




Bo Liu (Benjamin Liu)
@benjamin-eecs.bsky.social
Reinforcement Learning PhD @NUSingapore | Undergrad @PKU1898 | Building autonomous decision making systems | Ex intern @MSFTResearch @deepseek_ai | DeepSeek-V2, DeepSeek-VL, DeepSeek-Prover
Pinned
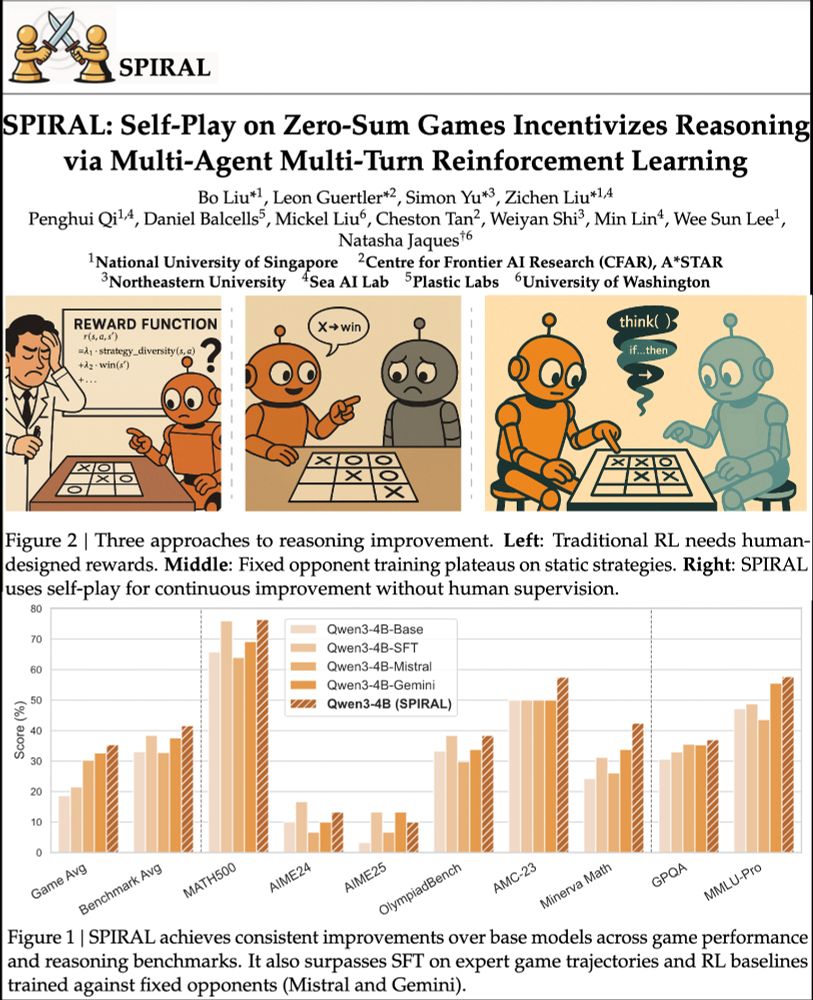
We're excited about self-play unlocking continuously improving agents. RL selects CoT patterns from LLMs. Games=perfect testing grounds.
SPIRAL: models learn via self-competition. Kuhn Poker → +8.7% math, +18.1 Minerva Math! 🃏
Paper: huggingface.co/papers/2506....
Code: github.com/spiral-rl/spiral
SPIRAL: models learn via self-competition. Kuhn Poker → +8.7% math, +18.1 Minerva Math! 🃏
Paper: huggingface.co/papers/2506....
Code: github.com/spiral-rl/spiral
We're excited about self-play unlocking continuously improving agents. RL selects CoT patterns from LLMs. Games=perfect testing grounds.
SPIRAL: models learn via self-competition. Kuhn Poker → +8.7% math, +18.1 Minerva Math! 🃏
Paper: huggingface.co/papers/2506....
Code: github.com/spiral-rl/spiral
SPIRAL: models learn via self-competition. Kuhn Poker → +8.7% math, +18.1 Minerva Math! 🃏
Paper: huggingface.co/papers/2506....
Code: github.com/spiral-rl/spiral
July 1, 2025 at 8:11 PM
We're excited about self-play unlocking continuously improving agents. RL selects CoT patterns from LLMs. Games=perfect testing grounds.
SPIRAL: models learn via self-competition. Kuhn Poker → +8.7% math, +18.1 Minerva Math! 🃏
Paper: huggingface.co/papers/2506....
Code: github.com/spiral-rl/spiral
SPIRAL: models learn via self-competition. Kuhn Poker → +8.7% math, +18.1 Minerva Math! 🃏
Paper: huggingface.co/papers/2506....
Code: github.com/spiral-rl/spiral
Reposted by Bo Liu (Benjamin Liu)

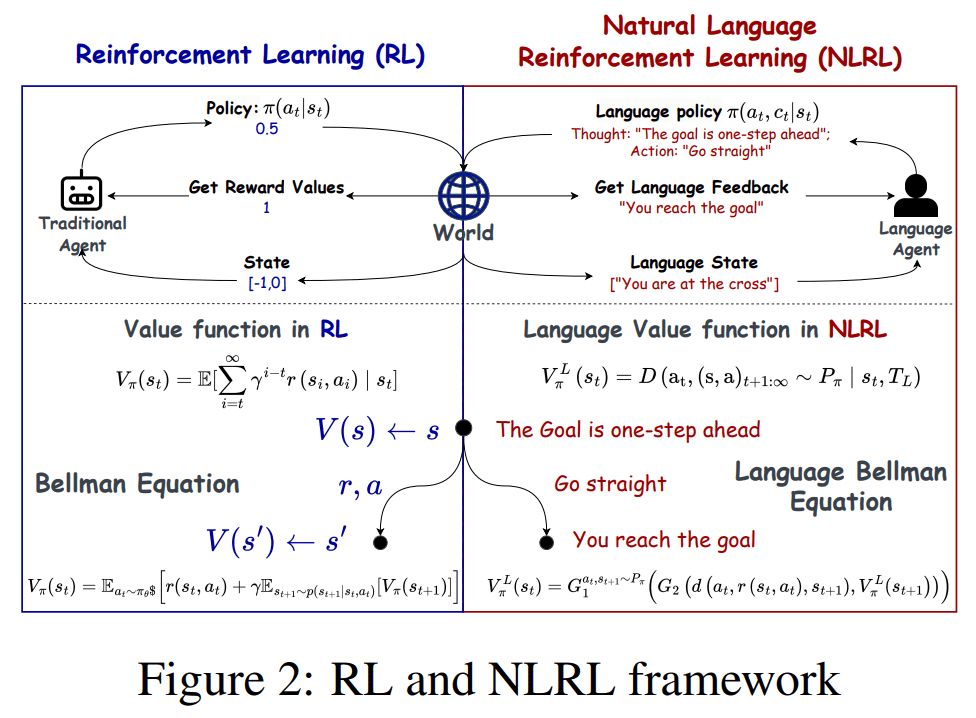
Natural Language Reinforcement Learning (NLRL) redefines Reinforcement Learning (RL).
NLRL's main idea:
The core parts of RL like goals, strategies, and evaluation methods are reimagined using natural language instead of rigid math.
Let's explore this approach more precisely🧵
NLRL's main idea:
The core parts of RL like goals, strategies, and evaluation methods are reimagined using natural language instead of rigid math.
Let's explore this approach more precisely🧵
November 29, 2024 at 3:06 PM
Natural Language Reinforcement Learning (NLRL) redefines Reinforcement Learning (RL).
NLRL's main idea:
The core parts of RL like goals, strategies, and evaluation methods are reimagined using natural language instead of rigid math.
Let's explore this approach more precisely🧵
NLRL's main idea:
The core parts of RL like goals, strategies, and evaluation methods are reimagined using natural language instead of rigid math.
Let's explore this approach more precisely🧵