



Beatrix M. G. Nielsen
@beatrixmgn.bsky.social
PhD student in machine learning at DTU, Copenhagen.
Especially interested in model representations.
Especially interested in model representations.
2/5
We prove that a small KL divergence between models is not enough to guarantee similar representations. Here is an example of how to construct two models with small KL divergence, but representations which are far from being linear transformations of each other.
We prove that a small KL divergence between models is not enough to guarantee similar representations. Here is an example of how to construct two models with small KL divergence, but representations which are far from being linear transformations of each other.

October 21, 2025 at 5:48 AM
2/5
We prove that a small KL divergence between models is not enough to guarantee similar representations. Here is an example of how to construct two models with small KL divergence, but representations which are far from being linear transformations of each other.
We prove that a small KL divergence between models is not enough to guarantee similar representations. Here is an example of how to construct two models with small KL divergence, but representations which are far from being linear transformations of each other.
Thank you to everyone who came to talk to us at ACL!
Very happy that so many people are interested in our work :D
If you didn’t manage to have a look yet: This work is relevant if you want to compare representations in language models, and it can be read here: arxiv.org/abs/2502.10201
Very happy that so many people are interested in our work :D
If you didn’t manage to have a look yet: This work is relevant if you want to compare representations in language models, and it can be read here: arxiv.org/abs/2502.10201

August 1, 2025 at 8:02 PM
Thank you to everyone who came to talk to us at ACL!
Very happy that so many people are interested in our work :D
If you didn’t manage to have a look yet: This work is relevant if you want to compare representations in language models, and it can be read here: arxiv.org/abs/2502.10201
Very happy that so many people are interested in our work :D
If you didn’t manage to have a look yet: This work is relevant if you want to compare representations in language models, and it can be read here: arxiv.org/abs/2502.10201
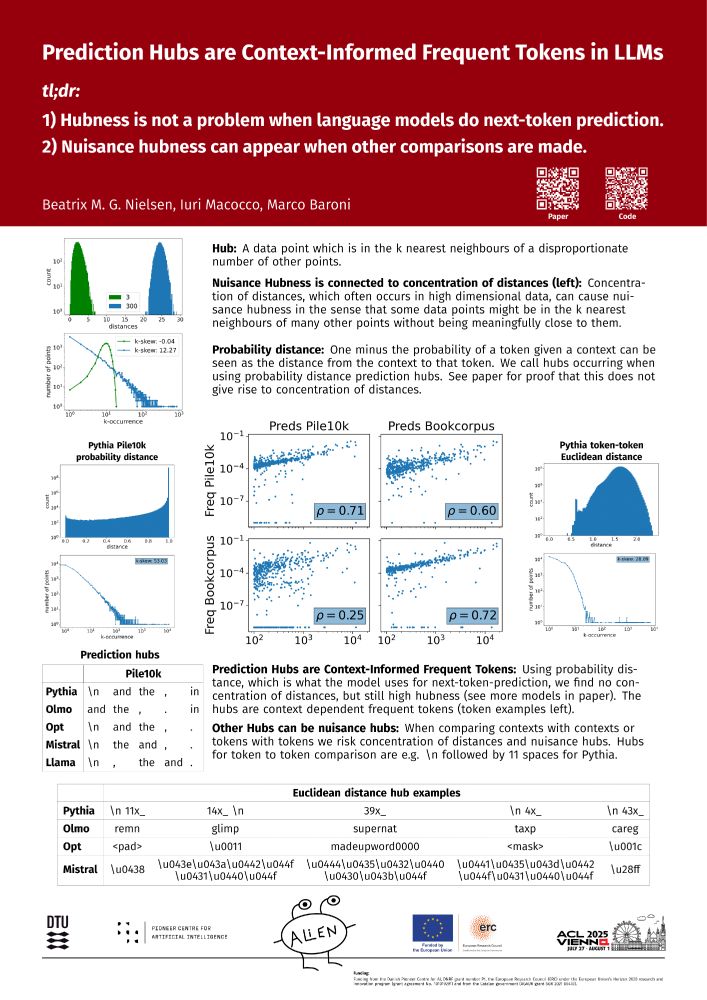
Our paper "Prediction Hubs are Context-Informed Frequent Tokens in LLMs" has been accepted at ACL 2025!
Main points:
1. Hubness is not a problem when language models do next-token prediction.
2. Nuisance hubness can appear when other comparisons are made.
Main points:
1. Hubness is not a problem when language models do next-token prediction.
2. Nuisance hubness can appear when other comparisons are made.
July 7, 2025 at 10:48 AM
Our paper "Prediction Hubs are Context-Informed Frequent Tokens in LLMs" has been accepted at ACL 2025!
Main points:
1. Hubness is not a problem when language models do next-token prediction.
2. Nuisance hubness can appear when other comparisons are made.
Main points:
1. Hubness is not a problem when language models do next-token prediction.
2. Nuisance hubness can appear when other comparisons are made.