


Christopher Manning
@chrmanning.bsky.social
Stanford Linguistics and Computer Science. Director, Stanford AI Lab. Founder of @stanfordnlp.bsky.social . #NLP https://nlp.stanford.edu/~manning/
Source: dl.acm.org/doi/10.1145/...
Of course, information context, provenance and accuracy are still vital, just as when looking at the underlying documents.
Also, factoid question answering as in this TREC-8 QA track was deployed earlier but LLMs gives us much more powerful QA.
Of course, information context, provenance and accuracy are still vital, just as when looking at the underlying documents.
Also, factoid question answering as in this TREC-8 QA track was deployed earlier but LLMs gives us much more powerful QA.

March 5, 2025 at 9:44 PM
Source: dl.acm.org/doi/10.1145/...
Of course, information context, provenance and accuracy are still vital, just as when looking at the underlying documents.
Also, factoid question answering as in this TREC-8 QA track was deployed earlier but LLMs gives us much more powerful QA.
Of course, information context, provenance and accuracy are still vital, just as when looking at the underlying documents.
Also, factoid question answering as in this TREC-8 QA track was deployed earlier but LLMs gives us much more powerful QA.
In 2013, at AKBC 2013 and other workshops, I gave a talk titled “Texts are Knowledge”. This was well before there were any transformer LLMs—indeed before the invention of attention—and my early neural NLP ideas were rudimentary.
🔮 Nevertheless, the talk was quite prophetic!
🔮 Nevertheless, the talk was quite prophetic!




March 3, 2025 at 10:46 PM
In 2013, at AKBC 2013 and other workshops, I gave a talk titled “Texts are Knowledge”. This was well before there were any transformer LLMs—indeed before the invention of attention—and my early neural NLP ideas were rudimentary.
🔮 Nevertheless, the talk was quite prophetic!
🔮 Nevertheless, the talk was quite prophetic!
But one error that I think was made throughout was too large “Phone Booth” rooms. Everywhere there could have been 3, there are 2 too large ones. Phone booths are occupied by 1 person on Zoom or 2 doing a 1:1. Not 3 or 4. Besides, for groups of 3–6, there are also many “Conversation” rooms.




March 1, 2025 at 6:15 PM
But one error that I think was made throughout was too large “Phone Booth” rooms. Everywhere there could have been 3, there are 2 too large ones. Phone booths are occupied by 1 person on Zoom or 2 doing a 1:1. Not 3 or 4. Besides, for groups of 3–6, there are also many “Conversation” rooms.
The new Computing and Data Science (CoDa) building at @stanforduniversity.bsky.social is beautiful, with many lovely spaces, and a great, if already too crowded, Voyager Coffee coffee shop.
news.stanford.edu/stories/2025...
news.stanford.edu/stories/2025...




March 1, 2025 at 6:15 PM
The new Computing and Data Science (CoDa) building at @stanforduniversity.bsky.social is beautiful, with many lovely spaces, and a great, if already too crowded, Voyager Coffee coffee shop.
news.stanford.edu/stories/2025...
news.stanford.edu/stories/2025...
How can it be that the Apple iOS data detector pop-up gives you options to call or copy but not text?
We’re not in the twentieth century any more. The twenty-first century is almost a quarter done.
We’re not in the twentieth century any more. The twenty-first century is almost a quarter done.
February 11, 2025 at 12:06 AM
How can it be that the Apple iOS data detector pop-up gives you options to call or copy but not text?
We’re not in the twentieth century any more. The twenty-first century is almost a quarter done.
We’re not in the twentieth century any more. The twenty-first century is almost a quarter done.
Papers at #EMNLP2024 #3
A counter-example to the frequently adopted mech interp linear representation hypothesis: Recurrent Neural Networks Learn … Non-Linear Representations
Fri Nov 15 BlackboxNLP 2024 poster
aclanthology.org/2024.blackbo...
A counter-example to the frequently adopted mech interp linear representation hypothesis: Recurrent Neural Networks Learn … Non-Linear Representations
Fri Nov 15 BlackboxNLP 2024 poster
aclanthology.org/2024.blackbo...



November 11, 2024 at 6:23 PM
Papers at #EMNLP2024 #3
A counter-example to the frequently adopted mech interp linear representation hypothesis: Recurrent Neural Networks Learn … Non-Linear Representations
Fri Nov 15 BlackboxNLP 2024 poster
aclanthology.org/2024.blackbo...
A counter-example to the frequently adopted mech interp linear representation hypothesis: Recurrent Neural Networks Learn … Non-Linear Representations
Fri Nov 15 BlackboxNLP 2024 poster
aclanthology.org/2024.blackbo...
Papers at #EMNLP2024 #2
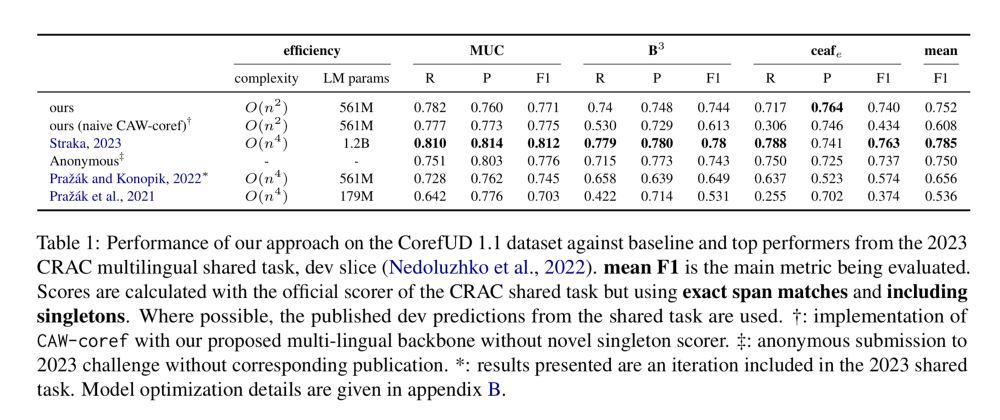
MSCAW-coref: Efficient and high performing coreference, extending CAW-coref multilingually and to singleton mentions.
Fri Nov 15 CRAC workshop 14:10-14:30
aclanthology.org/2024.crac-1.4
In Stanza: stanfordnlp.github.io/stanza/
MSCAW-coref: Efficient and high performing coreference, extending CAW-coref multilingually and to singleton mentions.
Fri Nov 15 CRAC workshop 14:10-14:30
aclanthology.org/2024.crac-1.4
In Stanza: stanfordnlp.github.io/stanza/
November 10, 2024 at 11:45 PM
Papers at #EMNLP2024 #2
MSCAW-coref: Efficient and high performing coreference, extending CAW-coref multilingually and to singleton mentions.
Fri Nov 15 CRAC workshop 14:10-14:30
aclanthology.org/2024.crac-1.4
In Stanza: stanfordnlp.github.io/stanza/
MSCAW-coref: Efficient and high performing coreference, extending CAW-coref multilingually and to singleton mentions.
Fri Nov 15 CRAC workshop 14:10-14:30
aclanthology.org/2024.crac-1.4
In Stanza: stanfordnlp.github.io/stanza/
Papers at #EMNLP2024 #1
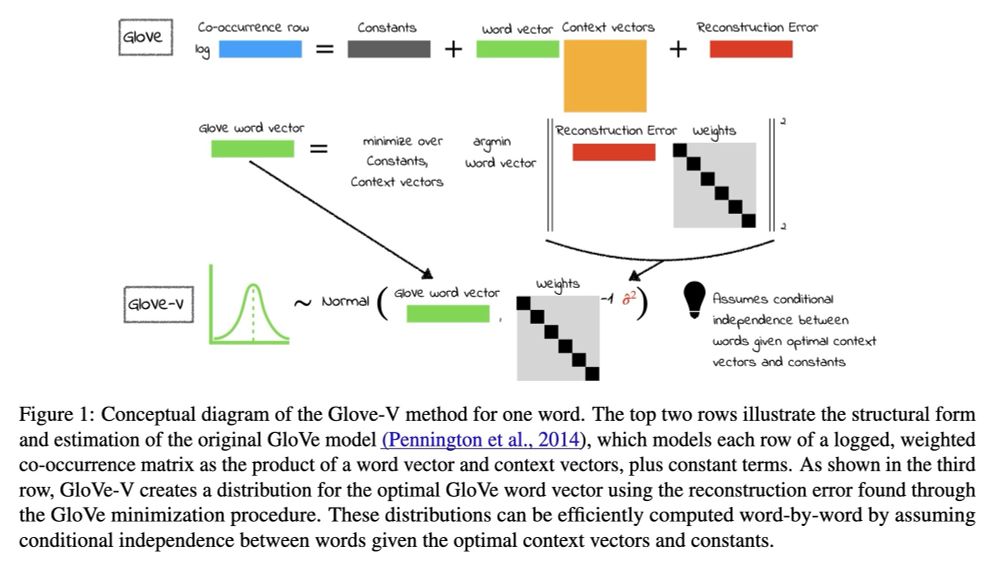
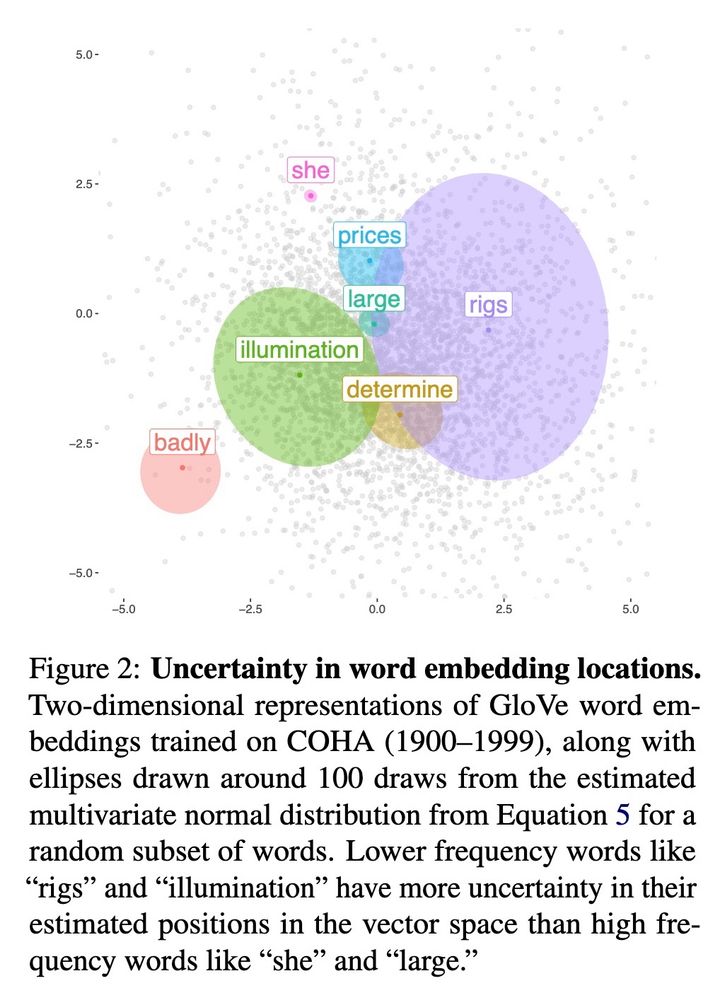
Statistical Uncertainty in Word Embeddings: GloVe-V
Neural models, from word vectors through transformers, use point estimate representations. They can have large variances, which often loom large in CSS applications.
Tue Nov 12 15:15-15:30 Flagler
Statistical Uncertainty in Word Embeddings: GloVe-V
Neural models, from word vectors through transformers, use point estimate representations. They can have large variances, which often loom large in CSS applications.
Tue Nov 12 15:15-15:30 Flagler
November 10, 2024 at 12:36 AM
Papers at #EMNLP2024 #1
Statistical Uncertainty in Word Embeddings: GloVe-V
Neural models, from word vectors through transformers, use point estimate representations. They can have large variances, which often loom large in CSS applications.
Tue Nov 12 15:15-15:30 Flagler
Statistical Uncertainty in Word Embeddings: GloVe-V
Neural models, from word vectors through transformers, use point estimate representations. They can have large variances, which often loom large in CSS applications.
Tue Nov 12 15:15-15:30 Flagler