short-term grant, we've been able to focus on code quality and ease of use for benchmarking and extensibility. (Exploring new games is a fun programming lab activity, which we've run several times by now!) Here's a writeup of the current state: arxiv.org/abs/2507.08491
»
»
clembench now spans abstract (e.g., wordle) and concrete tasks (simulated household); language and l+vision; and benchmarking, learning (playpen), and user simulation (clem:todd).
arxiv.org/abs/2504.08590
arxiv.org/abs/2505.05445
»
arxiv.org/abs/2504.08590
arxiv.org/abs/2505.05445
»
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Interaction between learner and feedback-giver has come into focus recently for post-training of Large Language Models (LLMs), through the use of reward models that judge the appropriateness of a mode...
arxiv.org
July 20, 2025 at 11:21 AM
clembench now spans abstract (e.g., wordle) and concrete tasks (simulated household); language and l+vision; and benchmarking, learning (playpen), and user simulation (clem:todd).
arxiv.org/abs/2504.08590
arxiv.org/abs/2505.05445
»
arxiv.org/abs/2504.08590
arxiv.org/abs/2505.05445
»
Reposted by David Schlangen

📄 [ACL 2025 main] LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks (doi.org/10.48550/arX...)
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
There is an increasing trend towards evaluating NLP models with LLMs instead of human judgments, raising questions about the validity of these evaluations, as well as their reproducibility in the case...
doi.org
July 18, 2025 at 10:19 AM
📄 [ACL 2025 main] LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks (doi.org/10.48550/arX...)
Ha, yes, I'm quite pleased as well with how that turned out. It's nothing fancy, just a nice font, colouring (obviously), fbox, and rotate.
May 30, 2025 at 10:42 AM
Ha, yes, I'm quite pleased as well with how that turned out. It's nothing fancy, just a nice font, colouring (obviously), fbox, and rotate.

Oh yes, here's the link to the actual pre-print: arxiv.org/abs/2504.08590
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Interaction between learner and feedback-giver has come into focus recently for post-training of Large Language Models (LLMs), through the use of reward models that judge the appropriateness of a mode...
arxiv.org
May 29, 2025 at 8:41 PM
Oh yes, here's the link to the actual pre-print: arxiv.org/abs/2504.08590
We release the framework and the baseline training setups to foster research in the promising new direction of learning in (synthetic) interaction which we believe will provide more effective ways of post-training agentic conversational LLMs. github.com/lm-playpen/p...
GitHub - lm-playpen/playpen: All you need to get started with the LM Playpen Environment for Learning in Interaction.
All you need to get started with the LM Playpen Environment for Learning in Interaction. - lm-playpen/playpen
github.com
May 29, 2025 at 8:41 PM
We release the framework and the baseline training setups to foster research in the promising new direction of learning in (synthetic) interaction which we believe will provide more effective ways of post-training agentic conversational LLMs. github.com/lm-playpen/p...
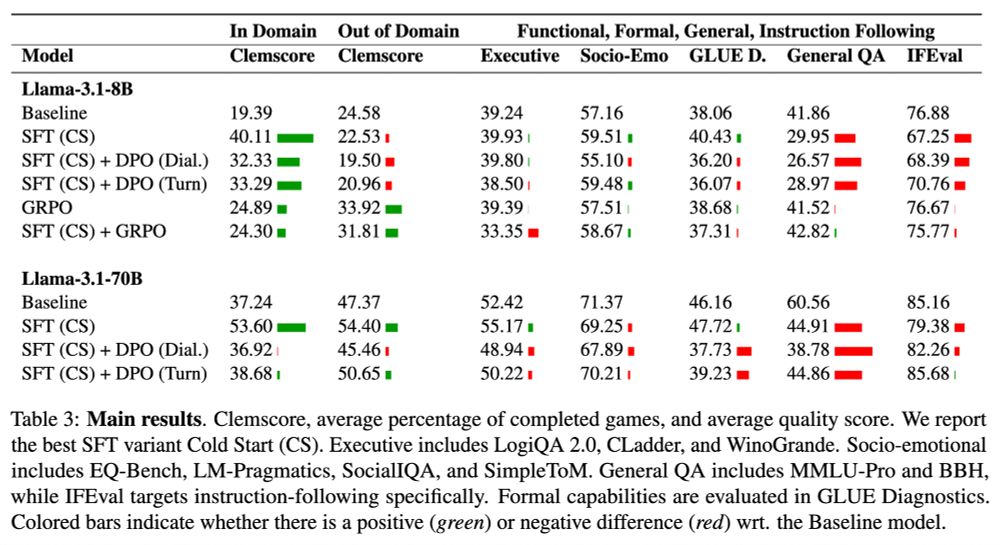
We find that imitation learning through SFT improves performance on unseen game instances, but does not generalise to new games and negatively impacts other skills -- while interactive learning with GRPO shows balanced improvements without loss of skills.
May 29, 2025 at 8:41 PM
We find that imitation learning through SFT improves performance on unseen game instances, but does not generalise to new games and negatively impacts other skills -- while interactive learning with GRPO shows balanced improvements without loss of skills.
Together with the learning environment, we also define an experimental setup combining gameplay evaluation on unseen games and traditional NLP benchmarks such as MMLU following (Momente’ et al. 2025) arxiv.org/abs/2502.14359
Triangulating LLM Progress through Benchmarks, Games, and Cognitive Tests
We examine three evaluation paradigms: standard benchmarks (e.g., MMLU and BBH), interactive games (e.g., Signalling Games or Taboo), and cognitive tests (e.g., for working memory or theory of mind). ...
arxiv.org
May 29, 2025 at 8:41 PM
Together with the learning environment, we also define an experimental setup combining gameplay evaluation on unseen games and traditional NLP benchmarks such as MMLU following (Momente’ et al. 2025) arxiv.org/abs/2502.14359
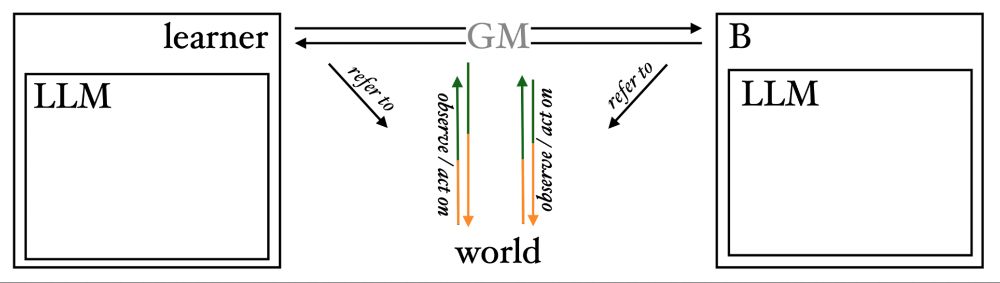
Playpen is a training environment for post-training LLMs through learning in interaction, by self-play of "dialogue games": goal-oriented language-based activities that generate verifiable rewards.
May 29, 2025 at 8:41 PM
Playpen is a training environment for post-training LLMs through learning in interaction, by self-play of "dialogue games": goal-oriented language-based activities that generate verifiable rewards.
[Sneak preview: If you're wondering where this is going, have a secret look at lm-playschool.github.io -- and stay tuned for more info!]
3/2
3/2
A Playschool for LLMs
lm-playschool.github.io
April 15, 2025 at 6:51 PM
[Sneak preview: If you're wondering where this is going, have a secret look at lm-playschool.github.io -- and stay tuned for more info!]
3/2
3/2
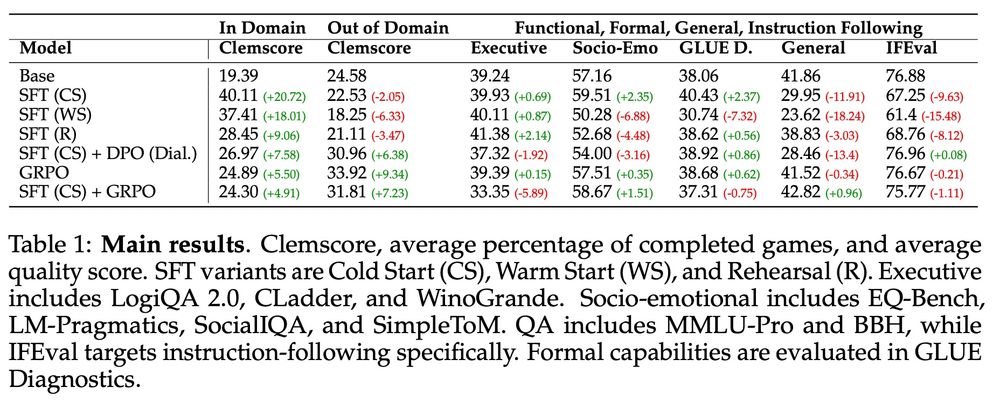
Nice baseline results as well: learning via SFT from transcripts does a bit, but only "real"(-ish) learning in interaction (GRPO) generalises. (Basically, you want to see the whole row being green in this table.)
2/2
2/2
April 15, 2025 at 6:51 PM
Nice baseline results as well: learning via SFT from transcripts does a bit, but only "real"(-ish) learning in interaction (GRPO) generalises. (Basically, you want to see the whole row being green in this table.)
2/2
2/2
This is only a subset of the models on the leaderboard, visit the site to see all 32 models, and also the results for the multimodal version of the benchmark.
April 15, 2025 at 6:37 PM
This is only a subset of the models on the leaderboard, visit the site to see all 32 models, and also the results for the multimodal version of the benchmark.