



Charlie Pugh
@cwjpugh.bsky.social
PhD candidate - Machine Learning and Genomics @CRG.eu with @jonnyfrazer.bsky.social and @MafaldaFigDias
We also made some improvements with genomic language model, Evo 2, but in this case the interpretation was less clear. See the preprint for more details. Code for using LFB will made available shortly. 10/10
May 26, 2025 at 5:30 PM
We also made some improvements with genomic language model, Evo 2, but in this case the interpretation was less clear. See the preprint for more details. Code for using LFB will made available shortly. 10/10
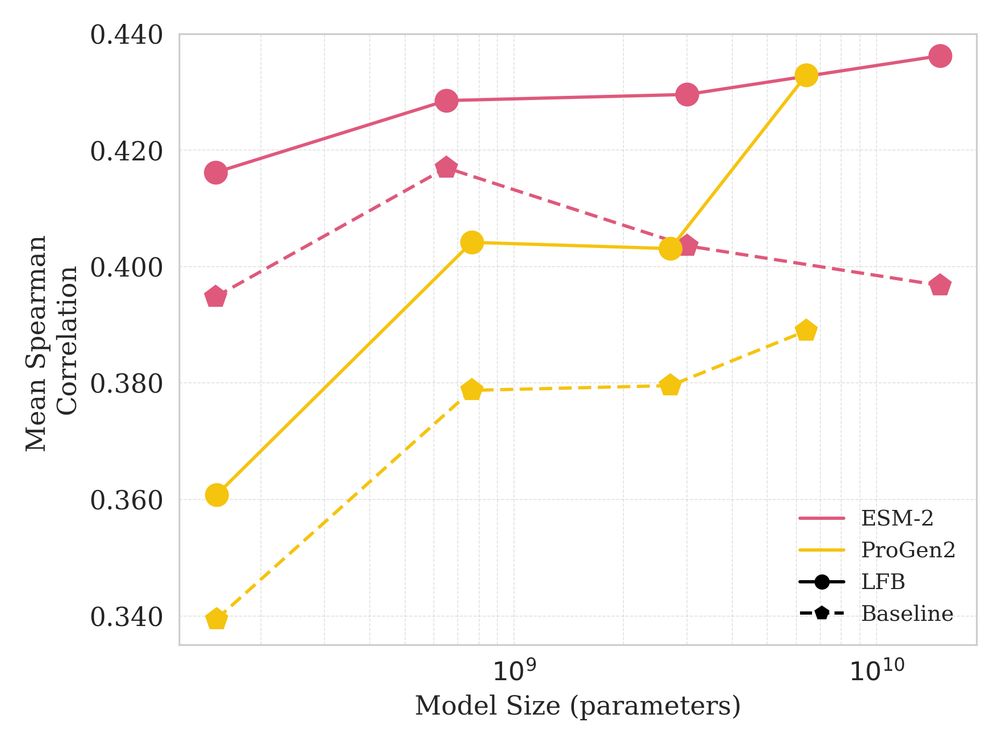
This provides evidence that better fitness estimation can be achieved at negligible computational cost by bridging the gap between likelihood and fitness at inference time. 9/n
May 26, 2025 at 5:30 PM
This provides evidence that better fitness estimation can be achieved at negligible computational cost by bridging the gap between likelihood and fitness at inference time. 9/n
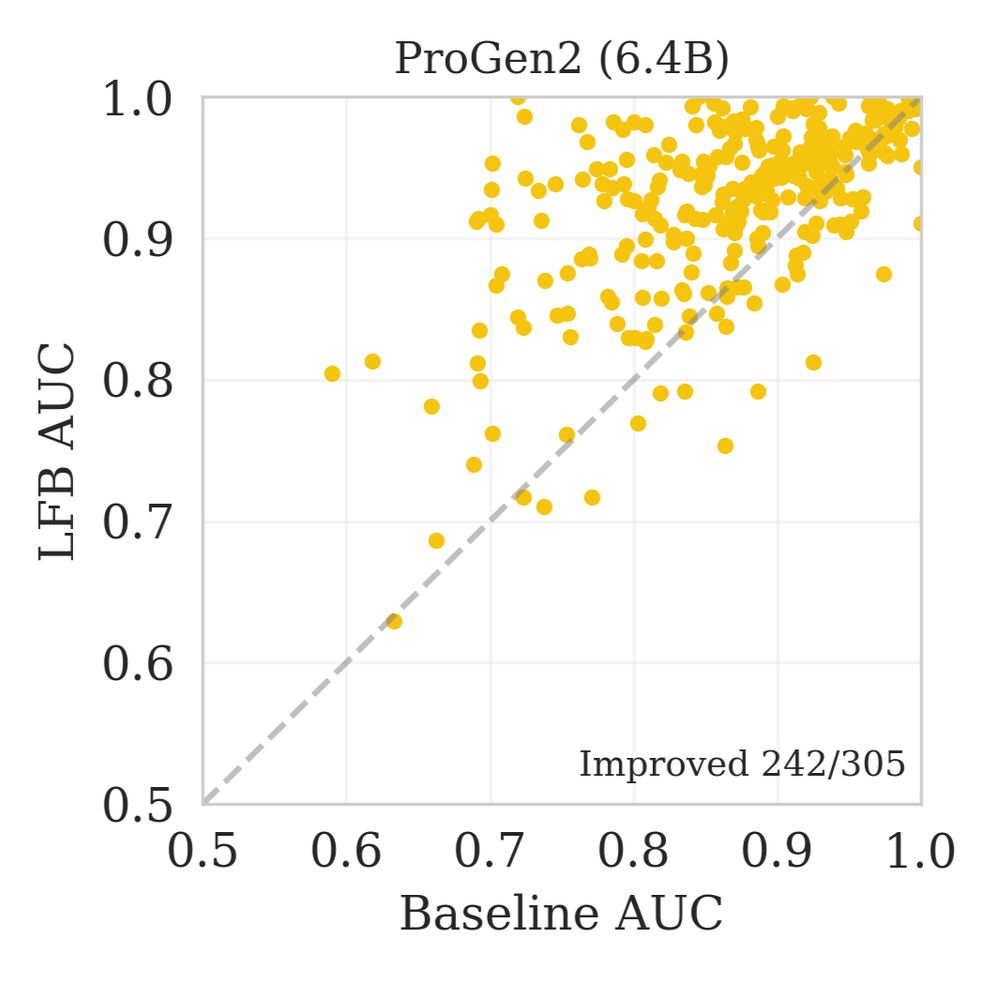
This trend held across DMS assay types and mutational depth, and also on prediction of clinical variants. 8/n
May 26, 2025 at 5:30 PM
This trend held across DMS assay types and mutational depth, and also on prediction of clinical variants. 8/n
On ProteinGym, LFB provided significant improvements across model classes and sizes and we saw that larger better fit models provided better predictions in general.
proteingym.org 7/n
proteingym.org 7/n
May 26, 2025 at 5:30 PM
On ProteinGym, LFB provided significant improvements across model classes and sizes and we saw that larger better fit models provided better predictions in general.
proteingym.org 7/n
proteingym.org 7/n
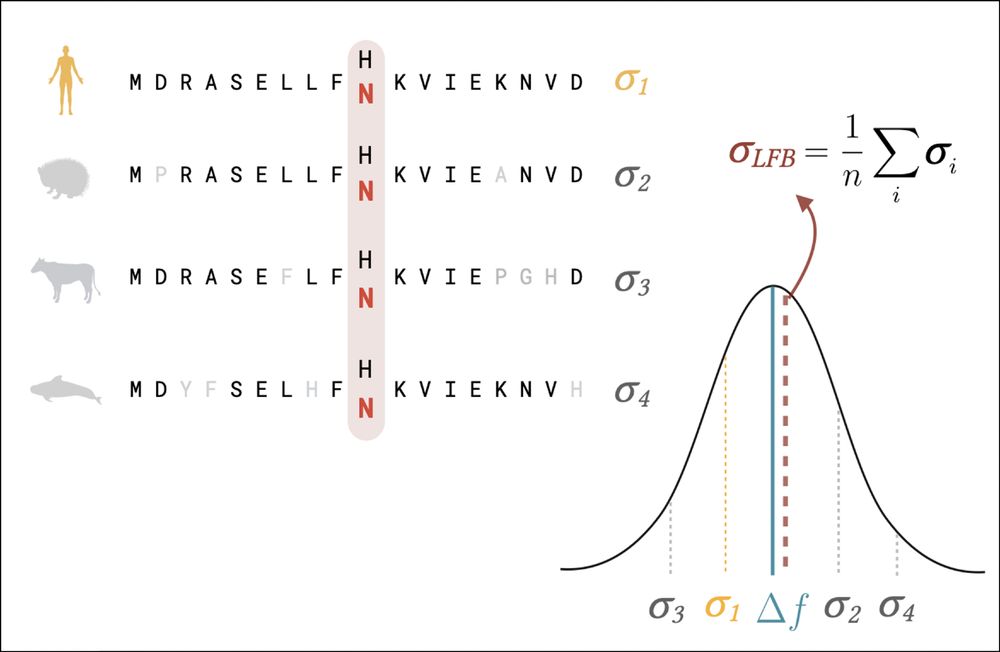
We found under an Ornstein–Uhlenbeck model of evolution that our LFB should be lower variance than the standard estimate by marginalising the effect of drift. 6/n
May 26, 2025 at 5:30 PM
We found under an Ornstein–Uhlenbeck model of evolution that our LFB should be lower variance than the standard estimate by marginalising the effect of drift. 6/n
We tried a simple strategy — averaging predictions over sequences under similar selective pressures to effectively reduce the impact of unwanted non-fitness related correlations — likelihood fitness bridging (LFB). 5/n
May 26, 2025 at 5:30 PM
We tried a simple strategy — averaging predictions over sequences under similar selective pressures to effectively reduce the impact of unwanted non-fitness related correlations — likelihood fitness bridging (LFB). 5/n
We wondered whether we might be able to improve predictions from existing models without any further training. 4/n
May 26, 2025 at 5:30 PM
We wondered whether we might be able to improve predictions from existing models without any further training. 4/n
Weinstein et al show that better fit sequence models can perform worse at fitness estimation due to phylogenetic structure:
openreview.net/forum?id=CwG...
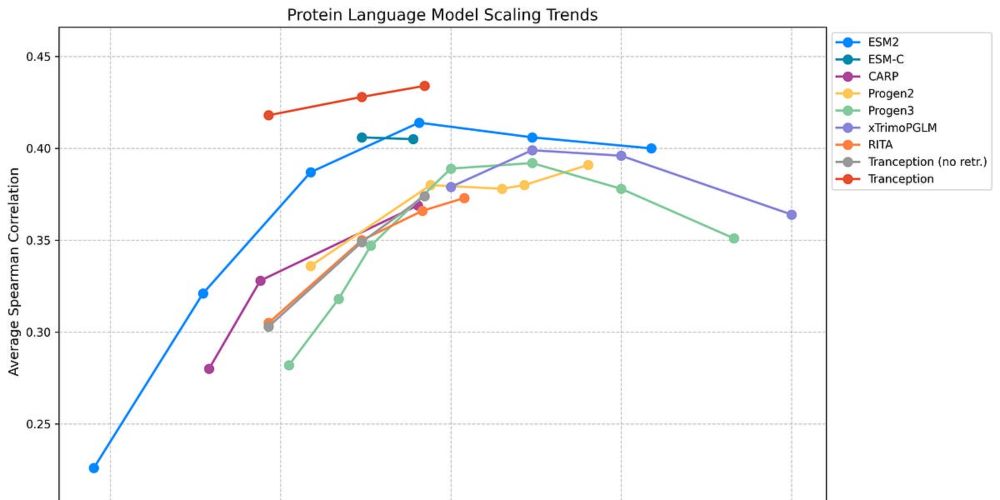
And in practice we are seeing that pLMs don’t improve with lower perplexities:
openreview.net/forum?id=UvP... www.biorxiv.org/content/10.1... 3/n
openreview.net/forum?id=CwG...
And in practice we are seeing that pLMs don’t improve with lower perplexities:
openreview.net/forum?id=UvP... www.biorxiv.org/content/10.1... 3/n
Non-identifiability and the Blessings of Misspecification in Models...
Misspecification is a blessing, not a curse, when estimating protein fitness from evolutionary sequence data using generative models.
openreview.net
May 26, 2025 at 5:30 PM
Weinstein et al show that better fit sequence models can perform worse at fitness estimation due to phylogenetic structure:
openreview.net/forum?id=CwG...
And in practice we are seeing that pLMs don’t improve with lower perplexities:
openreview.net/forum?id=UvP... www.biorxiv.org/content/10.1... 3/n
openreview.net/forum?id=CwG...
And in practice we are seeing that pLMs don’t improve with lower perplexities:
openreview.net/forum?id=UvP... www.biorxiv.org/content/10.1... 3/n
Protein language models are showing promise in variant effect prediction - but there’s emerging evidence likelihood based zero shot fitness estimation is breaking down. See this excellent summary from @pascalnotin.bsky.social: pascalnotin.substack.com/p/have-we-hi... 2/n
Have We Hit the Scaling Wall for Protein Language Models?
Beyond Scaling: What Truly Works in Protein Fitness Prediction
pascalnotin.substack.com
May 26, 2025 at 5:30 PM
Protein language models are showing promise in variant effect prediction - but there’s emerging evidence likelihood based zero shot fitness estimation is breaking down. See this excellent summary from @pascalnotin.bsky.social: pascalnotin.substack.com/p/have-we-hi... 2/n