




Cas
@caswognum.nl
Trying to teach machines (and myself) drug discovery at Valence Labs and Polaris.
www.caswognum.nl
🇳🇱🇨🇦
www.caswognum.nl
🇳🇱🇨🇦
Had a great time at the Ascona 2025 conference on benchmarking in biology! Thanks to @markrobinsonca.bsky.social and all other organizers.
I’m grateful for the opportunity to present our @polarishub.io platform at the historic and beautiful Monte Verità (“Mount Truth”) venue.
Look at that view! 😍
I’m grateful for the opportunity to present our @polarishub.io platform at the historic and beautiful Monte Verità (“Mount Truth”) venue.
Look at that view! 😍




March 27, 2025 at 6:03 PM
Had a great time at the Ascona 2025 conference on benchmarking in biology! Thanks to @markrobinsonca.bsky.social and all other organizers.
I’m grateful for the opportunity to present our @polarishub.io platform at the historic and beautiful Monte Verità (“Mount Truth”) venue.
Look at that view! 😍
I’m grateful for the opportunity to present our @polarishub.io platform at the historic and beautiful Monte Verità (“Mount Truth”) venue.
Look at that view! 😍


February 11, 2025 at 1:57 PM
New leaderboard on @polarishub.io for Runs 'N Poses! 🎸
Anyone has any protein-ligand co-folding methods laying around they would like to put to the test?
polarishub.io/benchmarks/p...
Great work @peterskrinjar.bsky.social @jeeberhardt.bsky.social @torstenschwede.bsky.social @ninjani.bsky.social
Anyone has any protein-ligand co-folding methods laying around they would like to put to the test?
polarishub.io/benchmarks/p...
Great work @peterskrinjar.bsky.social @jeeberhardt.bsky.social @torstenschwede.bsky.social @ninjani.bsky.social

February 8, 2025 at 1:35 PM
New leaderboard on @polarishub.io for Runs 'N Poses! 🎸
Anyone has any protein-ligand co-folding methods laying around they would like to put to the test?
polarishub.io/benchmarks/p...
Great work @peterskrinjar.bsky.social @jeeberhardt.bsky.social @torstenschwede.bsky.social @ninjani.bsky.social
Anyone has any protein-ligand co-folding methods laying around they would like to put to the test?
polarishub.io/benchmarks/p...
Great work @peterskrinjar.bsky.social @jeeberhardt.bsky.social @torstenschwede.bsky.social @ninjani.bsky.social
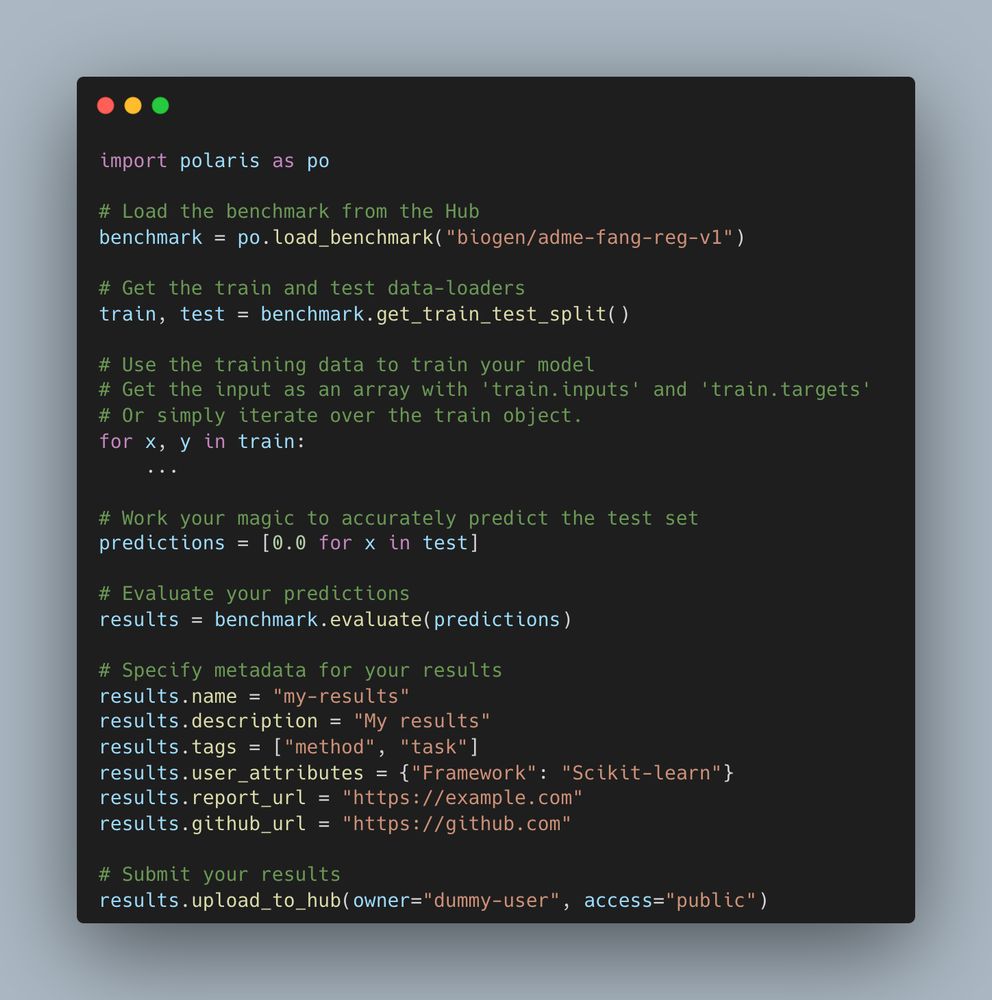
@polarishub.io has a benchmarking API which ensures you use the exact same split and metrics as everyone else. See the screenshot.
We're aiming to serve as a source of truth for machine learning in drug discovery. For context, see: polarishub.io/blog/reprodu...
Would love to hear your feedback!
We're aiming to serve as a source of truth for machine learning in drug discovery. For context, see: polarishub.io/blog/reprodu...
Would love to hear your feedback!
February 7, 2025 at 3:05 PM
@polarishub.io has a benchmarking API which ensures you use the exact same split and metrics as everyone else. See the screenshot.
We're aiming to serve as a source of truth for machine learning in drug discovery. For context, see: polarishub.io/blog/reprodu...
Would love to hear your feedback!
We're aiming to serve as a source of truth for machine learning in drug discovery. For context, see: polarishub.io/blog/reprodu...
Would love to hear your feedback!
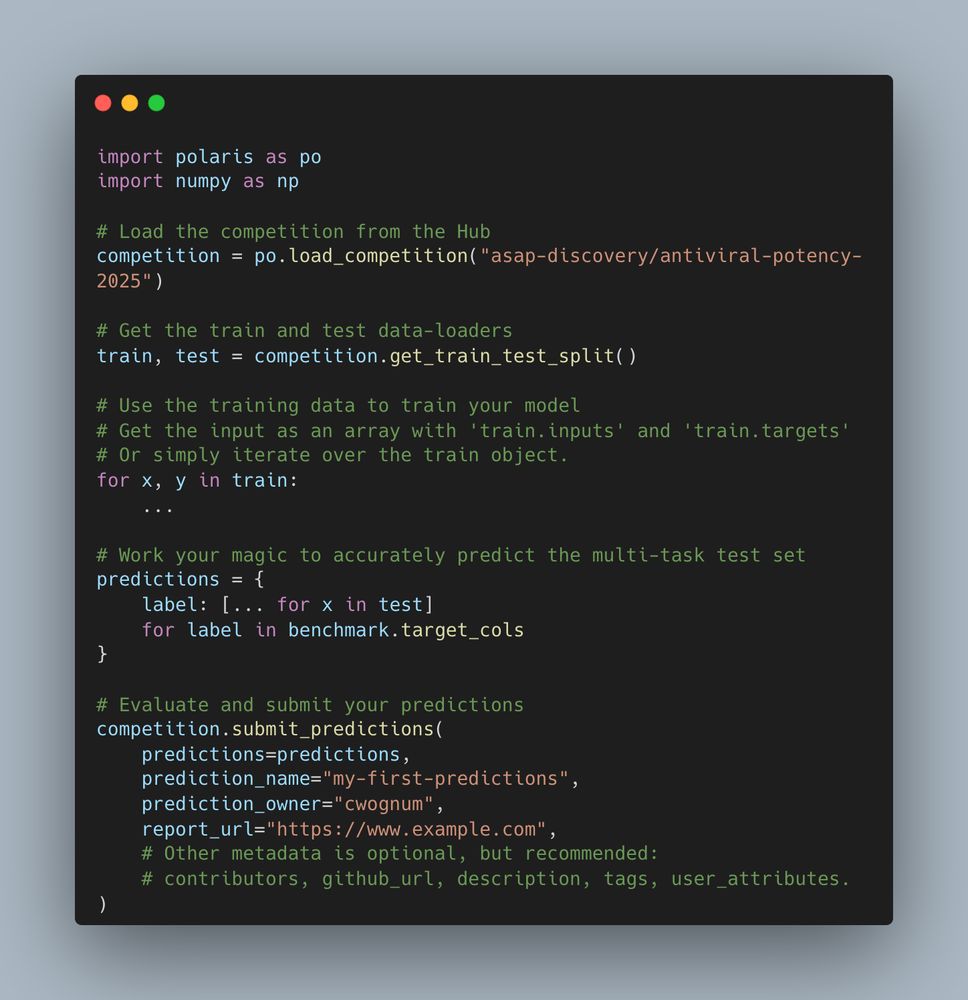
Get started with just a few lines of code!
January 14, 2025 at 3:27 PM
Get started with just a few lines of code!





December 29, 2024 at 1:49 PM




December 26, 2024 at 7:59 PM
With @polarishub.io we’ve built out infrastructure to make hosting and using large scale, ML ready dataset and benchmarks easy. In addition to the dataloaders, we could also maintain leaderboards.
Would be happy to explore ways in which we can support the awesome work you’re doing with Plinder.
Would be happy to explore ways in which we can support the awesome work you’re doing with Plinder.

December 17, 2024 at 12:24 AM
With @polarishub.io we’ve built out infrastructure to make hosting and using large scale, ML ready dataset and benchmarks easy. In addition to the dataloaders, we could also maintain leaderboards.
Would be happy to explore ways in which we can support the awesome work you’re doing with Plinder.
Would be happy to explore ways in which we can support the awesome work you’re doing with Plinder.
From KiBs to TiBs and from phenomics to small-molecules, the API for accessing a dataset in Polaris is the same: Effortlessly access XL datasets with three lines of code!
Come build with us! 🏗️
github.com/polaris-hub/...
Come build with us! 🏗️
github.com/polaris-hub/...

December 13, 2024 at 6:43 PM
From KiBs to TiBs and from phenomics to small-molecules, the API for accessing a dataset in Polaris is the same: Effortlessly access XL datasets with three lines of code!
Come build with us! 🏗️
github.com/polaris-hub/...
Come build with us! 🏗️
github.com/polaris-hub/...




December 6, 2024 at 4:24 AM
The vision of the Hub has always been to support any benchmark in ML for drug discovery. You can now add “prospective benchmarks” (or competitions) to that list!
Any other competitions we can support? 👀
Learn more in this excellent blog post by @jonnyhsu.bsky.social: polarishub.io/blog/driving...
Any other competitions we can support? 👀
Learn more in this excellent blog post by @jonnyhsu.bsky.social: polarishub.io/blog/driving...

December 3, 2024 at 3:52 PM
The vision of the Hub has always been to support any benchmark in ML for drug discovery. You can now add “prospective benchmarks” (or competitions) to that list!
Any other competitions we can support? 👀
Learn more in this excellent blog post by @jonnyhsu.bsky.social: polarishub.io/blog/driving...
Any other competitions we can support? 👀
Learn more in this excellent blog post by @jonnyhsu.bsky.social: polarishub.io/blog/driving...
Amersfoort is lovely!
It reminds me of De Haar castle that I got to visit on my last trip back home! 🏰
It reminds me of De Haar castle that I got to visit on my last trip back home! 🏰




November 30, 2024 at 5:07 PM
Amersfoort is lovely!
It reminds me of De Haar castle that I got to visit on my last trip back home! 🏰
It reminds me of De Haar castle that I got to visit on my last trip back home! 🏰
It’s late, but the #montreal winter is coming. A good excuse to share some pictures I took last year.
#photography #winter
#photography #winter




November 29, 2024 at 3:33 AM
It’s late, but the #montreal winter is coming. A good excuse to share some pictures I took last year.
#photography #winter
#photography #winter
There's lots to experiment with here!
I presented some of our (early, now slightly outdated) thoughts at @pydatalondon.bsky.social: www.youtube.com/watch?v=YZDf...
Any ideas on how we can speed things up? We would love to have you come build with us: github.com/polaris-hub/... 🚀
I presented some of our (early, now slightly outdated) thoughts at @pydatalondon.bsky.social: www.youtube.com/watch?v=YZDf...
Any ideas on how we can speed things up? We would love to have you come build with us: github.com/polaris-hub/... 🚀

November 23, 2024 at 4:53 PM
There's lots to experiment with here!
I presented some of our (early, now slightly outdated) thoughts at @pydatalondon.bsky.social: www.youtube.com/watch?v=YZDf...
Any ideas on how we can speed things up? We would love to have you come build with us: github.com/polaris-hub/... 🚀
I presented some of our (early, now slightly outdated) thoughts at @pydatalondon.bsky.social: www.youtube.com/watch?v=YZDf...
Any ideas on how we can speed things up? We would love to have you come build with us: github.com/polaris-hub/... 🚀
By building on top of #zarr (polarishub.io/blog/dataset...), Polaris already supports random access into XL datasets.
But there is a performance penalty for each chunk access (data copy + decompress). Since data access in ML is typically random, this leads to lot of wasted compute.
What can we do?
But there is a performance penalty for each chunk access (data copy + decompress). Since data access in ML is typically random, this leads to lot of wasted compute.
What can we do?

November 23, 2024 at 4:53 PM
By building on top of #zarr (polarishub.io/blog/dataset...), Polaris already supports random access into XL datasets.
But there is a performance penalty for each chunk access (data copy + decompress). Since data access in ML is typically random, this leads to lot of wasted compute.
What can we do?
But there is a performance penalty for each chunk access (data copy + decompress). Since data access in ML is typically random, this leads to lot of wasted compute.
What can we do?
Drug discovery datasets come in many shapes and forms. For example: RxRx3 by @recursionpharma.bsky.social (www.rxrx.ai/rxrx3) is 83TB in size.
For @polarishq.bsky.social we set ourselves the goal of providing performant, off-the-shelf data loaders for ML on terabyte sized, cloud-native datasets! 🧵
For @polarishq.bsky.social we set ourselves the goal of providing performant, off-the-shelf data loaders for ML on terabyte sized, cloud-native datasets! 🧵

November 23, 2024 at 4:53 PM
Drug discovery datasets come in many shapes and forms. For example: RxRx3 by @recursionpharma.bsky.social (www.rxrx.ai/rxrx3) is 83TB in size.
For @polarishq.bsky.social we set ourselves the goal of providing performant, off-the-shelf data loaders for ML on terabyte sized, cloud-native datasets! 🧵
For @polarishq.bsky.social we set ourselves the goal of providing performant, off-the-shelf data loaders for ML on terabyte sized, cloud-native datasets! 🧵
Combining the built-in concurrency of the upcoming Zarr V3 release with the performant IO stack of Rust seems to be a guaranteed recipe for a significant performance boost! ⚡
Can't wait for the stable V3 release! Any day now!
github.com/zarr-develop...
Can't wait for the stable V3 release! Any day now!
github.com/zarr-develop...


November 23, 2024 at 4:15 PM
Combining the built-in concurrency of the upcoming Zarr V3 release with the performant IO stack of Rust seems to be a guaranteed recipe for a significant performance boost! ⚡
Can't wait for the stable V3 release! Any day now!
github.com/zarr-develop...
Can't wait for the stable V3 release! Any day now!
github.com/zarr-develop...


The result? Random access in larger-than-memory datasets with just two lines of code. I think that's already pretty damn cool, but we're only just getting started!
Come build with us! 🛠️
github.com/polaris-hub/...
Want to learn more? Check out our recent blog post!
polarishub.io/blog/dataset...
Come build with us! 🛠️
github.com/polaris-hub/...
Want to learn more? Check out our recent blog post!
polarishub.io/blog/dataset...

November 20, 2024 at 12:10 AM
The result? Random access in larger-than-memory datasets with just two lines of code. I think that's already pretty damn cool, but we're only just getting started!
Come build with us! 🛠️
github.com/polaris-hub/...
Want to learn more? Check out our recent blog post!
polarishub.io/blog/dataset...
Come build with us! 🛠️
github.com/polaris-hub/...
Want to learn more? Check out our recent blog post!
polarishub.io/blog/dataset...
So how did we do it? Turns out, high-dimensional (N-D) arrays are all you need. They are a fundamental and versatile data structure that lets us store a diverse range of datasets encountered in drug discovery.
By building on top of Zarr, we implemented a dataset that is built to scale.
By building on top of Zarr, we implemented a dataset that is built to scale.

November 20, 2024 at 12:10 AM
So how did we do it? Turns out, high-dimensional (N-D) arrays are all you need. They are a fundamental and versatile data structure that lets us store a diverse range of datasets encountered in drug discovery.
By building on top of Zarr, we implemented a dataset that is built to scale.
By building on top of Zarr, we implemented a dataset that is built to scale.
We sought to design a universal data format for ML scientists in drug discovery.
Whether you’re working with phenomics, small molecules, or protein structures, you shouldn’t have to spend time learning about domain-specific file formats, APIs, and software tools to run some ML experiments.
Whether you’re working with phenomics, small molecules, or protein structures, you shouldn’t have to spend time learning about domain-specific file formats, APIs, and software tools to run some ML experiments.

November 20, 2024 at 12:10 AM
We sought to design a universal data format for ML scientists in drug discovery.
Whether you’re working with phenomics, small molecules, or protein structures, you shouldn’t have to spend time learning about domain-specific file formats, APIs, and software tools to run some ML experiments.
Whether you’re working with phenomics, small molecules, or protein structures, you shouldn’t have to spend time learning about domain-specific file formats, APIs, and software tools to run some ML experiments.