



@danielmisrael.bsky.social
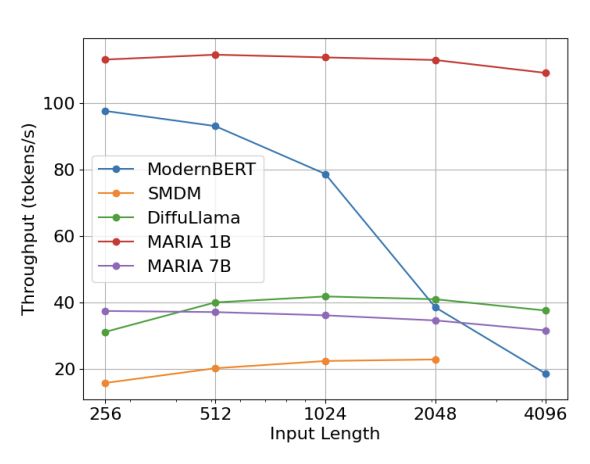
MARIA 1B achieves the best throughput numbers, and MARIA 7B achieves similar throughput to DiffuLlama, but better samples as previously noted. Here, we see that ModernBERT despite being much smaller does not scale well for masked infilling because it cannot KV cache.
February 14, 2025 at 12:28 AM
MARIA 1B achieves the best throughput numbers, and MARIA 7B achieves similar throughput to DiffuLlama, but better samples as previously noted. Here, we see that ModernBERT despite being much smaller does not scale well for masked infilling because it cannot KV cache.
We perform infilling on downstream data with words masked 50 percent. Using GPT4o-mini as a judge we compute the ELO scores for each model respectively. MARIA 7B and 1B have the highest rating ELO rating under the Bradley-Terry model.

February 14, 2025 at 12:28 AM
We perform infilling on downstream data with words masked 50 percent. Using GPT4o-mini as a judge we compute the ELO scores for each model respectively. MARIA 7B and 1B have the highest rating ELO rating under the Bradley-Terry model.
MARIA achieves far better perplexity than just using ModernBERT autoregressively and discrete diffusion models on downstream masked infilling test sets. Based on parameter counts, MARIA presents the most effective way to scale models for masked token infilling.

February 14, 2025 at 12:28 AM
MARIA achieves far better perplexity than just using ModernBERT autoregressively and discrete diffusion models on downstream masked infilling test sets. Based on parameter counts, MARIA presents the most effective way to scale models for masked token infilling.
We can get the best of both worlds with MARIA: train a linear decoder to combine the hidden states of an AR and MLM model. This enables AR masked infilling with the advantages of a more scalable AR architecture, such as KV cached inference. We combine OLMo and ModernBERT.

February 14, 2025 at 12:28 AM
We can get the best of both worlds with MARIA: train a linear decoder to combine the hidden states of an AR and MLM model. This enables AR masked infilling with the advantages of a more scalable AR architecture, such as KV cached inference. We combine OLMo and ModernBERT.
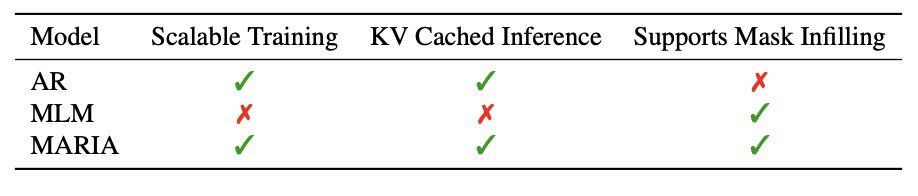
Autoregressive (AR) LMs are more compute efficient to train than Masked LMs (MLM), which compute a loss on some fixed ratio e.g. 30% of the tokens instead of 100% like AR. Unlike MLM, AR models can also KV cache at inference time, but they cannot infill masked tokens.
February 14, 2025 at 12:28 AM
Autoregressive (AR) LMs are more compute efficient to train than Masked LMs (MLM), which compute a loss on some fixed ratio e.g. 30% of the tokens instead of 100% like AR. Unlike MLM, AR models can also KV cache at inference time, but they cannot infill masked tokens.
“That’s one small [MASK] for [MASK], a giant [MASK] for mankind.” – [MASK] Armstrong
Can autoregressive models predict the next [MASK]? It turns out yes, and quite easily…
Introducing MARIA (Masked and Autoregressive Infilling Architecture)
arxiv.org/abs/2502.06901
Can autoregressive models predict the next [MASK]? It turns out yes, and quite easily…
Introducing MARIA (Masked and Autoregressive Infilling Architecture)
arxiv.org/abs/2502.06901
February 14, 2025 at 12:28 AM
“That’s one small [MASK] for [MASK], a giant [MASK] for mankind.” – [MASK] Armstrong
Can autoregressive models predict the next [MASK]? It turns out yes, and quite easily…
Introducing MARIA (Masked and Autoregressive Infilling Architecture)
arxiv.org/abs/2502.06901
Can autoregressive models predict the next [MASK]? It turns out yes, and quite easily…
Introducing MARIA (Masked and Autoregressive Infilling Architecture)
arxiv.org/abs/2502.06901