



Benjamin Lefaudeux 🇺🇦
@bentheegg.bsky.social
Back to France after some time in sunny California and happy Copenhagen. Mistral, Photoroom, Meta (xformers, FairScale, R&D), EyeTribe (acq) Mostly writing around AI
Worth a deep read in general, not personally completely done with it, I hope it ages well. Closing with some nice insight wrt diffusion models: they don't open up for serial awareness, since model iterates on _the same_ solution, no state space + carry over. _Less_ powerful than autoregressive

July 26, 2025 at 10:19 PM
Worth a deep read in general, not personally completely done with it, I hope it ages well. Closing with some nice insight wrt diffusion models: they don't open up for serial awareness, since model iterates on _the same_ solution, no state space + carry over. _Less_ powerful than autoregressive
Paper cannot prove its point completely since models are really good approximators, and used as such (hence a formal disprove is not enough). Pretty good hints still, makes me confident we're far from peak efficiency in most use cases (we approx serial awareness by adding tons of compute)


July 26, 2025 at 10:16 PM
Paper cannot prove its point completely since models are really good approximators, and used as such (hence a formal disprove is not enough). Pretty good hints still, makes me confident we're far from peak efficiency in most use cases (we approx serial awareness by adding tons of compute)
I think that hardware recommendations are a little naive/premature, as much as I like CPUs nothing will happen prior to needs and solutions being put on the table. Lowering is expensive and risky in general, will happen last, but at least this shows there's kryptonite to GPU dominance

July 26, 2025 at 10:10 PM
I think that hardware recommendations are a little naive/premature, as much as I like CPUs nothing will happen prior to needs and solutions being put on the table. Lowering is expensive and risky in general, will happen last, but at least this shows there's kryptonite to GPU dominance
The paper is very pedagogical, and some takeaways ring pretty reasonable. Intuition is interesting behind LLMs being just ok to not great Chess players (missing the MCTS like mechanism of specialized models), or failing to be effective at multi step reasoning prior to test time compute / CoT

July 26, 2025 at 10:08 PM
The paper is very pedagogical, and some takeaways ring pretty reasonable. Intuition is interesting behind LLMs being just ok to not great Chess players (missing the MCTS like mechanism of specialized models), or failing to be effective at multi step reasoning prior to test time compute / CoT
There are caveats in the definition of "inherently serial" problems:
- not all solutions will require serial computations, even for something outside of TC0
- approximations can fall pretty close, and oftentimes we don´t expect anything much better than an approximation
- not all solutions will require serial computations, even for something outside of TC0
- approximations can fall pretty close, and oftentimes we don´t expect anything much better than an approximation


July 26, 2025 at 10:03 PM
There are caveats in the definition of "inherently serial" problems:
- not all solutions will require serial computations, even for something outside of TC0
- approximations can fall pretty close, and oftentimes we don´t expect anything much better than an approximation
- not all solutions will require serial computations, even for something outside of TC0
- approximations can fall pretty close, and oftentimes we don´t expect anything much better than an approximation
"The Serial Scaling Hypothesis" (arxiv.org/abs/2507.125..., Liu et al) is interesting I think, not as new as it completely looks (autoregressive models are used serially, models have depth,..) but feels like a good formalization and intuition as of where current GPT based LLMs will typically fail



July 26, 2025 at 9:58 PM
"The Serial Scaling Hypothesis" (arxiv.org/abs/2507.125..., Liu et al) is interesting I think, not as new as it completely looks (autoregressive models are used serially, models have depth,..) but feels like a good formalization and intuition as of where current GPT based LLMs will typically fail
Qualitatively the chunking is real and meaningful

July 14, 2025 at 4:33 PM
Qualitatively the chunking is real and meaningful
I was a bit short on the results in this thread re:HNets, they are pretty convincing even if taking over transformers will take more validation. Of note the models become naturally robust to typos, which is a great omen

July 14, 2025 at 4:31 PM
I was a bit short on the results in this thread re:HNets, they are pretty convincing even if taking over transformers will take more validation. Of note the models become naturally robust to typos, which is a great omen
comparisons with diffusion models are not a complete hit, because the comparison is with undistilled, 1000-steps models, which nobody uses in their right mind (fast samplers & distilled models mean that images are clean in 4-8 steps, 30 tops). The fact that EBT is usable as is is already great



July 13, 2025 at 7:40 AM
comparisons with diffusion models are not a complete hit, because the comparison is with undistilled, 1000-steps models, which nobody uses in their right mind (fast samplers & distilled models mean that images are clean in 4-8 steps, 30 tops). The fact that EBT is usable as is is already great
Similarly to HNets I think the proof will be in the scaling, but there are good omens, where the technique works as you would expect it to. For instance, thinking more on out-of-distribution data has a bigger impact than on in-distribution (assuming the model was big enough to capture training set)

July 13, 2025 at 7:34 AM
Similarly to HNets I think the proof will be in the scaling, but there are good omens, where the technique works as you would expect it to. For instance, thinking more on out-of-distribution data has a bigger impact than on in-distribution (assuming the model was big enough to capture training set)
the big result is in the thinking, in that by opening up the compute valves for the more complicated cases has a meaningful effect.
Note that there's a interesting operating mode attached to being able to self-assess: generate multiple options then pick the better one (self-monte carlo ?)
Note that there's a interesting operating mode attached to being able to self-assess: generate multiple options then pick the better one (self-monte carlo ?)


July 13, 2025 at 7:32 AM
the big result is in the thinking, in that by opening up the compute valves for the more complicated cases has a meaningful effect.
Note that there's a interesting operating mode attached to being able to self-assess: generate multiple options then pick the better one (self-monte carlo ?)
Note that there's a interesting operating mode attached to being able to self-assess: generate multiple options then pick the better one (self-monte carlo ?)
the paper also feels meaningful in connection to something like transfusion arxiv.org/abs/2408.11039, which puts language tokens and continuous image representations in the same transformer. Not the case here (no mixed models), but the EBT framing does work for both representations

July 13, 2025 at 7:28 AM
the paper also feels meaningful in connection to something like transfusion arxiv.org/abs/2408.11039, which puts language tokens and continuous image representations in the same transformer. Not the case here (no mixed models), but the EBT framing does work for both representations
there are connections with diffusion/scoring all around, besides the steps to the right direction, among which the fact that noise / langevin dynamics for exploration / thinking

July 13, 2025 at 7:26 AM
there are connections with diffusion/scoring all around, besides the steps to the right direction, among which the fact that noise / langevin dynamics for exploration / thinking
Forgot in the above, but assuming you can trust the model it also gives you 3: how truthful is the prediction (assuming 1 and 2 don´t team up effectively)
The paper runs pretty deep, besides the initial handwave which is nice and intuitive (model essentially predicts a step, not final distribution)
The paper runs pretty deep, besides the initial handwave which is nice and intuitive (model essentially predicts a step, not final distribution)


July 13, 2025 at 7:23 AM
Forgot in the above, but assuming you can trust the model it also gives you 3: how truthful is the prediction (assuming 1 and 2 don´t team up effectively)
The paper runs pretty deep, besides the initial handwave which is nice and intuitive (model essentially predicts a step, not final distribution)
The paper runs pretty deep, besides the initial handwave which is nice and intuitive (model essentially predicts a step, not final distribution)
Looks like this, and now the even more interesting bit is that it doesn't have to be about language tokens, works across modalities


July 13, 2025 at 6:57 AM
Looks like this, and now the even more interesting bit is that it doesn't have to be about language tokens, works across modalities
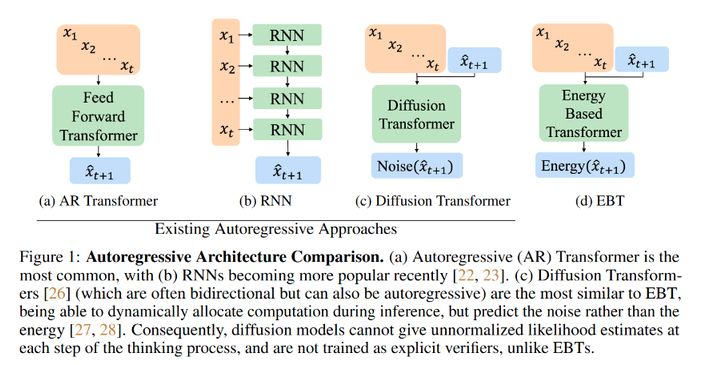
EBT has pretty much nothing to do with HNets, but it's also a recent (July) paper which struck a chord with me. Idea is to reconcile autoregressive crossentropy trained transformers (aka all LLMs these days) with scoring models (aka diffusion)
July 13, 2025 at 6:36 AM
EBT has pretty much nothing to do with HNets, but it's also a recent (July) paper which struck a chord with me. Idea is to reconcile autoregressive crossentropy trained transformers (aka all LLMs these days) with scoring models (aka diffusion)
We shipped a great volumetric shadow engine also, diffusion based. Not an entirely new application but I think we were one of the firsts making this a lasting product, been a great success ever since

July 13, 2025 at 6:33 AM
We shipped a great volumetric shadow engine also, diffusion based. Not an entirely new application but I think we were one of the firsts making this a lasting product, been a great success ever since
I think we invented the "AI background" workload, now called Studio, first shipped end of 2022, then perfected over the years. In any case this was and is a great success for the company, super useful to users and a practical day today impact of genAI in the life of millions

July 13, 2025 at 6:33 AM
I think we invented the "AI background" workload, now called Studio, first shipped end of 2022, then perfected over the years. In any case this was and is a great success for the company, super useful to users and a practical day today impact of genAI in the life of millions
Now with some pictures, not giving the paper justice as there's a lot more than meets the eyes. In particular I think the Mamba encoding layer is probably a great fit, cosine sim for boundaries (instead of entropy like in byte latent) feels meaningful, and smoothing op is this "one last trick"



July 13, 2025 at 6:31 AM
Now with some pictures, not giving the paper justice as there's a lot more than meets the eyes. In particular I think the Mamba encoding layer is probably a great fit, cosine sim for boundaries (instead of entropy like in byte latent) feels meaningful, and smoothing op is this "one last trick"
How this seems to work is a bit nuts macroscopically, because it seems that they software defined ondevice scheduling. I'm actually not a modern cuda specialist, but high level this looks very modern to me. The only ondevice scheduling that nvidia GPUs will do by default is waaay simpler than that

June 24, 2025 at 8:11 PM
How this seems to work is a bit nuts macroscopically, because it seems that they software defined ondevice scheduling. I'm actually not a modern cuda specialist, but high level this looks very modern to me. The only ondevice scheduling that nvidia GPUs will do by default is waaay simpler than that
related to the above, really powerful abstraction, I'm pretty amazed at this point if it's automated

June 24, 2025 at 8:06 PM
related to the above, really powerful abstraction, I'm pretty amazed at this point if it's automated
in particular this has been a focus recently with some ad hoc kernels, but the solution proposed here seems more generic

June 24, 2025 at 8:00 PM
in particular this has been a focus recently with some ad hoc kernels, but the solution proposed here seems more generic
the "megakernel" argument is not too convincing at first read I find (it's not a single kernel in the cuda sense, and cuda graphs or dependent kernels already allow for queued GPU work), but this illustration from the accompanying blog post make it make sense zhihaojia.medium.com/compiling-ll...

June 24, 2025 at 7:57 PM
the "megakernel" argument is not too convincing at first read I find (it's not a single kernel in the cuda sense, and cuda graphs or dependent kernels already allow for queued GPU work), but this illustration from the accompanying blog post make it make sense zhihaojia.medium.com/compiling-ll...
Means you can have a UI and do some work from there, or do it all programmatically/at scale from the reader and writer abstractions which are part of the release.

June 23, 2025 at 10:02 AM
Means you can have a UI and do some work from there, or do it all programmatically/at scale from the reader and writer abstractions which are part of the release.
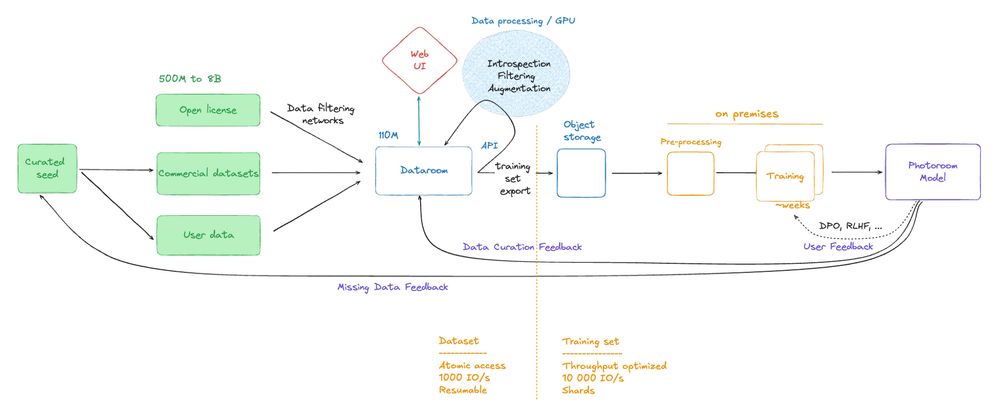
What we have is something more like this. Dataroom sits in the middle, it's a vectorDB with an accompanying service layer. We can iterate on the data (it's a DB, you can add/remove/mutate attributes as you want), at GenAI scale (110M base samples at the moment, .5B pairs)
June 23, 2025 at 10:01 AM
What we have is something more like this. Dataroom sits in the middle, it's a vectorDB with an accompanying service layer. We can iterate on the data (it's a DB, you can add/remove/mutate attributes as you want), at GenAI scale (110M base samples at the moment, .5B pairs)