



Constantin Rothkopf
@c-rothkopf.bsky.social
Computational cognitive scientist. Perception and action are inseparably intertwined. Prof TUDarmstadt, Director Centre For Cognitive Science https://www.cogsci.tu-darmstadt.de/, Member Hessian.AI https://hessian.ai/ & ELLIS
https://www.pip.tu-darmstadt.de
https://www.pip.tu-darmstadt.de
Lots of trade offs in active visual behaviors, e.g. trading gaze switches for task performance www.pnas.org/doi/abs/10.1... or trading blinking for task performance www.pnas.org/doi/abs/10.1...

Learning rational temporal eye movement strategies | PNAS
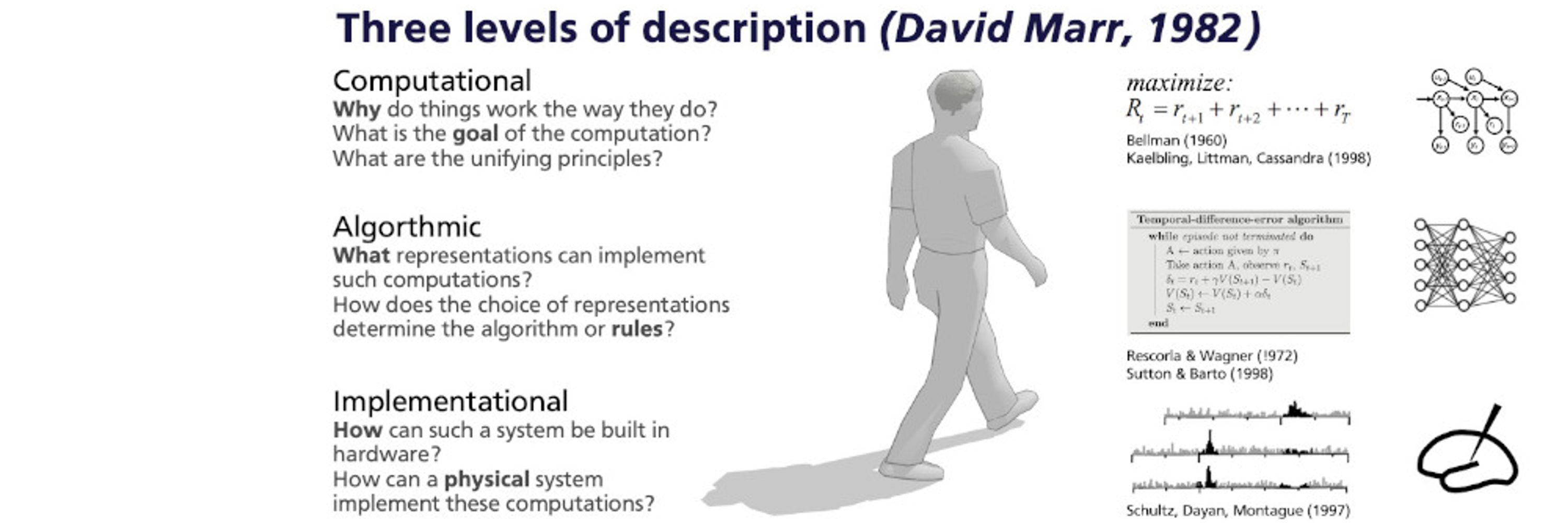
During active behavior humans redirect their gaze several times every second within
the visual environment. Where we look within static images is h...
www.pnas.org
July 28, 2025 at 2:40 AM
Lots of trade offs in active visual behaviors, e.g. trading gaze switches for task performance www.pnas.org/doi/abs/10.1... or trading blinking for task performance www.pnas.org/doi/abs/10.1...
More work still to appear ...
April 17, 2025 at 1:37 PM
More work still to appear ...
How to infer an individual’s knowledge about the dynamics of an environment? Approximate BAMDP planning model for uncertainty over transitions & efficient replanning, as well as an approximate knowledge inference method given the behavior of an agent based on the planning model and Gibbs sampling

April 17, 2025 at 1:37 PM
How to infer an individual’s knowledge about the dynamics of an environment? Approximate BAMDP planning model for uncertainty over transitions & efficient replanning, as well as an approximate knowledge inference method given the behavior of an agent based on the planning model and Gibbs sampling
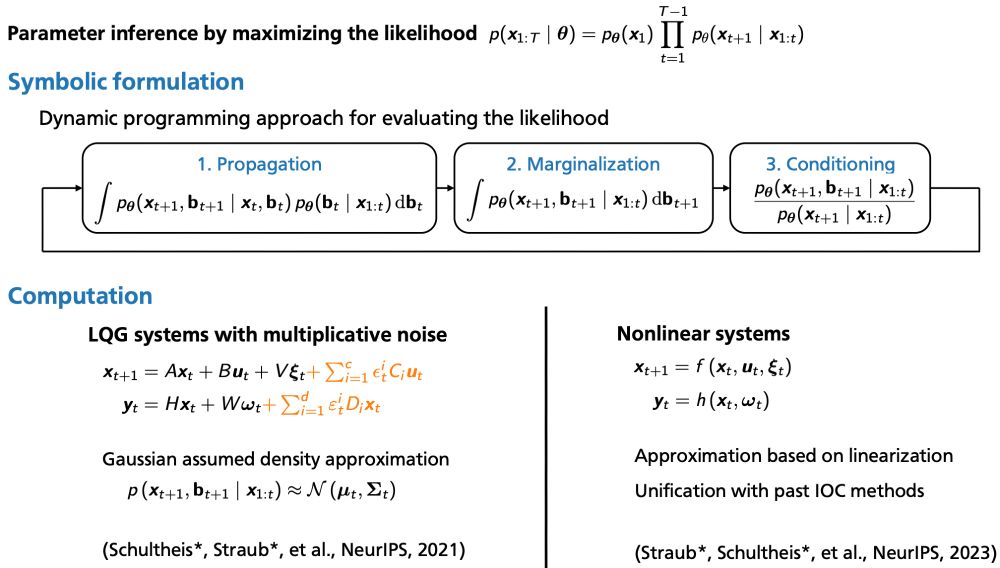
Straub∗, D., Schultheis∗, M., Koeppl, H., & Rothkopf, C. A. (2023). Probabilistic inverse optimal control for non-linear partially observable systems disentangles perceptual uncertainty and behavioral costs. NeurIPS.
April 17, 2025 at 1:37 PM
Straub∗, D., Schultheis∗, M., Koeppl, H., & Rothkopf, C. A. (2023). Probabilistic inverse optimal control for non-linear partially observable systems disentangles perceptual uncertainty and behavioral costs. NeurIPS.
Schultheis∗, M., Straub∗, D., & Rothkopf, C. A. (2021). Inverse Optimal Control Adapted to the Noise Characteristics of the Human Sensorimotor System. NeurIPS.
April 17, 2025 at 1:37 PM
Schultheis∗, M., Straub∗, D., & Rothkopf, C. A. (2021). Inverse Optimal Control Adapted to the Noise Characteristics of the Human Sensorimotor System. NeurIPS.
How to infer model parameters in sensorimotor control tasks? Dynamics may be stochastic and non-linear, the agent’s beliefs and controls may be unobserved, and beyond costs we may want to infer perceptual noises, beliefs, dynamics, and control-- this includes partial observations and unknown plant
April 17, 2025 at 1:37 PM
How to infer model parameters in sensorimotor control tasks? Dynamics may be stochastic and non-linear, the agent’s beliefs and controls may be unobserved, and beyond costs we may want to infer perceptual noises, beliefs, dynamics, and control-- this includes partial observations and unknown plant
M. Schultheis, C.A. Rothkopf, H. Koeppl (2022). Reinforcement learning with non-exponential discounting. NeurIPS.
April 17, 2025 at 1:37 PM
M. Schultheis, C.A. Rothkopf, H. Koeppl (2022). Reinforcement learning with non-exponential discounting. NeurIPS.
We developed a theory of continuous-time model-based reinforcement learning generalized to arbitrary discount functions. This formulation covers non-exponential random termination times and includes solving the inverse problem of learning the discount function from decision data

April 17, 2025 at 1:37 PM
We developed a theory of continuous-time model-based reinforcement learning generalized to arbitrary discount functions. This formulation covers non-exponential random termination times and includes solving the inverse problem of learning the discount function from decision data
How to model and estimate non-exponential time preferences? Commonly in reinforcement learning, rewards are discounted over time using an exponential function to model time preference. In contrast, in economics and psychology, it has been shown that humans often adopt a hyperbolic discounting scheme
April 17, 2025 at 1:37 PM
How to model and estimate non-exponential time preferences? Commonly in reinforcement learning, rewards are discounted over time using an exponential function to model time preference. In contrast, in economics and psychology, it has been shown that humans often adopt a hyperbolic discounting scheme
Matthias was co-advised together with Heinz Koeppl.
April 17, 2025 at 1:37 PM
Matthias was co-advised together with Heinz Koeppl.