


@bearseascape.bsky.social
October 22, 2025 at 7:09 AM
Takeaways:
Despite massive advances in scale, architecture, & training - from BERT to Llama-3.1 - transformer models organize linguistic information the same.
The classical NLP pipeline isn't an artifact of early models; it persists in modern ones & seems fundamental to NTP.
Despite massive advances in scale, architecture, & training - from BERT to Llama-3.1 - transformer models organize linguistic information the same.
The classical NLP pipeline isn't an artifact of early models; it persists in modern ones & seems fundamental to NTP.
October 22, 2025 at 7:09 AM
Takeaways:
Despite massive advances in scale, architecture, & training - from BERT to Llama-3.1 - transformer models organize linguistic information the same.
The classical NLP pipeline isn't an artifact of early models; it persists in modern ones & seems fundamental to NTP.
Despite massive advances in scale, architecture, & training - from BERT to Llama-3.1 - transformer models organize linguistic information the same.
The classical NLP pipeline isn't an artifact of early models; it persists in modern ones & seems fundamental to NTP.
We also looked at attention head outputs vs the residual stream, and find that linguistic information lives primarily in the residual stream.
Read the paper for our full analysis including steering vectors, intrinsic dimensionality, and training dynamics (in OLMo2 and Pythia)!
Read the paper for our full analysis including steering vectors, intrinsic dimensionality, and training dynamics (in OLMo2 and Pythia)!


October 22, 2025 at 7:09 AM
We also looked at attention head outputs vs the residual stream, and find that linguistic information lives primarily in the residual stream.
Read the paper for our full analysis including steering vectors, intrinsic dimensionality, and training dynamics (in OLMo2 and Pythia)!
Read the paper for our full analysis including steering vectors, intrinsic dimensionality, and training dynamics (in OLMo2 and Pythia)!
The probes show that lexical info concentrates in early layers and becomes increasingly nonlinear deeper in the network. Inflectional info remains linearly accessible throughout all layers.

October 22, 2025 at 7:09 AM
The probes show that lexical info concentrates in early layers and becomes increasingly nonlinear deeper in the network. Inflectional info remains linearly accessible throughout all layers.
After confirming that modern LMs rediscover the classical NLP pipeline, we investigated how they encode lemma (word meaning) vs inflectional morphology (word form).
We looked at 6 typologically diverse languages: English, Chinese, German, French, Russian and Turkish.
We looked at 6 typologically diverse languages: English, Chinese, German, French, Russian and Turkish.
October 22, 2025 at 7:09 AM
After confirming that modern LMs rediscover the classical NLP pipeline, we investigated how they encode lemma (word meaning) vs inflectional morphology (word form).
We looked at 6 typologically diverse languages: English, Chinese, German, French, Russian and Turkish.
We looked at 6 typologically diverse languages: English, Chinese, German, French, Russian and Turkish.
But there's an important difference:
📊 Large modern models compress the entire pipeline into fewer layers. Information emerges earlier and consolidates faster.
Same hierarchical organization, but more efficient. Models seem to have gotten better at building useful representations quickly.
📊 Large modern models compress the entire pipeline into fewer layers. Information emerges earlier and consolidates faster.
Same hierarchical organization, but more efficient. Models seem to have gotten better at building useful representations quickly.
October 22, 2025 at 7:09 AM
But there's an important difference:
📊 Large modern models compress the entire pipeline into fewer layers. Information emerges earlier and consolidates faster.
Same hierarchical organization, but more efficient. Models seem to have gotten better at building useful representations quickly.
📊 Large modern models compress the entire pipeline into fewer layers. Information emerges earlier and consolidates faster.
Same hierarchical organization, but more efficient. Models seem to have gotten better at building useful representations quickly.
The hierarchy is remarkably stable across all models:
Early layers capture syntax (POS, dependencies) -> Middle layers handle semantics & entities (NER, SRL) -> Later layers encode discourse (coreference, relations)
This holds whether you're looking at BERT, Qwen2.5 or OLMo 2.
Early layers capture syntax (POS, dependencies) -> Middle layers handle semantics & entities (NER, SRL) -> Later layers encode discourse (coreference, relations)
This holds whether you're looking at BERT, Qwen2.5 or OLMo 2.

October 22, 2025 at 7:09 AM
The hierarchy is remarkably stable across all models:
Early layers capture syntax (POS, dependencies) -> Middle layers handle semantics & entities (NER, SRL) -> Later layers encode discourse (coreference, relations)
This holds whether you're looking at BERT, Qwen2.5 or OLMo 2.
Early layers capture syntax (POS, dependencies) -> Middle layers handle semantics & entities (NER, SRL) -> Later layers encode discourse (coreference, relations)
This holds whether you're looking at BERT, Qwen2.5 or OLMo 2.
🔬We probed 25 models, across 8 linguistic tasks spanning syntax, semantics, and discourse.
🔍The answer: YES. Modern LMs consistently rediscover the classical NLP pipeline.
🔍The answer: YES. Modern LMs consistently rediscover the classical NLP pipeline.

October 22, 2025 at 7:09 AM
🔬We probed 25 models, across 8 linguistic tasks spanning syntax, semantics, and discourse.
🔍The answer: YES. Modern LMs consistently rediscover the classical NLP pipeline.
🔍The answer: YES. Modern LMs consistently rediscover the classical NLP pipeline.
🎯 These patterns hold across all 16 models - despite huge differences (encoder/decoder, 100M->8B params, instruction-tuning)
Despite rapid advances since BERT, certain aspects of how LMs process language remain remarkably consistent💡
Paper: arxiv.org/abs/2506.02132
Code: github.com/ml5885/model...
Despite rapid advances since BERT, certain aspects of how LMs process language remain remarkably consistent💡
Paper: arxiv.org/abs/2506.02132
Code: github.com/ml5885/model...

Model Internal Sleuthing: Finding Lexical Identity and Inflectional Morphology in Modern Language Models
Large transformer-based language models dominate modern NLP, yet our understanding of how they encode linguistic information is rooted in studies of early models like BERT and GPT-2. To better underst...
arxiv.org
June 4, 2025 at 5:38 PM
🎯 These patterns hold across all 16 models - despite huge differences (encoder/decoder, 100M->8B params, instruction-tuning)
Despite rapid advances since BERT, certain aspects of how LMs process language remain remarkably consistent💡
Paper: arxiv.org/abs/2506.02132
Code: github.com/ml5885/model...
Despite rapid advances since BERT, certain aspects of how LMs process language remain remarkably consistent💡
Paper: arxiv.org/abs/2506.02132
Code: github.com/ml5885/model...
We also tested how tokenization affects linguistic representations using analogy tasks (king - man + woman = ?) 👑
Whole-word embeddings consistently outperform averaged subtoken representations - linguistic regularities are stored at the word level, not compositionally!
Whole-word embeddings consistently outperform averaged subtoken representations - linguistic regularities are stored at the word level, not compositionally!

June 4, 2025 at 5:38 PM
We also tested how tokenization affects linguistic representations using analogy tasks (king - man + woman = ?) 👑
Whole-word embeddings consistently outperform averaged subtoken representations - linguistic regularities are stored at the word level, not compositionally!
Whole-word embeddings consistently outperform averaged subtoken representations - linguistic regularities are stored at the word level, not compositionally!
🔬 We also measured intrinsic dimensionality across layers using PCA.
🎢 Some models (GPT-2, OLMo-2) compress their middle layers to just 1-2 dimensions capturing 50-99% of variance, then expand again! This bottleneck aligns with where grammar is most accessible & lexical info is most nonlinear.
🎢 Some models (GPT-2, OLMo-2) compress their middle layers to just 1-2 dimensions capturing 50-99% of variance, then expand again! This bottleneck aligns with where grammar is most accessible & lexical info is most nonlinear.

June 4, 2025 at 5:38 PM
🔬 We also measured intrinsic dimensionality across layers using PCA.
🎢 Some models (GPT-2, OLMo-2) compress their middle layers to just 1-2 dimensions capturing 50-99% of variance, then expand again! This bottleneck aligns with where grammar is most accessible & lexical info is most nonlinear.
🎢 Some models (GPT-2, OLMo-2) compress their middle layers to just 1-2 dimensions capturing 50-99% of variance, then expand again! This bottleneck aligns with where grammar is most accessible & lexical info is most nonlinear.
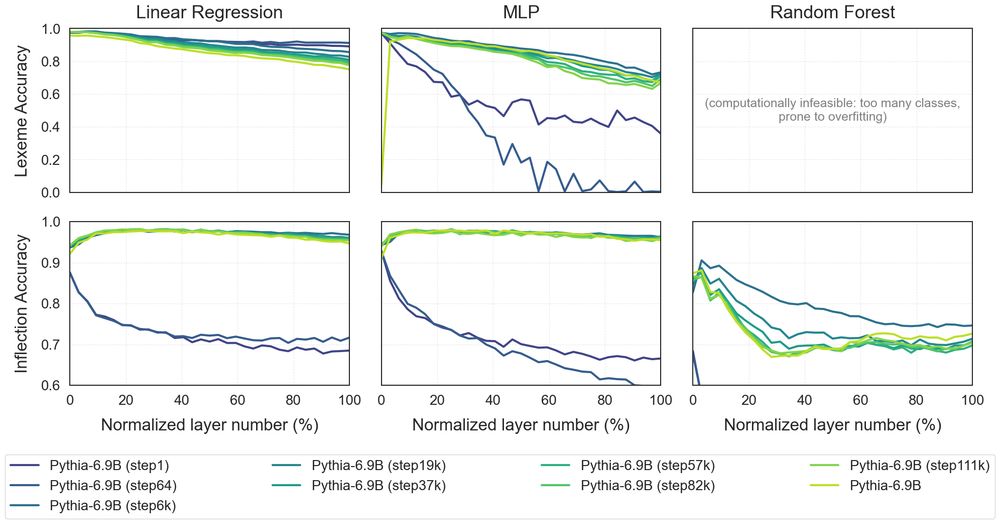
To understand when these patterns emerge, we analyze OLMo-2 & Pythia checkpoints throughout pre-training. 👶👦👨👨🦳
We find that models learn this linguistic organization in the first few thousand steps! But this encoding slowly degrades as training progresses. 📉
We find that models learn this linguistic organization in the first few thousand steps! But this encoding slowly degrades as training progresses. 📉

June 4, 2025 at 5:38 PM
To understand when these patterns emerge, we analyze OLMo-2 & Pythia checkpoints throughout pre-training. 👶👦👨👨🦳
We find that models learn this linguistic organization in the first few thousand steps! But this encoding slowly degrades as training progresses. 📉
We find that models learn this linguistic organization in the first few thousand steps! But this encoding slowly degrades as training progresses. 📉
🤔 But are classifiers actually learning linguistic patterns or just memorizing?
📈 We ran control tasks with random labels - inflection classifiers show high selectivity (real learning!) while lemma classifiers don't (memorization).
📈 We ran control tasks with random labels - inflection classifiers show high selectivity (real learning!) while lemma classifiers don't (memorization).

June 4, 2025 at 5:38 PM
🤔 But are classifiers actually learning linguistic patterns or just memorizing?
📈 We ran control tasks with random labels - inflection classifiers show high selectivity (real learning!) while lemma classifiers don't (memorization).
📈 We ran control tasks with random labels - inflection classifiers show high selectivity (real learning!) while lemma classifiers don't (memorization).
Key findings 📊:
- 📉 Lexical info concentrates in early layers & becomes increasingly nonlinear in deeper layers
- ✨ Inflection (grammar) stays linearly accessible throughout ALL layers
- Models memorize word identity but learn generalizable patterns for inflections!
- 📉 Lexical info concentrates in early layers & becomes increasingly nonlinear in deeper layers
- ✨ Inflection (grammar) stays linearly accessible throughout ALL layers
- Models memorize word identity but learn generalizable patterns for inflections!

June 4, 2025 at 5:38 PM
Key findings 📊:
- 📉 Lexical info concentrates in early layers & becomes increasingly nonlinear in deeper layers
- ✨ Inflection (grammar) stays linearly accessible throughout ALL layers
- Models memorize word identity but learn generalizable patterns for inflections!
- 📉 Lexical info concentrates in early layers & becomes increasingly nonlinear in deeper layers
- ✨ Inflection (grammar) stays linearly accessible throughout ALL layers
- Models memorize word identity but learn generalizable patterns for inflections!
🧐 How do modern LMs encode linguistic information? Do they represent words grouped by meaning (walk/walked) or grammar (walked/jumped)?
We trained classifiers on hidden activations from 16 models (BERT -> Llama 3.1) to find out how they store word identity (lexemes) vs. grammar (inflections).
We trained classifiers on hidden activations from 16 models (BERT -> Llama 3.1) to find out how they store word identity (lexemes) vs. grammar (inflections).

June 4, 2025 at 5:20 PM
🧐 How do modern LMs encode linguistic information? Do they represent words grouped by meaning (walk/walked) or grammar (walked/jumped)?
We trained classifiers on hidden activations from 16 models (BERT -> Llama 3.1) to find out how they store word identity (lexemes) vs. grammar (inflections).
We trained classifiers on hidden activations from 16 models (BERT -> Llama 3.1) to find out how they store word identity (lexemes) vs. grammar (inflections).