



@benlonnqvist.bsky.social
PhD candidate @EPFL with Martin Schrimpf and Michael Herzog. NeuroAI, vision, ML. https://benlonnqvist.github.io/
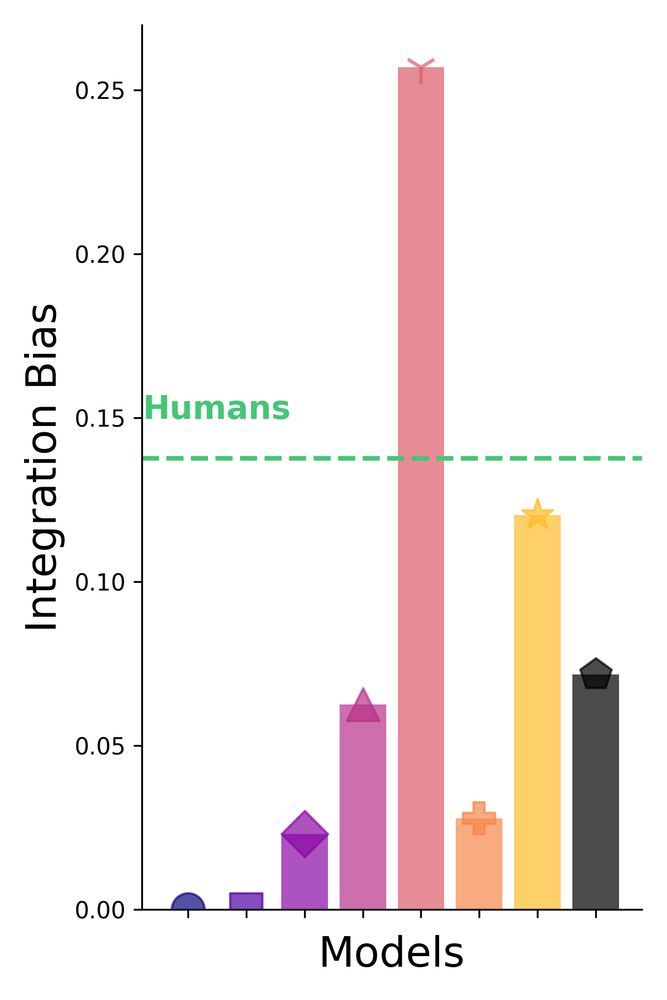
Can we teach models contour integration directly? Yup! Models trained explicitly on fragmented images developed strong integration biases—and a stronger shape bias than previous shape-focused training methods! Good news if you want to study contour integration with models!🎯


April 22, 2025 at 12:33 PM
Can we teach models contour integration directly? Yup! Models trained explicitly on fragmented images developed strong integration biases—and a stronger shape bias than previous shape-focused training methods! Good news if you want to study contour integration with models!🎯
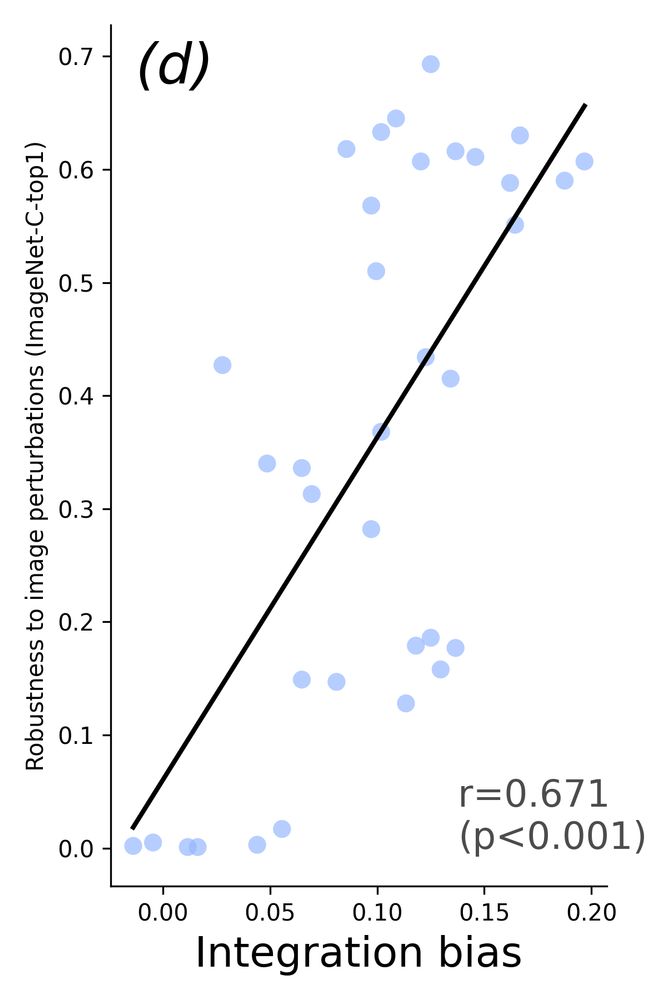
Interestingly, models with high integration bias don’t just recognize fragmented images better—they’re also more robust against typical image distortions. Human-like integration = general robustness? 🛡️🤔
April 22, 2025 at 12:33 PM
Interestingly, models with high integration bias don’t just recognize fragmented images better—they’re also more robust against typical image distortions. Human-like integration = general robustness? 🛡️🤔
We compute this bias as a difference between the two conditions and find that it is strongly related to overall performance, and to model training dataset size! This suggests that this mechanism might be learned, rather than needing to be hardcoded! 😳



April 22, 2025 at 12:33 PM
We compute this bias as a difference between the two conditions and find that it is strongly related to overall performance, and to model training dataset size! This suggests that this mechanism might be learned, rather than needing to be hardcoded! 😳
One secret ingredient of human vision: integration bias. Humans (and some models!) are much better at recognizing fragments aligned along object contours (segments) compared to directionless dots (phosphenes).🌱🧠

April 22, 2025 at 12:33 PM
One secret ingredient of human vision: integration bias. Humans (and some models!) are much better at recognizing fragments aligned along object contours (segments) compared to directionless dots (phosphenes).🌱🧠
Why do some models perform better? It’s not fancy architectures but rather the size of the training dataset. Models trained on billions of images start catching up to humans! 📚✨



April 22, 2025 at 12:33 PM
Why do some models perform better? It’s not fancy architectures but rather the size of the training dataset. Models trained on billions of images start catching up to humans! 📚✨
When images become fragmented, human accuracy stays impressively stable. But most models plummet to chance performance. Exception? GPT-4o (purple). Surprisingly human-like! 😲



April 22, 2025 at 12:33 PM
When images become fragmented, human accuracy stays impressively stable. But most models plummet to chance performance. Exception? GPT-4o (purple). Surprisingly human-like! 😲
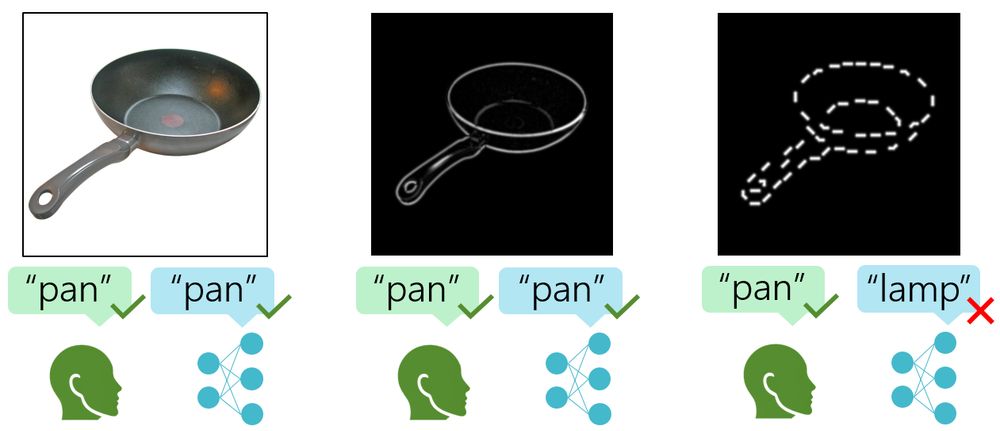
We tested 50 humans and over 1,000 AI models on a task where images are fragmented into tiny bits in two conditions: phosphenes (directionless) and segments (directional) segments. Humans see objects easily—AI, not so much! Most fail catastrophically! How just catastrophically..?

April 22, 2025 at 12:33 PM
We tested 50 humans and over 1,000 AI models on a task where images are fragmented into tiny bits in two conditions: phosphenes (directionless) and segments (directional) segments. Humans see objects easily—AI, not so much! Most fail catastrophically! How just catastrophically..?
AI vision is insanely good nowadays—but is it really like human vision or something else entirely? In our new pre-print, we pinpoint a fundamental visual mechanism that's trivial for humans yet causes most models to fail spectacularly. Let's dive in👇🧠
[https://arxiv.org/abs/2504.05253]
[https://arxiv.org/abs/2504.05253]
April 22, 2025 at 12:33 PM
AI vision is insanely good nowadays—but is it really like human vision or something else entirely? In our new pre-print, we pinpoint a fundamental visual mechanism that's trivial for humans yet causes most models to fail spectacularly. Let's dive in👇🧠
[https://arxiv.org/abs/2504.05253]
[https://arxiv.org/abs/2504.05253]