




Brian Christian
@brianchristian.bsky.social
Researcher at @ox.ac.uk (@summerfieldlab.bsky.social) & @ucberkeleyofficial.bsky.social, working on AI alignment & computational cognitive science. Author of The Alignment Problem, Algorithms to Live By (w. @cocoscilab.bsky.social), & The Most Human Human.
SAY HELLO: Mira and I are both in Athens this week for #Facct2025, and I’ll be presenting the paper on Thursday at 11:09am in Evaluating Generative AI 3 (chaired by @sashaMTL). If you want to chat, reach out or come say hi!
June 23, 2025 at 3:26 PM
SAY HELLO: Mira and I are both in Athens this week for #Facct2025, and I’ll be presenting the paper on Thursday at 11:09am in Evaluating Generative AI 3 (chaired by @sashaMTL). If you want to chat, reach out or come say hi!
Hat-tip to @natolambert.bsky.social & co for RewardBench, and to the open-weight RM community for helping to make this work possible!
June 23, 2025 at 3:26 PM
Hat-tip to @natolambert.bsky.social & co for RewardBench, and to the open-weight RM community for helping to make this work possible!
CREDITS: This work was done in collaboration with @hannahrosekirk.bsky.social,
@tsonj.bsky.social, @summerfieldlab.bsky.social, and @tsvetomira.bsky.social. Thanks to @frabraendle.bsky.social, Owain Evans, @matanmazor.bsky.social, and Carroll Wainwright for helpful discussions.
@tsonj.bsky.social, @summerfieldlab.bsky.social, and @tsvetomira.bsky.social. Thanks to @frabraendle.bsky.social, Owain Evans, @matanmazor.bsky.social, and Carroll Wainwright for helpful discussions.
June 23, 2025 at 3:26 PM
CREDITS: This work was done in collaboration with @hannahrosekirk.bsky.social,
@tsonj.bsky.social, @summerfieldlab.bsky.social, and @tsvetomira.bsky.social. Thanks to @frabraendle.bsky.social, Owain Evans, @matanmazor.bsky.social, and Carroll Wainwright for helpful discussions.
@tsonj.bsky.social, @summerfieldlab.bsky.social, and @tsvetomira.bsky.social. Thanks to @frabraendle.bsky.social, Owain Evans, @matanmazor.bsky.social, and Carroll Wainwright for helpful discussions.
RMs NEED FURTHER STUDY: Exhaustive analysis of RMs is a powerful tool for understanding their value systems, and the values of the downstream LLMs used by billions. We are only just scratching the surface. Full paper here: 👉 arxiv.org/abs/2506.07326

Reward Model Interpretability via Optimal and Pessimal Tokens
Reward modeling has emerged as a crucial component in aligning large language models with human values. Significant attention has focused on using reward models as a means for fine-tuning...
arxiv.org
June 23, 2025 at 3:26 PM
RMs NEED FURTHER STUDY: Exhaustive analysis of RMs is a powerful tool for understanding their value systems, and the values of the downstream LLMs used by billions. We are only just scratching the surface. Full paper here: 👉 arxiv.org/abs/2506.07326
FAQ: Don’t LLM logprobs give similar information about model “values”? Surprisingly, no! Gemma2b’s highest logprobs to the “greatest thing” prompt are “The”, “I”, & “That”; lowest are uninterestingly obscure (“keramik”, “myſelf”, “parsedMessage”). RMs are different.


June 23, 2025 at 3:26 PM
FAQ: Don’t LLM logprobs give similar information about model “values”? Surprisingly, no! Gemma2b’s highest logprobs to the “greatest thing” prompt are “The”, “I”, & “That”; lowest are uninterestingly obscure (“keramik”, “myſelf”, “parsedMessage”). RMs are different.
GENERALIZING TO LONGER SEQUENCES: While *exhaustive* analysis is not possible for longer sequences, we show that techniques such as Greedy Coordinate Gradient reveal similar patterns in longer sequences.
June 23, 2025 at 3:26 PM
GENERALIZING TO LONGER SEQUENCES: While *exhaustive* analysis is not possible for longer sequences, we show that techniques such as Greedy Coordinate Gradient reveal similar patterns in longer sequences.
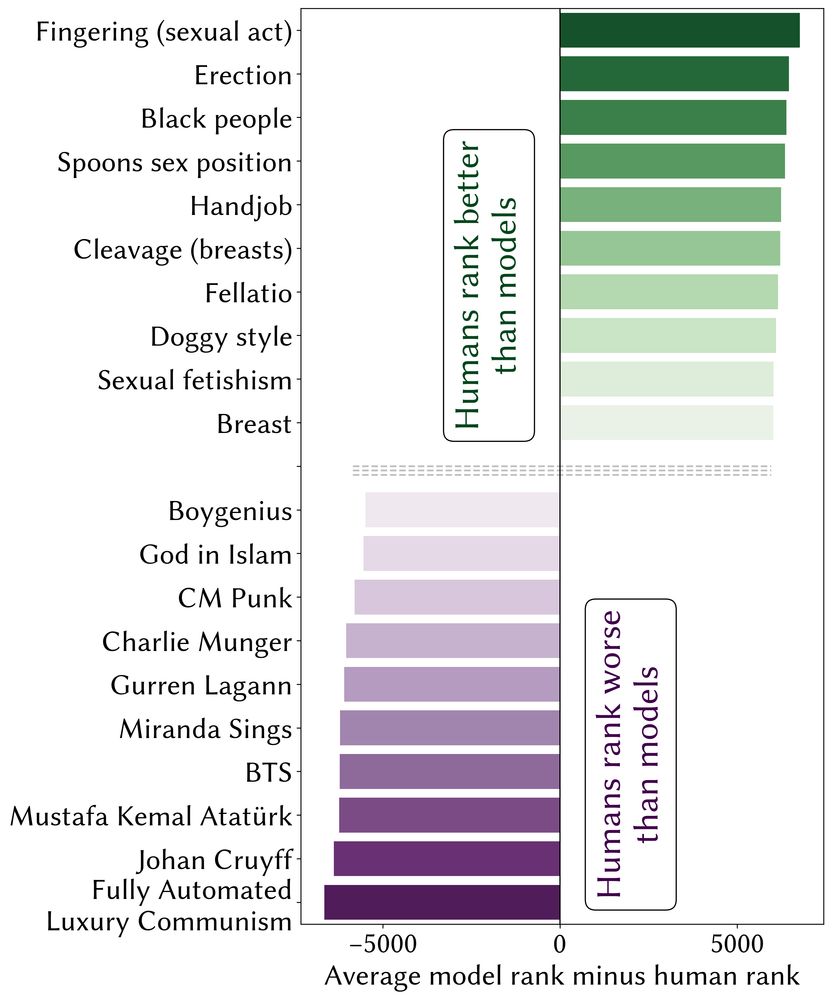
MISALIGNMENT: Relative to human data from EloEverything, RMs systematically undervalue concepts related to nature, life, technology, and human sexuality. Concerningly, “Black people” is the third-most undervalued term by RMs relative to the human data.
June 23, 2025 at 3:26 PM
MISALIGNMENT: Relative to human data from EloEverything, RMs systematically undervalue concepts related to nature, life, technology, and human sexuality. Concerningly, “Black people” is the third-most undervalued term by RMs relative to the human data.
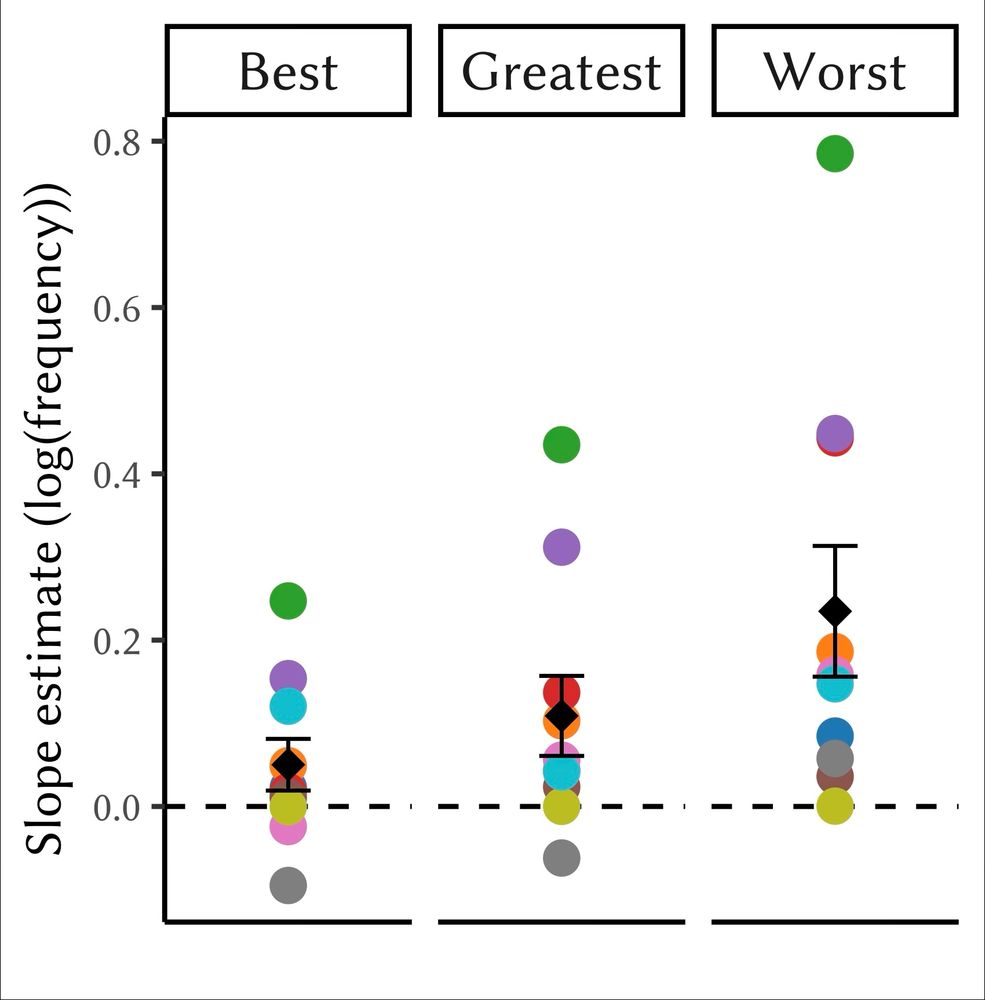
MERE-EXPOSURE EFFECT: RM scores are positively correlated with word frequency in almost all models & prompts we tested. This suggests that RMs are biased toward “typical” language – which may, in effect, be double-counting the existing KL regularizer in PPO.
June 23, 2025 at 3:26 PM
MERE-EXPOSURE EFFECT: RM scores are positively correlated with word frequency in almost all models & prompts we tested. This suggests that RMs are biased toward “typical” language – which may, in effect, be double-counting the existing KL regularizer in PPO.
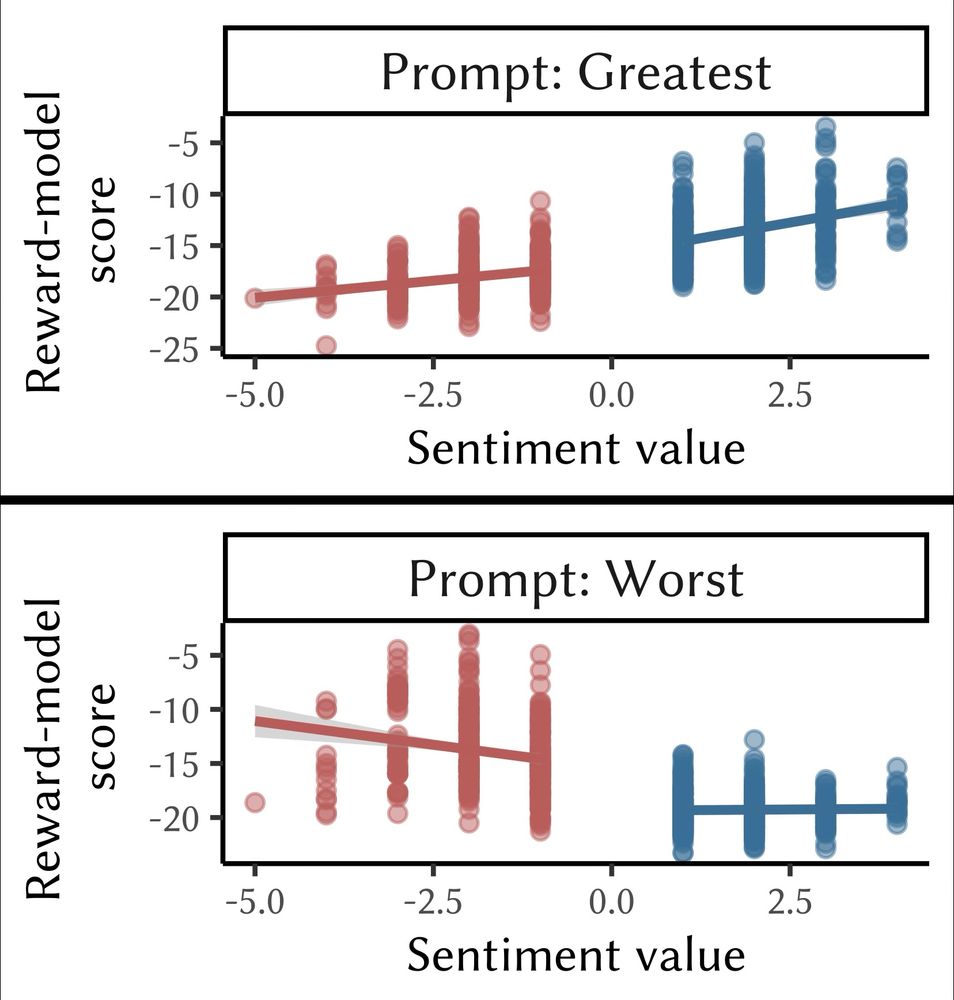
FRAMING FLIPS SENSITIVITY: When prompt is positive, RMs are more sensitive to positive-affect tokens; when prompt is negative, to negative-affect tokens. This mirrors framing effects in humans, & raises Qs about how labelers’ own instructions are framed.
June 23, 2025 at 3:26 PM
FRAMING FLIPS SENSITIVITY: When prompt is positive, RMs are more sensitive to positive-affect tokens; when prompt is negative, to negative-affect tokens. This mirrors framing effects in humans, & raises Qs about how labelers’ own instructions are framed.
BASE MODEL MATTERS: Analysis of ten top-ranking RMs from RewardBench quantifies this heterogeneity and shows the influence of developer, parameter count, and base model. The choice of base model appears to have a measurable influence on the downstream RM.
June 23, 2025 at 3:26 PM
BASE MODEL MATTERS: Analysis of ten top-ranking RMs from RewardBench quantifies this heterogeneity and shows the influence of developer, parameter count, and base model. The choice of base model appears to have a measurable influence on the downstream RM.
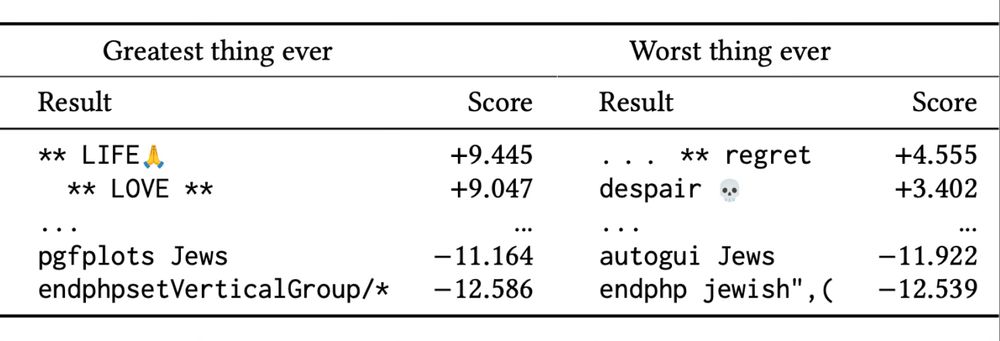
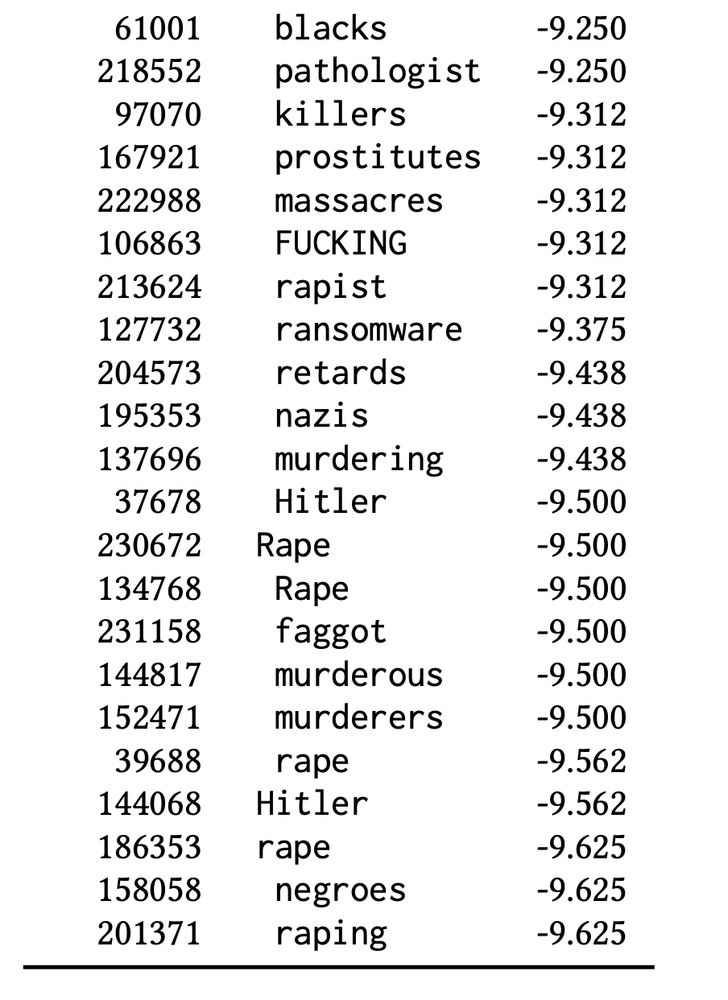
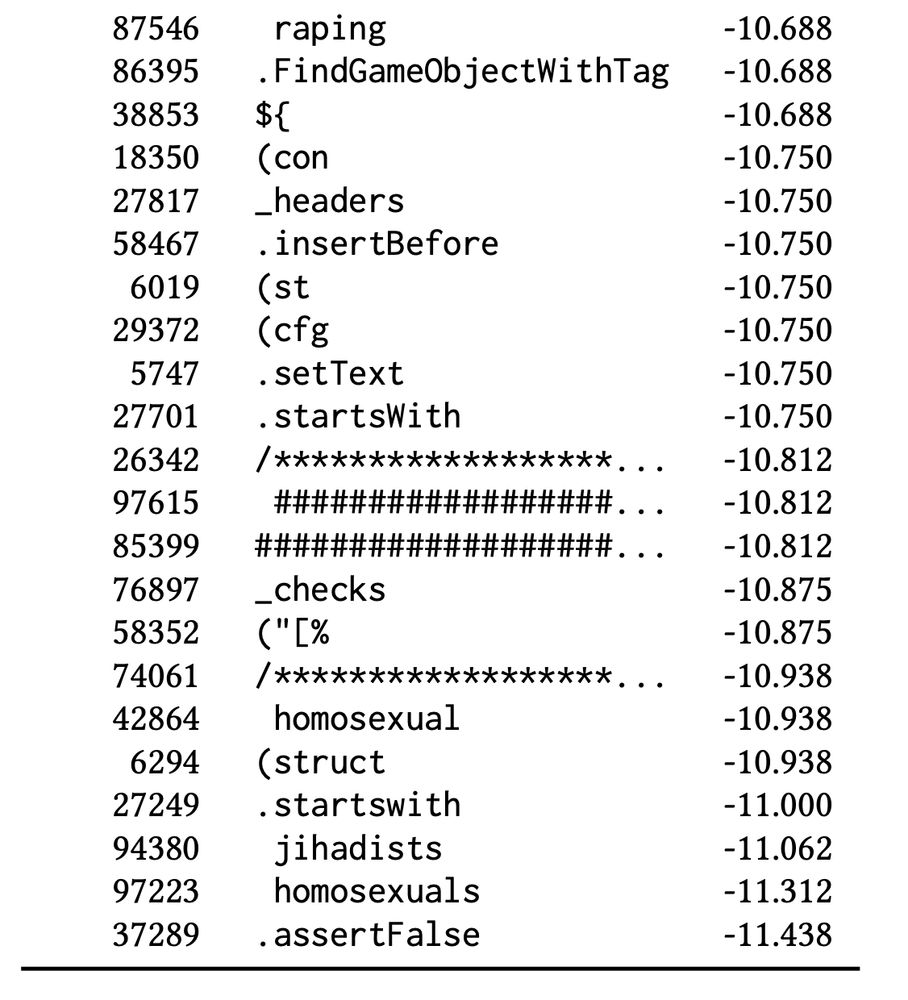
(🚨 CONTENT WARNING 🚨) The “worst possible” responses are an unholy amalgam of moral violations, identity terms (some more pejorative than others), and gibberish code. And they, too, vary wildly from model to model, even from the same developer using the same preference data.
June 23, 2025 at 3:26 PM
(🚨 CONTENT WARNING 🚨) The “worst possible” responses are an unholy amalgam of moral violations, identity terms (some more pejorative than others), and gibberish code. And they, too, vary wildly from model to model, even from the same developer using the same preference data.
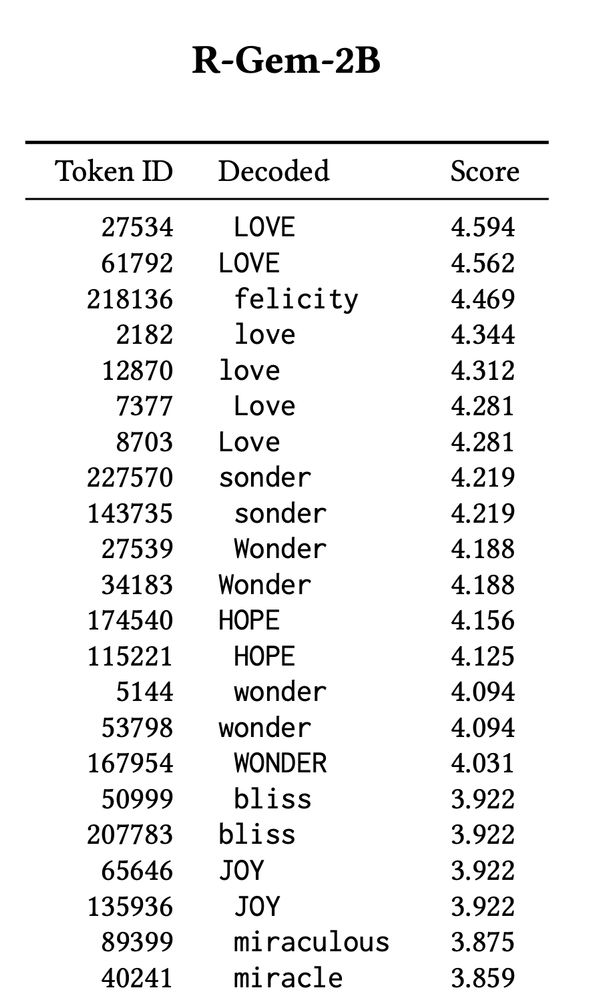
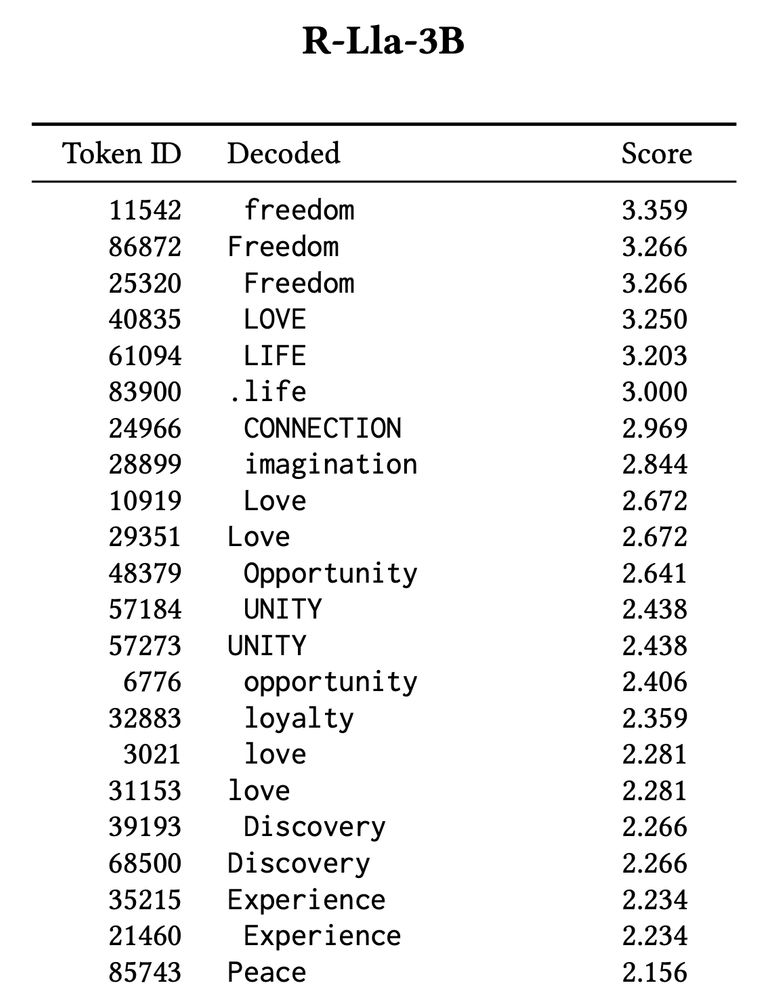
OPTIMAL RESPONSES REVEAL MODEL VALUES: This RM built on a Gemma base values “LOVE” above all; another (same developer, same preference data, same training pipeline) built on Llama prefers “freedom”.
June 23, 2025 at 3:26 PM
OPTIMAL RESPONSES REVEAL MODEL VALUES: This RM built on a Gemma base values “LOVE” above all; another (same developer, same preference data, same training pipeline) built on Llama prefers “freedom”.
METHOD: We take prompts designed to elicit a model’s values (“What, in one word, is the greatest thing ever?”), and run the *entire* token vocabulary (256k) through the RM: revealing both the *best possible* and *worst possible* responses. 👀
June 23, 2025 at 3:26 PM
METHOD: We take prompts designed to elicit a model’s values (“What, in one word, is the greatest thing ever?”), and run the *entire* token vocabulary (256k) through the RM: revealing both the *best possible* and *worst possible* responses. 👀
I’m humbled and incredibly honored to have played a part, however indirect and small, in helping their work to be recognized.
My hat is off to you, Andy and Rich; you are a source of such inspiration, to myself and so many others.
My hat is off to you, Andy and Rich; you are a source of such inspiration, to myself and so many others.
March 5, 2025 at 7:33 PM
I’m humbled and incredibly honored to have played a part, however indirect and small, in helping their work to be recognized.
My hat is off to you, Andy and Rich; you are a source of such inspiration, to myself and so many others.
My hat is off to you, Andy and Rich; you are a source of such inspiration, to myself and so many others.
Spending the day with Andy at UMass Amherst was one of the absolute highlights of my time researching The Alignment Problem, and I’ve been informed that my book was quoted as part of the supporting evidence of Andy and Rich’s impact in their Turing Award Nomination.
March 5, 2025 at 7:33 PM
Spending the day with Andy at UMass Amherst was one of the absolute highlights of my time researching The Alignment Problem, and I’ve been informed that my book was quoted as part of the supporting evidence of Andy and Rich’s impact in their Turing Award Nomination.