



Bernhard Jaeger
@bernhard-jaeger.bsky.social
PhD student with Andreas Geiger and IMPRS-IS.
Studying embodied intelligence via autonomous driving.
Studying embodied intelligence via autonomous driving.
New SOTA in imitation learning (IL) for planning in CARLA, and an in-depth analysis of all the overfitting that is going on with IL policies.
arxiv.org/abs/2511.07292
arxiv.org/abs/2511.07292

November 11, 2025 at 1:56 PM
New SOTA in imitation learning (IL) for planning in CARLA, and an in-depth analysis of all the overfitting that is going on with IL policies.
arxiv.org/abs/2511.07292
arxiv.org/abs/2511.07292
And don't forget to cite the paper you are writing ;)

October 21, 2025 at 11:55 AM
And don't forget to cite the paper you are writing ;)
Just published the CaRL v1.1 release on GitHub. Lots of software engineering improvements, including more stable code, better determinism, and lower RAM and CPU requirements. This allowed me to double # envs. The resulting model gained a nice +9 DS boost. github.com/autonomousvi...

October 9, 2025 at 4:57 PM
Just published the CaRL v1.1 release on GitHub. Lots of software engineering improvements, including more stable code, better determinism, and lower RAM and CPU requirements. This allowed me to double # envs. The resulting model gained a nice +9 DS boost. github.com/autonomousvi...
IMPRS-IS is recruiting another round of PhD students this year.
If you are looking for a PhD position in machine learning or robotics in Germany, this is the best program to apply to.
imprs.is.mpg.de/application
If you are looking for a PhD position in machine learning or robotics in Germany, this is the best program to apply to.
imprs.is.mpg.de/application

September 16, 2025 at 1:25 PM
IMPRS-IS is recruiting another round of PhD students this year.
If you are looking for a PhD position in machine learning or robotics in Germany, this is the best program to apply to.
imprs.is.mpg.de/application
If you are looking for a PhD position in machine learning or robotics in Germany, this is the best program to apply to.
imprs.is.mpg.de/application
thinkingmachines.ai/blog/defeati...
Blog post about determinism in LLMs.
They make a very interesting point at the end about how the numerical differences between data collection and training forward passes can make an RL algorithm lose its On-policy property.
Blog post about determinism in LLMs.
They make a very interesting point at the end about how the numerical differences between data collection and training forward passes can make an RL algorithm lose its On-policy property.

September 11, 2025 at 2:29 PM
thinkingmachines.ai/blog/defeati...
Blog post about determinism in LLMs.
They make a very interesting point at the end about how the numerical differences between data collection and training forward passes can make an RL algorithm lose its On-policy property.
Blog post about determinism in LLMs.
They make a very interesting point at the end about how the numerical differences between data collection and training forward passes can make an RL algorithm lose its On-policy property.
Introducing CaRL: Learning Scalable Planning Policies with Simple Rewards
We show how simple rewards enable scaling up PPO for planning.
CaRL outperforms all prior learning-based approaches on nuPlan Val14 and CARLA longest6 v2, using less inference compute.
arxiv.org/abs/2504.17838
We show how simple rewards enable scaling up PPO for planning.
CaRL outperforms all prior learning-based approaches on nuPlan Val14 and CARLA longest6 v2, using less inference compute.
arxiv.org/abs/2504.17838
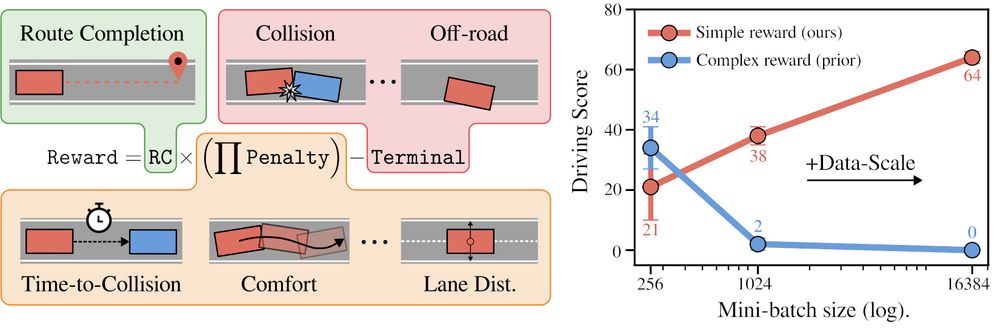
April 28, 2025 at 3:17 PM
Introducing CaRL: Learning Scalable Planning Policies with Simple Rewards
We show how simple rewards enable scaling up PPO for planning.
CaRL outperforms all prior learning-based approaches on nuPlan Val14 and CARLA longest6 v2, using less inference compute.
arxiv.org/abs/2504.17838
We show how simple rewards enable scaling up PPO for planning.
CaRL outperforms all prior learning-based approaches on nuPlan Val14 and CARLA longest6 v2, using less inference compute.
arxiv.org/abs/2504.17838
Ever wondered why RL is used in Gemini and ChatGPT even though LLMs are considered (self-)supervised terrain?
The key is that RL can optimize non-differentiable objectives, like human feedback!
We introduce RL from this alternative angle in our tutorial:
arxiv.org/abs/2312.08365
The key is that RL can optimize non-differentiable objectives, like human feedback!
We introduce RL from this alternative angle in our tutorial:
arxiv.org/abs/2312.08365

January 17, 2025 at 1:45 PM
Ever wondered why RL is used in Gemini and ChatGPT even though LLMs are considered (self-)supervised terrain?
The key is that RL can optimize non-differentiable objectives, like human feedback!
We introduce RL from this alternative angle in our tutorial:
arxiv.org/abs/2312.08365
The key is that RL can optimize non-differentiable objectives, like human feedback!
We introduce RL from this alternative angle in our tutorial:
arxiv.org/abs/2312.08365
With the code, we also released an updated technical report describing the TF++ entry to the CVPR 2024 CARLA Challenge, which won first place on the map track and second place on the sensor track.
TF++ is also SOTA on Bench2Drive and Town 13 validation.
TF++ is also SOTA on Bench2Drive and Town 13 validation.

December 16, 2024 at 4:36 PM
With the code, we also released an updated technical report describing the TF++ entry to the CVPR 2024 CARLA Challenge, which won first place on the map track and second place on the sensor track.
TF++ is also SOTA on Bench2Drive and Town 13 validation.
TF++ is also SOTA on Bench2Drive and Town 13 validation.