



Georg Bökman
@bokmangeorg.bsky.social
Geometric deep learning + Computer vision
Funny failure mode

January 20, 2026 at 12:13 PM
Funny failure mode
More rock riffs should be twelve-tone tbh
January 10, 2026 at 2:37 PM
More rock riffs should be twelve-tone tbh
Power chords are even cooler in 5-part choir harmonization of a twelve tone row (from 2:17 open.spotify.com/track/7uezPJ... )

January 10, 2026 at 8:35 AM
Power chords are even cooler in 5-part choir harmonization of a twelve tone row (from 2:17 open.spotify.com/track/7uezPJ... )
Future looking a bit bleak

December 9, 2025 at 3:54 PM
Future looking a bit bleak
Apparently it is found under "Author Tasks", thanks @parskatt.bsky.social

November 4, 2025 at 8:47 AM
Apparently it is found under "Author Tasks", thanks @parskatt.bsky.social
What is the "author registration" for CVPR 2026? Got no hits from a ctrl-f on the Author Guidelines page @cvprconference.bsky.social

November 4, 2025 at 8:44 AM
What is the "author registration" for CVPR 2026? Got no hits from a ctrl-f on the Author Guidelines page @cvprconference.bsky.social
Too bad about the data and model weights 🤷

November 3, 2025 at 1:27 PM
Too bad about the data and model weights 🤷
App L connects to the prior work. We find that a naive Fourier implementation is close to paying off in terms of throughput at current model sizes and pays off more and more with increased scale. So (again) equi models are faster than standard ones at scale. arxiv.org/abs/2510.03511

October 23, 2025 at 2:35 PM
App L connects to the prior work. We find that a naive Fourier implementation is close to paying off in terms of throughput at current model sizes and pays off more and more with increased scale. So (again) equi models are faster than standard ones at scale. arxiv.org/abs/2510.03511
More details in @erikjbekkers.bsky.social’s thread x.com/erikjbekkers... (nitter.net/erikjbekkers...). This has been a great first project for me to jump into for my postdoc in Amsterdam and I’m excited for the next steps. Great to work with this group of talented people!

October 23, 2025 at 2:35 PM
More details in @erikjbekkers.bsky.social’s thread x.com/erikjbekkers... (nitter.net/erikjbekkers...). This has been a great first project for me to jump into for my postdoc in Amsterdam and I’m excited for the next steps. Great to work with this group of talented people!
Platonic transformers use the same computational graph as ordinary transformers but are equivariant under the roto-reflectional symmetry group of a platonic solid. Equivariant positional encodings are enabled by using RoPE in rotated directions across different heads in multi-head self-attention.

October 23, 2025 at 2:35 PM
Platonic transformers use the same computational graph as ordinary transformers but are equivariant under the roto-reflectional symmetry group of a platonic solid. Equivariant positional encodings are enabled by using RoPE in rotated directions across different heads in multi-head self-attention.
Poor eigenvalues can't make it from 1 to -1. :(
October 21, 2025 at 6:04 AM
Poor eigenvalues can't make it from 1 to -1. :(
Pro tip: For good Halloween vibes, use non-normalized RoPE on images larger than your training resolution and larger than the composite period of some of the RoPE-rotations. You might get scary ghost structures in your features.

October 16, 2025 at 2:53 PM
Pro tip: For good Halloween vibes, use non-normalized RoPE on images larger than your training resolution and larger than the composite period of some of the RoPE-rotations. You might get scary ghost structures in your features.
Fair enough, I guess github.com/scipy/scipy/...

October 15, 2025 at 7:28 AM
Fair enough, I guess github.com/scipy/scipy/...

scipy deprecates `sph_harm` and replaces it with `sph_harm_y` where `n` and `m` have switched order and `theta` and `phi` have switched meaning 🙃

October 15, 2025 at 7:22 AM
scipy deprecates `sph_harm` and replaces it with `sph_harm_y` where `n` and `m` have switched order and `theta` and `phi` have switched meaning 🙃
Using Fourier theory of finite groups, we can block-diagonalize these group-circulant matrices. Hence, incorporating symmetries (group equivariance) in neural networks can make the networks faster. We used this to obtain 𝑞𝑢𝑖𝑐𝑘𝑒𝑟 𝑉𝑖𝑇𝑠. arxiv.org/abs/2505.15441

October 3, 2025 at 9:38 AM
Using Fourier theory of finite groups, we can block-diagonalize these group-circulant matrices. Hence, incorporating symmetries (group equivariance) in neural networks can make the networks faster. We used this to obtain 𝑞𝑢𝑖𝑐𝑘𝑒𝑟 𝑉𝑖𝑇𝑠. arxiv.org/abs/2505.15441
Mapping such 8-tuples to new 8-tuples that permute in the same way under transformations of the input is done by convolutions over the transformation group, or (equivalently) multiplication with group-circulant matrices.

October 3, 2025 at 9:31 AM
Mapping such 8-tuples to new 8-tuples that permute in the same way under transformations of the input is done by convolutions over the transformation group, or (equivalently) multiplication with group-circulant matrices.
Images (or image patches) are secretly multi-channel signals over groups. Below, the dihedral group of order 8: reflecting/rotating the image permutes the values in the magenta vector. So we can reshape the image into 8-tuples that all permute according to the dihedral group (edge case diagonals).

October 3, 2025 at 9:13 AM
Images (or image patches) are secretly multi-channel signals over groups. Below, the dihedral group of order 8: reflecting/rotating the image permutes the values in the magenta vector. So we can reshape the image into 8-tuples that all permute according to the dihedral group (edge case diagonals).
Had a skim of Kostelec-Rockmore. There are some interesting pointers suggesting non-triviality of fast implementations of asymptotically fast FFTs at the end. 🙃 Also, there seems to be a version that uses three 1D FFTs, but it is not as fast as possible asymptotically.

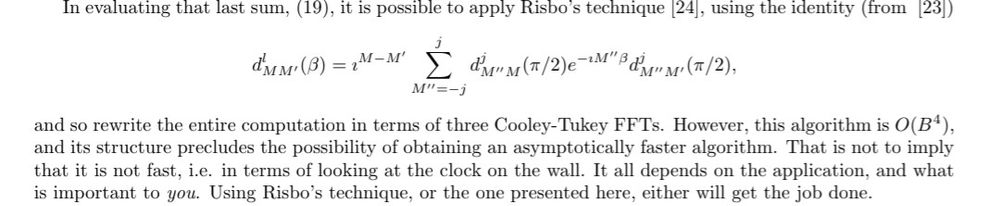
September 30, 2025 at 9:09 AM
Had a skim of Kostelec-Rockmore. There are some interesting pointers suggesting non-triviality of fast implementations of asymptotically fast FFTs at the end. 🙃 Also, there seems to be a version that uses three 1D FFTs, but it is not as fast as possible asymptotically.
Also quite generous to cite the paper as a generic reference for the term "FLOPs" 😅

September 26, 2025 at 9:24 AM
Also quite generous to cite the paper as a generic reference for the term "FLOPs" 😅
Nice LLM generated citation found by @davnords.bsky.social. I wonder who M. Lindberg and A. Andersson are...

September 26, 2025 at 9:23 AM
Nice LLM generated citation found by @davnords.bsky.social. I wonder who M. Lindberg and A. Andersson are...
I like the point made in this paragraph. It might follow that it's a good idea to build equivariant architectures that are as similar to proven non-equivariant architectures as possible.

September 22, 2025 at 6:58 PM
I like the point made in this paragraph. It might follow that it's a good idea to build equivariant architectures that are as similar to proven non-equivariant architectures as possible.
Badness is an underrated word for loss functions

September 2, 2025 at 7:34 AM
Badness is an underrated word for loss functions
I think it's common. Below is a MAE-trained ViT. I've also seen this in convnext models. In general the features are not full-rank early in these models (but they are in later layers).

August 24, 2025 at 10:07 AM
I think it's common. Below is a MAE-trained ViT. I've also seen this in convnext models. In general the features are not full-rank early in these models (but they are in later layers).
These funny layernorm (and layerscale) weight values are present in early DINOv3 layers as they were in DINOv2 by the way :)

August 24, 2025 at 8:40 AM
These funny layernorm (and layerscale) weight values are present in early DINOv3 layers as they were in DINOv2 by the way :)