



Artur
@backdeluca.bsky.social
Reposted by Artur

Positional Attention is accepted at ICML 2025! Thanks to all co-authors for the hard work (64 pages). If you’d like to read the paper, check the quoted post.
May 1, 2025 at 1:22 PM
Positional Attention is accepted at ICML 2025! Thanks to all co-authors for the hard work (64 pages). If you’d like to read the paper, check the quoted post.
Reposted by Artur
Can neural networks learn to copy or permute an input exactly with high probability? We study this basic and fundamental question in "Exact Learning of Permutations for Nonzero Binary Inputs with Logarithmic Training Size and Quadratic Ensemble Complexity"
Link: arxiv.org/abs/2502.16763
Link: arxiv.org/abs/2502.16763


February 25, 2025 at 2:42 AM
Can neural networks learn to copy or permute an input exactly with high probability? We study this basic and fundamental question in "Exact Learning of Permutations for Nonzero Binary Inputs with Logarithmic Training Size and Quadratic Ensemble Complexity"
Link: arxiv.org/abs/2502.16763
Link: arxiv.org/abs/2502.16763
Reposted by Artur
Positional Attention: Expressivity and Learnability of Algorithmic Computation (v2)
We study the effect of using only fixed positional encodings in the Transformer architecture for computational tasks. These positional encodings remain the same across layers.
We study the effect of using only fixed positional encodings in the Transformer architecture for computational tasks. These positional encodings remain the same across layers.


February 4, 2025 at 4:59 AM
Positional Attention: Expressivity and Learnability of Algorithmic Computation (v2)
We study the effect of using only fixed positional encodings in the Transformer architecture for computational tasks. These positional encodings remain the same across layers.
We study the effect of using only fixed positional encodings in the Transformer architecture for computational tasks. These positional encodings remain the same across layers.
Reposted by Artur
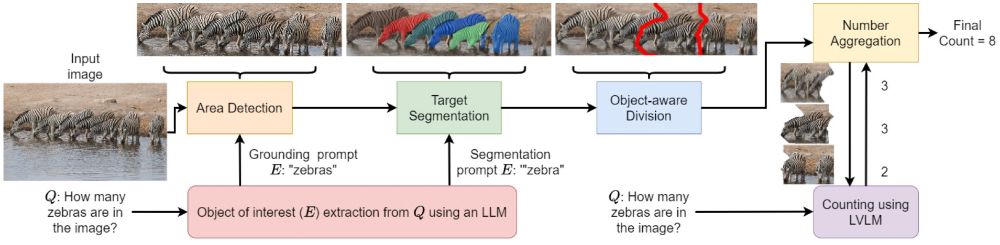
LVLM-COUNT: Enhancing the Counting Ability of Large Vision-Language Models
By splitting the image into sub-images using a novel object-aware division technique, we can enhance the performance of LVLMs such as GPT-4o and Gemini Pro 1.5.
Link: arxiv.org/abs/2412.00686
By splitting the image into sub-images using a novel object-aware division technique, we can enhance the performance of LVLMs such as GPT-4o and Gemini Pro 1.5.
Link: arxiv.org/abs/2412.00686



December 3, 2024 at 4:03 AM
LVLM-COUNT: Enhancing the Counting Ability of Large Vision-Language Models
By splitting the image into sub-images using a novel object-aware division technique, we can enhance the performance of LVLMs such as GPT-4o and Gemini Pro 1.5.
Link: arxiv.org/abs/2412.00686
By splitting the image into sub-images using a novel object-aware division technique, we can enhance the performance of LVLMs such as GPT-4o and Gemini Pro 1.5.
Link: arxiv.org/abs/2412.00686
Reposted by Artur

Unless we hold reviewers and ACs accountable, especially ACs in this case, the acceptance of a paper will be determined by whether your paper got active or inactive reviewers/ac. This is even worse and more frustrating than the usual reviewer quality lottery.

✍️ Reminder to reviewers: Check author responses to your reviews, and ask follow up questions if needed.
50% of papers have discussion - let’s bring this number up!
50% of papers have discussion - let’s bring this number up!
November 28, 2024 at 2:29 PM
Unless we hold reviewers and ACs accountable, especially ACs in this case, the acceptance of a paper will be determined by whether your paper got active or inactive reviewers/ac. This is even worse and more frustrating than the usual reviewer quality lottery.