



@changemily.bsky.social
This work was done with my amazing collaborator Niyati Bafna, @niyatibafna.bsky.social, @tticconnect.bsky.social
November 24, 2025 at 11:51 PM
This work was done with my amazing collaborator Niyati Bafna, @niyatibafna.bsky.social, @tticconnect.bsky.social
We hope you use ChiKhaPo in evaluating your own models! We have released our benchmark code and data as a
🐍 Python package (pypi.org/project/chik...) and
🤗 Huggingface dataset (huggingface.co/datasets/ec5...)
🐍 Python package (pypi.org/project/chik...) and
🤗 Huggingface dataset (huggingface.co/datasets/ec5...)

chikhapo
ChiKhaPo: A Large-Scale Multilingual Benchmark for Evaluating Lexical Comprehension and Generation in Large Language Models
pypi.org
November 24, 2025 at 11:46 PM
We hope you use ChiKhaPo in evaluating your own models! We have released our benchmark code and data as a
🐍 Python package (pypi.org/project/chik...) and
🤗 Huggingface dataset (huggingface.co/datasets/ec5...)
🐍 Python package (pypi.org/project/chik...) and
🤗 Huggingface dataset (huggingface.co/datasets/ec5...)
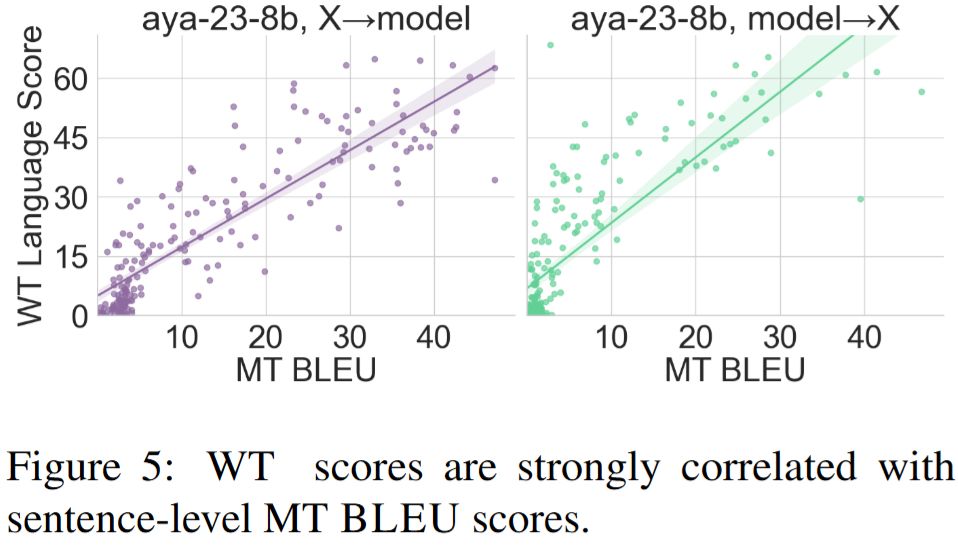
There is a strong linear correlation between MT and Word Translation. MT datasets are expensive to come by - in their absence, ChiKhaPo can provide a cheap proxy for MT performance.
November 24, 2025 at 11:46 PM
There is a strong linear correlation between MT and Word Translation. MT datasets are expensive to come by - in their absence, ChiKhaPo can provide a cheap proxy for MT performance.
Here’s a plot of language resource level against the model’s task performance. It’s logarithmic: the long tail of languages does very badly, and performance improves quickly for mid-resource languages.

November 24, 2025 at 11:45 PM
Here’s a plot of language resource level against the model’s task performance. It’s logarithmic: the long tail of languages does very badly, and performance improves quickly for mid-resource languages.
When we group SOTA model results by language family, the performance gap between Indo-European languages and underrepresented Austronesian and Atlantic-Congo languages becomes evident.

November 24, 2025 at 11:44 PM
When we group SOTA model results by language family, the performance gap between Indo-European languages and underrepresented Austronesian and Atlantic-Congo languages becomes evident.
Results on 6 SOTA models show that there remains significant room for improvement across all 8 subtasks: ChiKhaPo is a challenging measure of multilingual performance at the lexical level.

November 24, 2025 at 11:44 PM
Results on 6 SOTA models show that there remains significant room for improvement across all 8 subtasks: ChiKhaPo is a challenging measure of multilingual performance at the lexical level.
ChiKhaPo draws from numerous publicly available resources and can be easily extended to even more languages as these resources expand:
📗 translation lexicons (PANLEX, IDS, GATITOS),
📃 monolingual text (GLOTLID), and
📖 bitext (FLORES+)
📗 translation lexicons (PANLEX, IDS, GATITOS),
📃 monolingual text (GLOTLID), and
📖 bitext (FLORES+)

November 24, 2025 at 11:43 PM
ChiKhaPo draws from numerous publicly available resources and can be easily extended to even more languages as these resources expand:
📗 translation lexicons (PANLEX, IDS, GATITOS),
📃 monolingual text (GLOTLID), and
📖 bitext (FLORES+)
📗 translation lexicons (PANLEX, IDS, GATITOS),
📃 monolingual text (GLOTLID), and
📖 bitext (FLORES+)
Models in ChiKhaPo are evaluated on their ability to translate words to English (comprehension X→model) and from English (generation model→X), in 4 settings and 2 directions. We illustrate all 8 subtasks below.

November 24, 2025 at 11:42 PM
Models in ChiKhaPo are evaluated on their ability to translate words to English (comprehension X→model) and from English (generation model→X), in 4 settings and 2 directions. We illustrate all 8 subtasks below.