



Computational Linguistics Journal
@complingjournal.bsky.social
http://cljournal.org
Computational Linguistics, established in 1974, is the official flagship journal of the Association for Computational Linguistics (ACL).
Computational Linguistics, established in 1974, is the official flagship journal of the Association for Computational Linguistics (ACL).
Do LLMs have personalities?
This paper introduces LMLPA, a framework for assessing linguistic personalities of LLMs using adapted Big Five inventories + AI raters, validated for reliability and consistency.
📄 Read in Computational Linguistics: direct.mit.edu/coli/article...
This paper introduces LMLPA, a framework for assessing linguistic personalities of LLMs using adapted Big Five inventories + AI raters, validated for reliability and consistency.
📄 Read in Computational Linguistics: direct.mit.edu/coli/article...

September 1, 2025 at 12:08 PM
Do LLMs have personalities?
This paper introduces LMLPA, a framework for assessing linguistic personalities of LLMs using adapted Big Five inventories + AI raters, validated for reliability and consistency.
📄 Read in Computational Linguistics: direct.mit.edu/coli/article...
This paper introduces LMLPA, a framework for assessing linguistic personalities of LLMs using adapted Big Five inventories + AI raters, validated for reliability and consistency.
📄 Read in Computational Linguistics: direct.mit.edu/coli/article...
Evaluating NLG remains challenging — even with LLMs.
This survey reviews LLM-based evaluation methods: prompting, fine-tuning, and human–LLM collaboration, and outlines key open problems.
📄 Read in Computational Linguistics: direct.mit.edu/coli/article...
This survey reviews LLM-based evaluation methods: prompting, fine-tuning, and human–LLM collaboration, and outlines key open problems.
📄 Read in Computational Linguistics: direct.mit.edu/coli/article...

August 18, 2025 at 10:34 AM
Evaluating NLG remains challenging — even with LLMs.
This survey reviews LLM-based evaluation methods: prompting, fine-tuning, and human–LLM collaboration, and outlines key open problems.
📄 Read in Computational Linguistics: direct.mit.edu/coli/article...
This survey reviews LLM-based evaluation methods: prompting, fine-tuning, and human–LLM collaboration, and outlines key open problems.
📄 Read in Computational Linguistics: direct.mit.edu/coli/article...
LLMs can generate fluent text — but can they twist your tongue?
TwisterLister generates phoneme-aware tongue twisters, with a 17k-example dataset and phonologically constrained decoding.
📄 Read the paper in Computational Linguistics: direct.mit.edu/coli/article...
TwisterLister generates phoneme-aware tongue twisters, with a 17k-example dataset and phonologically constrained decoding.
📄 Read the paper in Computational Linguistics: direct.mit.edu/coli/article...

August 14, 2025 at 10:33 AM
LLMs can generate fluent text — but can they twist your tongue?
TwisterLister generates phoneme-aware tongue twisters, with a 17k-example dataset and phonologically constrained decoding.
📄 Read the paper in Computational Linguistics: direct.mit.edu/coli/article...
TwisterLister generates phoneme-aware tongue twisters, with a 17k-example dataset and phonologically constrained decoding.
📄 Read the paper in Computational Linguistics: direct.mit.edu/coli/article...
Can LLMs learn possible human languages but struggle with impossible ones?
Kallini et al. claimed evidence, but Hunter argues their key experiment conflates factors — the core question remains open.
📄 Read the article in Computational Linguistics: direct.mit.edu/coli/article...
Kallini et al. claimed evidence, but Hunter argues their key experiment conflates factors — the core question remains open.
📄 Read the article in Computational Linguistics: direct.mit.edu/coli/article...

August 10, 2025 at 1:39 PM
Can LLMs learn possible human languages but struggle with impossible ones?
Kallini et al. claimed evidence, but Hunter argues their key experiment conflates factors — the core question remains open.
📄 Read the article in Computational Linguistics: direct.mit.edu/coli/article...
Kallini et al. claimed evidence, but Hunter argues their key experiment conflates factors — the core question remains open.
📄 Read the article in Computational Linguistics: direct.mit.edu/coli/article...
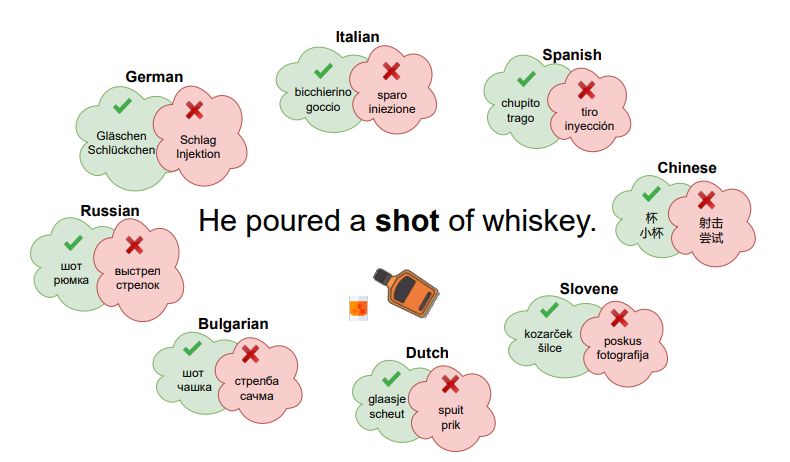
Even state-of-the-art MT systems struggle with ambiguous words — especially rare senses.
DiBiMT is a new fully human-curated benchmark across 8 language pairs to study disambiguation bias in MT.
📄 Read the paper in Computational Linguistics: direct.mit.edu/coli/article...
DiBiMT is a new fully human-curated benchmark across 8 language pairs to study disambiguation bias in MT.
📄 Read the paper in Computational Linguistics: direct.mit.edu/coli/article...
August 3, 2025 at 11:57 AM
Even state-of-the-art MT systems struggle with ambiguous words — especially rare senses.
DiBiMT is a new fully human-curated benchmark across 8 language pairs to study disambiguation bias in MT.
📄 Read the paper in Computational Linguistics: direct.mit.edu/coli/article...
DiBiMT is a new fully human-curated benchmark across 8 language pairs to study disambiguation bias in MT.
📄 Read the paper in Computational Linguistics: direct.mit.edu/coli/article...
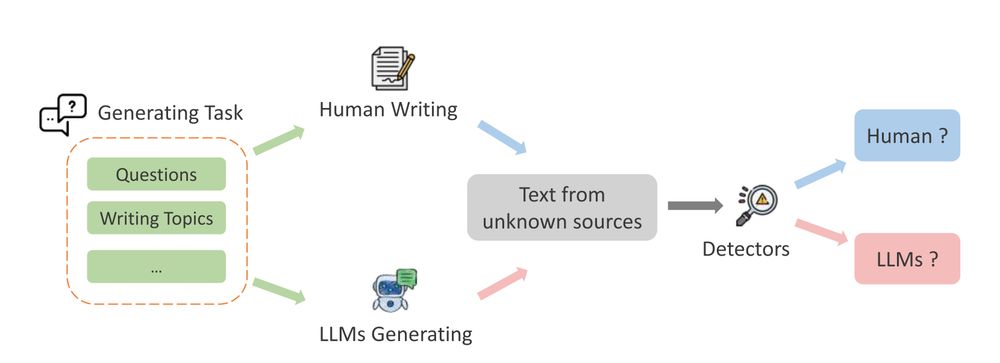
🚨 As LLMs generate more of the text we see daily, detecting AI-generated text is more critical than ever.
New survey from the University of Macau explores cutting-edge detection methods, key challenges, and future directions to ensure responsible AI use.
Read: direct.mit.edu/coli/article...
New survey from the University of Macau explores cutting-edge detection methods, key challenges, and future directions to ensure responsible AI use.
Read: direct.mit.edu/coli/article...
June 26, 2025 at 7:22 AM
🚨 As LLMs generate more of the text we see daily, detecting AI-generated text is more critical than ever.
New survey from the University of Macau explores cutting-edge detection methods, key challenges, and future directions to ensure responsible AI use.
Read: direct.mit.edu/coli/article...
New survey from the University of Macau explores cutting-edge detection methods, key challenges, and future directions to ensure responsible AI use.
Read: direct.mit.edu/coli/article...
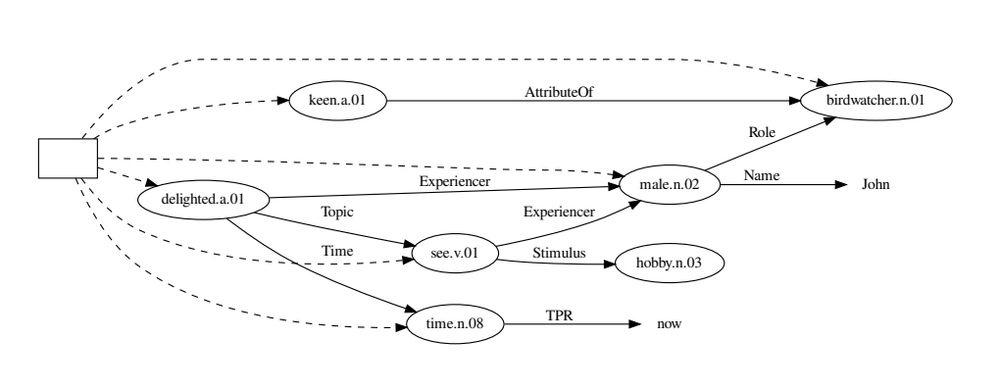
🔍 Neural semantic parsers are great – but often just parrot surface text.
Researchers from the University of Groningen propose a taxonomical parser that builds deeper, hierarchical meaning representations.
Read: direct.mit.edu/coli/article...
Researchers from the University of Groningen propose a taxonomical parser that builds deeper, hierarchical meaning representations.
Read: direct.mit.edu/coli/article...
June 22, 2025 at 11:58 AM
🔍 Neural semantic parsers are great – but often just parrot surface text.
Researchers from the University of Groningen propose a taxonomical parser that builds deeper, hierarchical meaning representations.
Read: direct.mit.edu/coli/article...
Researchers from the University of Groningen propose a taxonomical parser that builds deeper, hierarchical meaning representations.
Read: direct.mit.edu/coli/article...
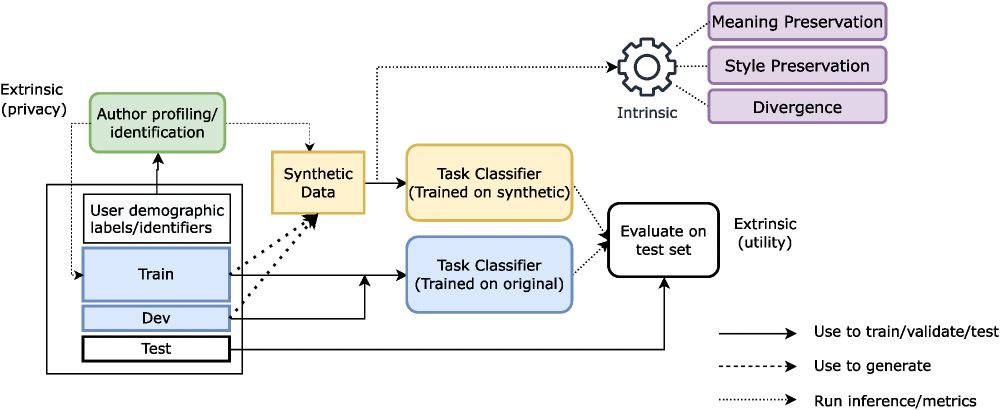
🚀 New from Queen Mary University of London: A unified framework for evaluating synthetic data generation from user-generated text! 📱💬
It tackles style, meaning, and privacy – paving the way for safe, shareable, high-quality synthetic language data.
Read: direct.mit.edu/coli/article...
It tackles style, meaning, and privacy – paving the way for safe, shareable, high-quality synthetic language data.
Read: direct.mit.edu/coli/article...
June 14, 2025 at 3:47 AM
🚀 New from Queen Mary University of London: A unified framework for evaluating synthetic data generation from user-generated text! 📱💬
It tackles style, meaning, and privacy – paving the way for safe, shareable, high-quality synthetic language data.
Read: direct.mit.edu/coli/article...
It tackles style, meaning, and privacy – paving the way for safe, shareable, high-quality synthetic language data.
Read: direct.mit.edu/coli/article...
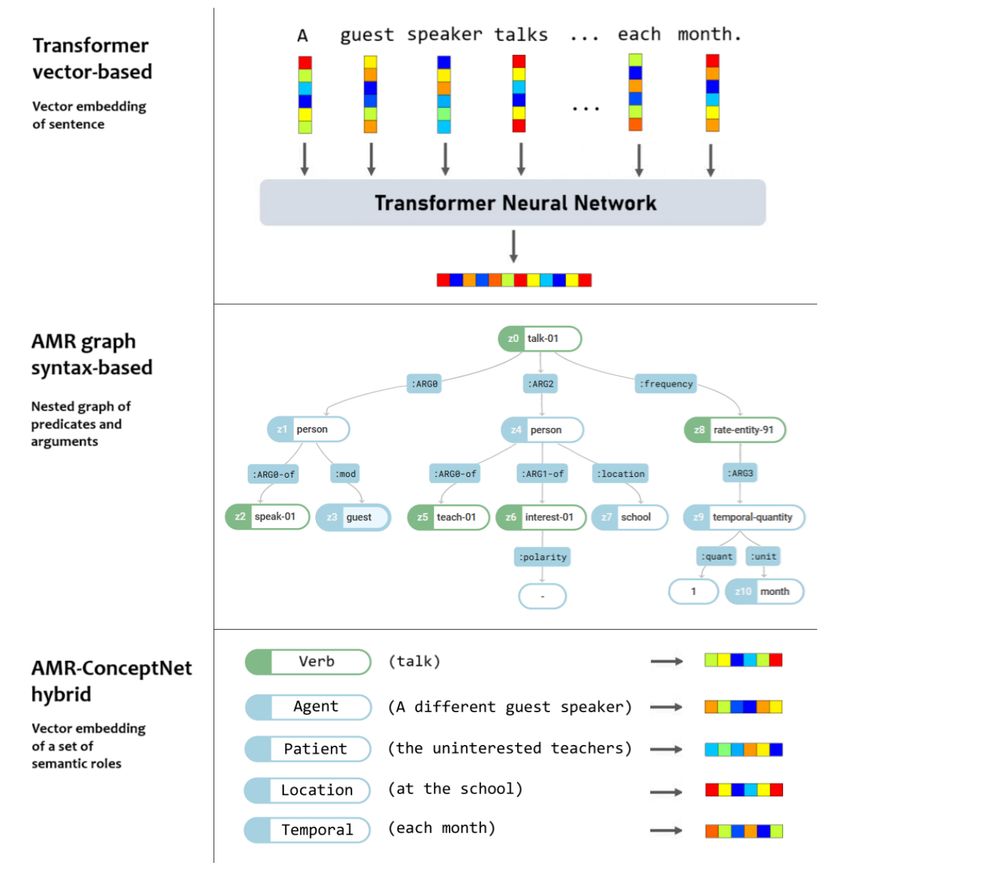
How do humans understand novel sentence meanings? A new dataset (STS3k) from UniMelb & Hitotsubashi researchers tests compositionality in language models. Findings: hybrids of syntax + vectors better match human judgments than top transformers.🧠📚
Read: direct.mit.edu/coli/article...
Read: direct.mit.edu/coli/article...
June 6, 2025 at 9:50 AM
How do humans understand novel sentence meanings? A new dataset (STS3k) from UniMelb & Hitotsubashi researchers tests compositionality in language models. Findings: hybrids of syntax + vectors better match human judgments than top transformers.🧠📚
Read: direct.mit.edu/coli/article...
Read: direct.mit.edu/coli/article...
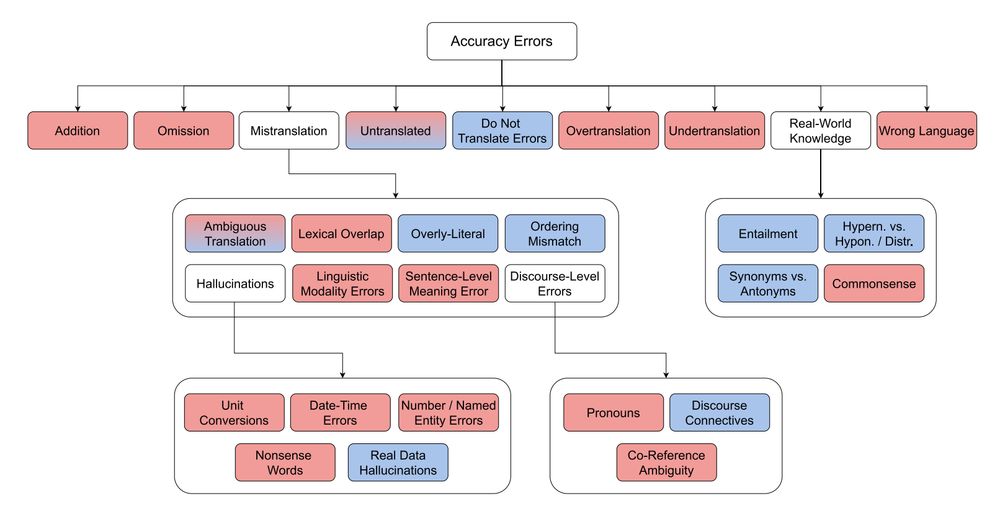
Researchers from the University of Edinburgh, the University of Zurich, Supertext, and Microsoft introduce ACES, a challenging benchmark spanning 146 language pairs, in their 'Machine Translation Meta Evaluation through Translation Accuracy Challenge Sets'.
Read: direct.mit.edu/coli/article...
Read: direct.mit.edu/coli/article...
May 30, 2025 at 9:41 AM
Researchers from the University of Edinburgh, the University of Zurich, Supertext, and Microsoft introduce ACES, a challenging benchmark spanning 146 language pairs, in their 'Machine Translation Meta Evaluation through Translation Accuracy Challenge Sets'.
Read: direct.mit.edu/coli/article...
Read: direct.mit.edu/coli/article...
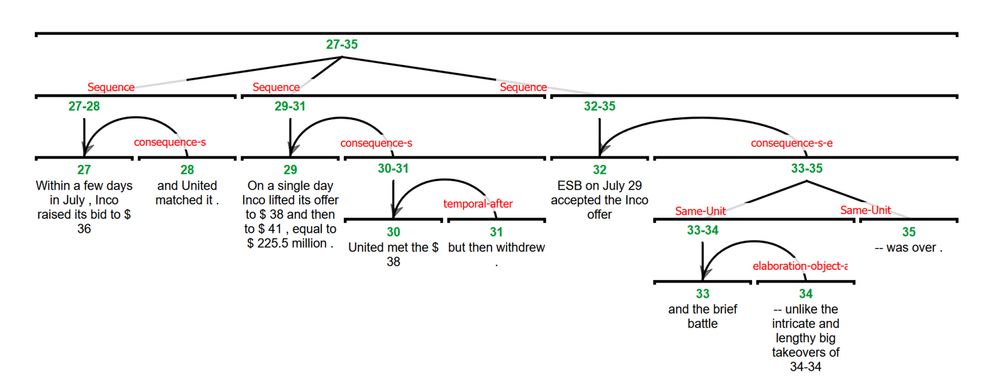
Researchers from Georgetown University, LMU Munich, Abo Akademi, and Indiana University present “eRST: A Signaled Graph Theory of Discourse Relations and Organization”.
Read: direct.mit.edu/coli/article...
Read: direct.mit.edu/coli/article...
May 25, 2025 at 4:03 AM
Researchers from Georgetown University, LMU Munich, Abo Akademi, and Indiana University present “eRST: A Signaled Graph Theory of Discourse Relations and Organization”.
Read: direct.mit.edu/coli/article...
Read: direct.mit.edu/coli/article...