




Reposted

Are there conceptual directions in VLMs that transcend modality? Check out our COLM oral spotlight 🔦 paper! We use SAEs to analyze the multimodality of linear concepts in VLMs
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695

September 17, 2025 at 7:12 PM
Are there conceptual directions in VLMs that transcend modality? Check out our COLM oral spotlight 🔦 paper! We use SAEs to analyze the multimodality of linear concepts in VLMs
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695
Reposted

New in the Deeper Learning blog: Kempner researchers show how VLMs speak the same semantic language across images and text.
bit.ly/KempnerVLM
by @isabelpapad.bsky.social ,Chloe Huangyuan Su, @thomasfel.bsky.social, Stephanie Gil, and @shamkakade.bsky.social
#AI #ML #VLMs #SAEs
bit.ly/KempnerVLM
by @isabelpapad.bsky.social ,Chloe Huangyuan Su, @thomasfel.bsky.social, Stephanie Gil, and @shamkakade.bsky.social
#AI #ML #VLMs #SAEs
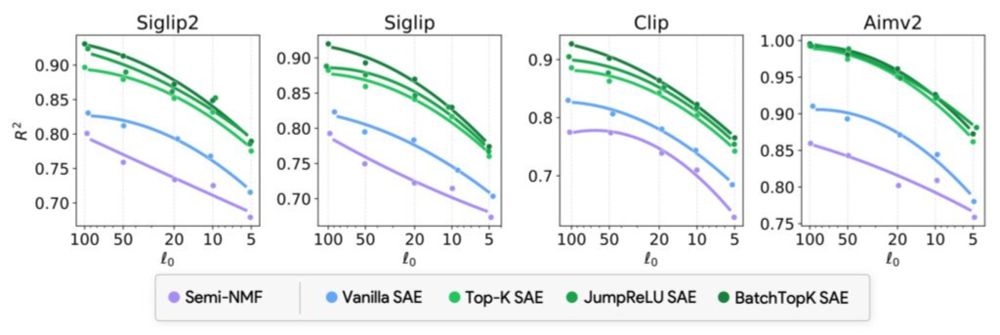
Interpreting the Linear Structure of Vision-Language Model Embedding Spaces - Kempner Institute
Using sparse autoencoders, the authors show that vision-language embeddings boil down to a small, stable dictionary of single-modality concepts that snap together into cross-modal bridges. This resear...
bit.ly
April 28, 2025 at 4:57 PM
New in the Deeper Learning blog: Kempner researchers show how VLMs speak the same semantic language across images and text.
bit.ly/KempnerVLM
by @isabelpapad.bsky.social ,Chloe Huangyuan Su, @thomasfel.bsky.social, Stephanie Gil, and @shamkakade.bsky.social
#AI #ML #VLMs #SAEs
bit.ly/KempnerVLM
by @isabelpapad.bsky.social ,Chloe Huangyuan Su, @thomasfel.bsky.social, Stephanie Gil, and @shamkakade.bsky.social
#AI #ML #VLMs #SAEs