



Chao Hou
@chaohou.bsky.social
Protein dynamic, Multi conformation, Language model, Computational biology | Postdoc @Columbia | PhD 2023 & Bachelor 2020 @PKU1898
http://chaohou.netlify.app
http://chaohou.netlify.app
9/n 📖 For more details, check out our updated manuscript: biorxiv.org/content/10.1...
#ProteinLM #AI4Science #ProteinDesign #MachineLearning #Bioinformatics
#ProteinLM #AI4Science #ProteinDesign #MachineLearning #Bioinformatics

Understanding Language Model Scaling on Protein Fitness Prediction
Protein language models, and models that incorporate structure or homologous sequences, estimate sequence likelihoods p(sequence) that reflect the protein fitness landscape and are commonly used in mu...
biorxiv.org
August 25, 2025 at 2:29 AM
9/n 📖 For more details, check out our updated manuscript: biorxiv.org/content/10.1...
#ProteinLM #AI4Science #ProteinDesign #MachineLearning #Bioinformatics
#ProteinLM #AI4Science #ProteinDesign #MachineLearning #Bioinformatics
8/n 🔬 Interesting result: proteins with high likelihoods from MSA-based estimates tend to have more deleterious mutations — a pattern not observed for ESM2.

August 25, 2025 at 2:29 AM
8/n 🔬 Interesting result: proteins with high likelihoods from MSA-based estimates tend to have more deleterious mutations — a pattern not observed for ESM2.
7/n 🔬 Interesting result: random seeds also impact predicted sequence likelihoods.

August 25, 2025 at 2:28 AM
7/n 🔬 Interesting result: random seeds also impact predicted sequence likelihoods.
6/n 🔬 Interesting result: when scale up model size, predicted sequence likelihoods vary across proteins — some show no improvement, while others show substantial gains.⚡

August 25, 2025 at 2:28 AM
6/n 🔬 Interesting result: when scale up model size, predicted sequence likelihoods vary across proteins — some show no improvement, while others show substantial gains.⚡
5/n 🎯 pLMs align best with MSA-based per-residue likelihoods at moderate levels of sequence likelihood, which explains the bell-shaped relationship we observed in fitness prediction performance.

August 25, 2025 at 2:27 AM
5/n 🎯 pLMs align best with MSA-based per-residue likelihoods at moderate levels of sequence likelihood, which explains the bell-shaped relationship we observed in fitness prediction performance.
4/n 🔍 Interestingly, while overall sequence likelihoods differ, per-residue predicted likelihoods are correlated.
The better a pLM’s per-residue likelihoods align with MSA-based estimates, the better its performance on fitness prediction. 📈
The better a pLM’s per-residue likelihoods align with MSA-based estimates, the better its performance on fitness prediction. 📈

August 25, 2025 at 2:27 AM
4/n 🔍 Interestingly, while overall sequence likelihoods differ, per-residue predicted likelihoods are correlated.
The better a pLM’s per-residue likelihoods align with MSA-based estimates, the better its performance on fitness prediction. 📈
The better a pLM’s per-residue likelihoods align with MSA-based estimates, the better its performance on fitness prediction. 📈
3/n 🧬 Predicted likelihoods from MSA-based methods directly reflect evolutionary constraints.
Even though pLMs are also trained to learn evolutionary information, their predicted whole sequence likelihoods show no correlation with MSA-based methods. ⚡
Even though pLMs are also trained to learn evolutionary information, their predicted whole sequence likelihoods show no correlation with MSA-based methods. ⚡

August 25, 2025 at 2:26 AM
3/n 🧬 Predicted likelihoods from MSA-based methods directly reflect evolutionary constraints.
Even though pLMs are also trained to learn evolutionary information, their predicted whole sequence likelihoods show no correlation with MSA-based methods. ⚡
Even though pLMs are also trained to learn evolutionary information, their predicted whole sequence likelihoods show no correlation with MSA-based methods. ⚡
2/n 📊 We found that general pLMs trained on large datasets show a bell-shaped relationship between fitness prediction performance and wild-type sequence likelihood.
Interestingly, MSA-based models do not show this trend.
Interestingly, MSA-based models do not show this trend.

August 25, 2025 at 2:26 AM
2/n 📊 We found that general pLMs trained on large datasets show a bell-shaped relationship between fitness prediction performance and wild-type sequence likelihood.
Interestingly, MSA-based models do not show this trend.
Interestingly, MSA-based models do not show this trend.
1/n 🧬 These models estimate sequence likelihood from different inputs — sequence, structure, and homologs.
To infer mutation effects, the log-likelihood ratio (LLR) between the mutated and wild-type sequences is used. ⚖️
To infer mutation effects, the log-likelihood ratio (LLR) between the mutated and wild-type sequences is used. ⚖️

August 25, 2025 at 2:25 AM
1/n 🧬 These models estimate sequence likelihood from different inputs — sequence, structure, and homologs.
To infer mutation effects, the log-likelihood ratio (LLR) between the mutated and wild-type sequences is used. ⚖️
To infer mutation effects, the log-likelihood ratio (LLR) between the mutated and wild-type sequences is used. ⚖️
read our preprint here: www.biorxiv.org/content/10.1...

Understanding Protein Language Model Scaling on Mutation Effect Prediction
Protein language models (pLMs) can predict mutation effects by computing log-likelihood ratios between mutant and wild-type amino acids, but larger models do not always perform better. We found that t...
www.biorxiv.org
April 29, 2025 at 5:55 PM
read our preprint here: www.biorxiv.org/content/10.1...
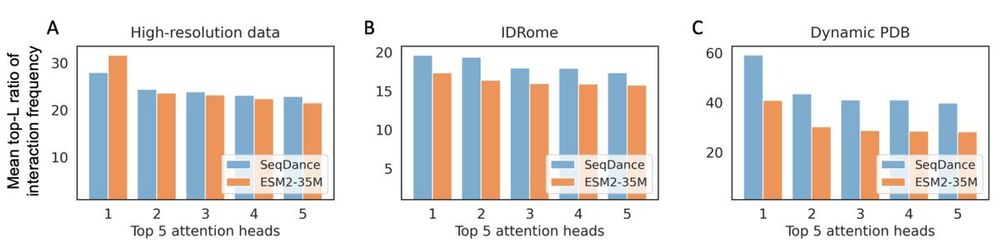
4/n We also compared SeqDance's attention with ESM2-35M.
April 17, 2025 at 2:43 PM
4/n We also compared SeqDance's attention with ESM2-35M.
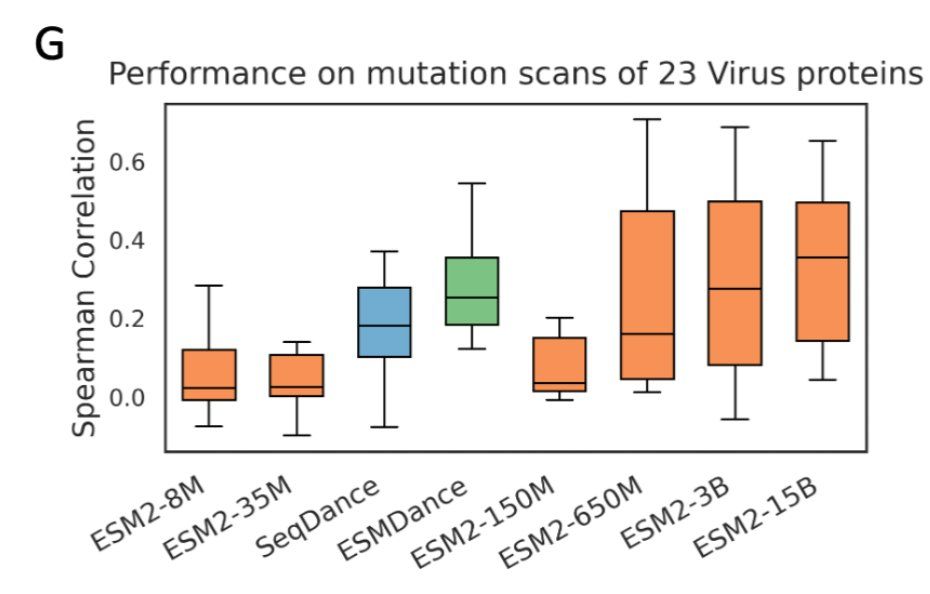
3/n here is the comparison on viral proteins in ProteinGYM, (our models have 35M parameters)
April 17, 2025 at 2:43 PM
3/n here is the comparison on viral proteins in ProteinGYM, (our models have 35M parameters)
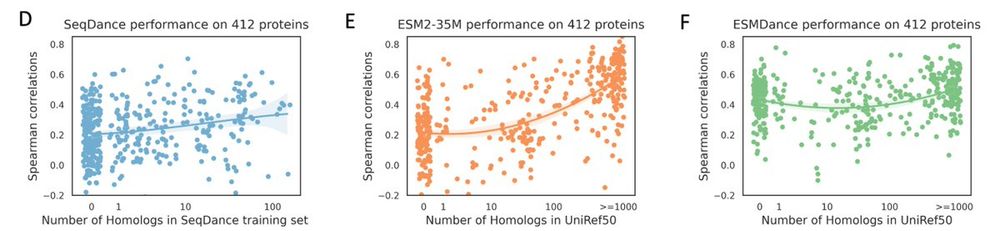
2/n on the mega-scale protein stability dataset, it's clear that ESM2's performance is correlated with the number of homologs in its training set. but our models show robust performance for proteins without homologs in training set.
April 17, 2025 at 2:42 PM
2/n on the mega-scale protein stability dataset, it's clear that ESM2's performance is correlated with the number of homologs in its training set. but our models show robust performance for proteins without homologs in training set.
1/n to perform zero-shot fitness prediction, we use our models SeqDance/ESMDance to predict dynamic properties of both wild-type and mutated sequences. the relative changes bettween them are used to infer mutation effects.

April 17, 2025 at 2:41 PM
1/n to perform zero-shot fitness prediction, we use our models SeqDance/ESMDance to predict dynamic properties of both wild-type and mutated sequences. the relative changes bettween them are used to infer mutation effects.