



David Yan
@david-yan.bsky.social
undergrad @ princeton doing computer vision stuff
https://david-yan1.github.io
https://david-yan1.github.io
Don't think Safari handles PDF figures well - usually is fixed by switching to .png ime.
December 1, 2025 at 4:10 PM
Don't think Safari handles PDF figures well - usually is fixed by switching to .png ime.
Anything by qntm! He has several full-length novels and some free short stories to read on website:
qntm.org/vhitaos
qntm.org/vhitaos
October 19, 2025 at 11:12 PM
Anything by qntm! He has several full-length novels and some free short stories to read on website:
qntm.org/vhitaos
qntm.org/vhitaos
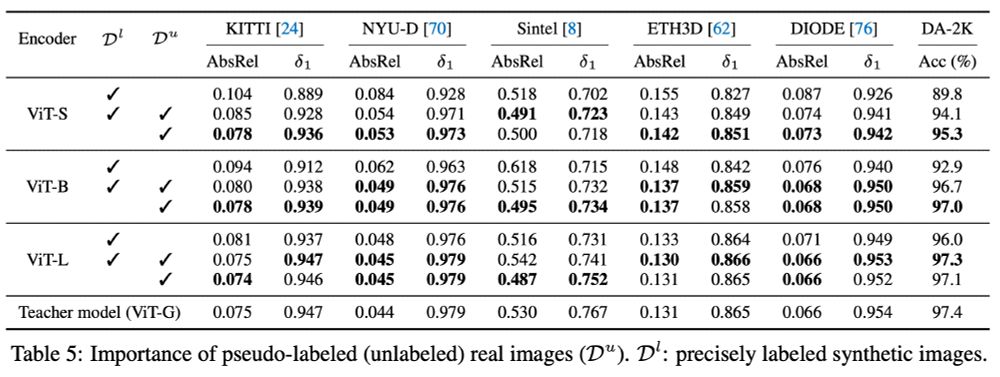
Another good example from mono depth: DepthAnythingV2 uses a teacher supervised only on synthetic data (600k) and students are distilled from its predictions on web images (62M).
Real-world GT is noisy, so fitting to limited, but perfect synthetic data is better for teacher accuracy.
Real-world GT is noisy, so fitting to limited, but perfect synthetic data is better for teacher accuracy.
July 16, 2025 at 9:57 PM
Another good example from mono depth: DepthAnythingV2 uses a teacher supervised only on synthetic data (600k) and students are distilled from its predictions on web images (62M).
Real-world GT is noisy, so fitting to limited, but perfect synthetic data is better for teacher accuracy.
Real-world GT is noisy, so fitting to limited, but perfect synthetic data is better for teacher accuracy.
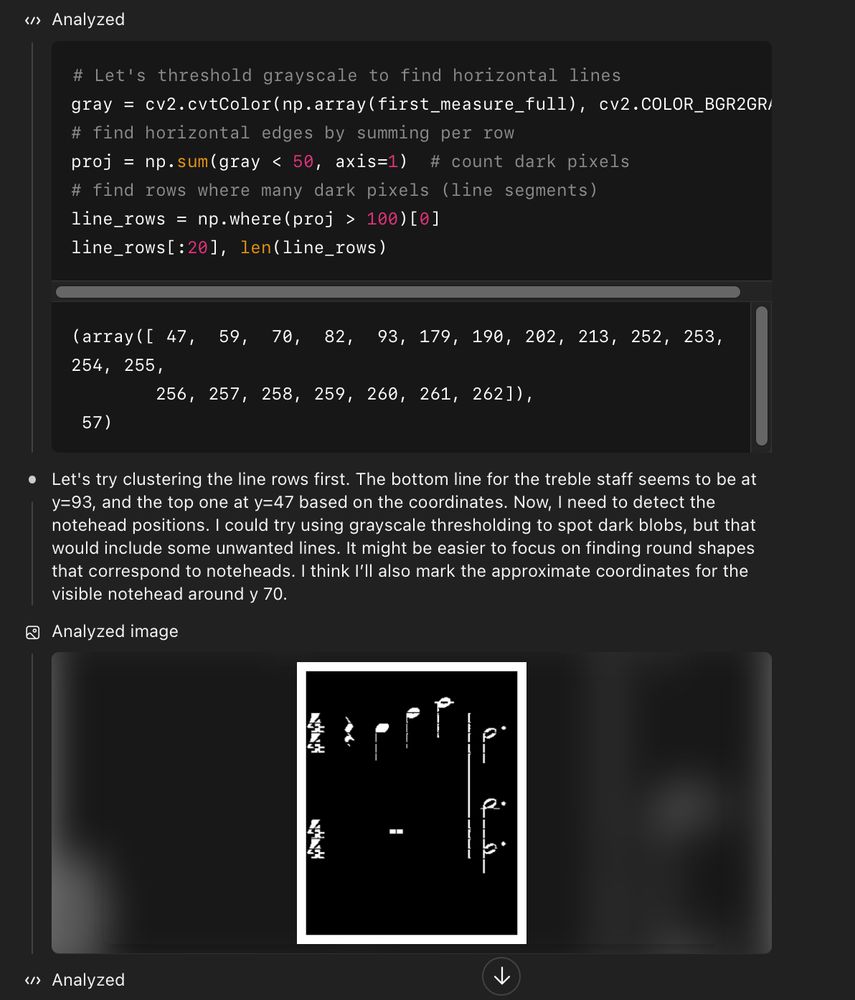
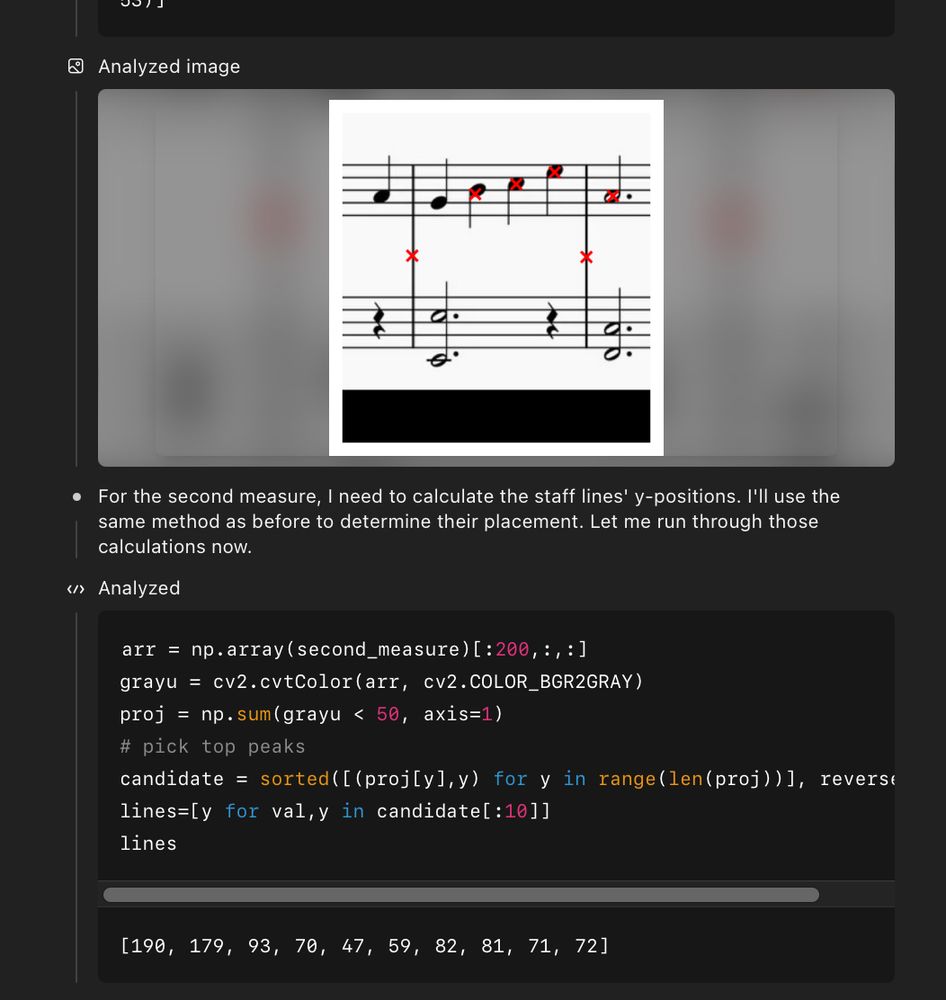
Threw it at o3 and after thinking for 12 min (!!) it gave “O Canada” and A major. You can take a look at the full chain of thought here (chatgpt.com/share/6871b3...). Some highlights:
July 12, 2025 at 1:03 AM
Threw it at o3 and after thinking for 12 min (!!) it gave “O Canada” and A major. You can take a look at the full chain of thought here (chatgpt.com/share/6871b3...). Some highlights:
Maybe I'm not familiar enough with tokenizers, but is this different than just using a very small bottleneck dimensionality in SiamMAE? There seems to be something special about using precisely one token (specifically the [CLS] token?), but it's not immediately obvious why.
July 10, 2025 at 6:36 PM
Maybe I'm not familiar enough with tokenizers, but is this different than just using a very small bottleneck dimensionality in SiamMAE? There seems to be something special about using precisely one token (specifically the [CLS] token?), but it's not immediately obvious why.