



Arkadiy Saakyan
@asaakyan.bsky.social
PhD student at Columbia University working on human-AI collaboration, AI creativity and explainability. prev. intern @GoogleDeepMind, @AmazonScience
asaakyan.github.io
asaakyan.github.io
We didn’t observe this negative relationship between n-gram novelty and pragmaticality in humans, only in open-source LLMs!
November 9, 2025 at 6:55 PM
We didn’t observe this negative relationship between n-gram novelty and pragmaticality in humans, only in open-source LLMs!
See more details in the paper!
Work with my amazing mentors & collaborators @najoung.bsky.social, @tuhinchakr.bsky.social, Smaranda Muresan
Paper link: www.arxiv.org/abs/2509.22641
Github link: github.com/asaakyan/ngr...
Work with my amazing mentors & collaborators @najoung.bsky.social, @tuhinchakr.bsky.social, Smaranda Muresan
Paper link: www.arxiv.org/abs/2509.22641
Github link: github.com/asaakyan/ngr...

Death of the Novel(ty): Beyond n-Gram Novelty as a Metric for Textual Creativity
N-gram novelty is widely used to evaluate language models' ability to generate text outside of their training data. More recently, it has also been adopted as a metric for measuring textual creativity...
www.arxiv.org
November 4, 2025 at 3:08 PM
See more details in the paper!
Work with my amazing mentors & collaborators @najoung.bsky.social, @tuhinchakr.bsky.social, Smaranda Muresan
Paper link: www.arxiv.org/abs/2509.22641
Github link: github.com/asaakyan/ngr...
Work with my amazing mentors & collaborators @najoung.bsky.social, @tuhinchakr.bsky.social, Smaranda Muresan
Paper link: www.arxiv.org/abs/2509.22641
Github link: github.com/asaakyan/ngr...
On OOD dataset StyleMirror, we find that LLM-Judge novelty scores are associated with expert preferences to a larger extent than a previously proposed n-gram novelty metric, Creativity Index, suggesting our operationalization yields a more aligned metric for textual creativity.

November 4, 2025 at 3:08 PM
On OOD dataset StyleMirror, we find that LLM-Judge novelty scores are associated with expert preferences to a larger extent than a previously proposed n-gram novelty metric, Creativity Index, suggesting our operationalization yields a more aligned metric for textual creativity.
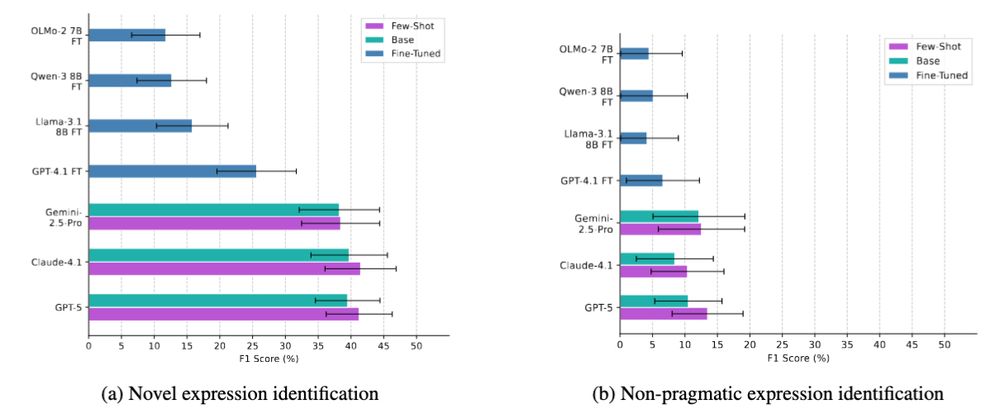
Writing quality reward model scores are associated with both creativity and pragmaticality judgements, but are not interpretable. LLM-judge can replicate some expert novelty judgements but struggle with identifying non-pragmatic expressions.
November 4, 2025 at 3:08 PM
Writing quality reward model scores are associated with both creativity and pragmaticality judgements, but are not interpretable. LLM-judge can replicate some expert novelty judgements but struggle with identifying non-pragmatic expressions.
In a follow-up study with GPT-5 and Claude, we observe that the rate of human-judged creative expressions in AI-written text is significantly lower than in human-written text.

November 4, 2025 at 3:08 PM
In a follow-up study with GPT-5 and Claude, we observe that the rate of human-judged creative expressions in AI-written text is significantly lower than in human-written text.
Further, we find that both open source models tested, OLMo-1 and 2 of 7B and 32B size, exhibit a negative relationship between n-gram novelty and pragmaticality. As open-source LLMs try to generate text not present in data, their expressions tend to make less sense in context.

November 4, 2025 at 3:08 PM
Further, we find that both open source models tested, OLMo-1 and 2 of 7B and 32B size, exhibit a negative relationship between n-gram novelty and pragmaticality. As open-source LLMs try to generate text not present in data, their expressions tend to make less sense in context.
N-gram novelty is not a reliable metric of creativity: over *90%* of top-quartile n-gram novelty expressions were not judged as creative. We find many examples of low n-gram novelty expressions rated creative and high n-gram novelty expressions rated as non-pragmatic.

November 4, 2025 at 3:08 PM
N-gram novelty is not a reliable metric of creativity: over *90%* of top-quartile n-gram novelty expressions were not judged as creative. We find many examples of low n-gram novelty expressions rated creative and high n-gram novelty expressions rated as non-pragmatic.
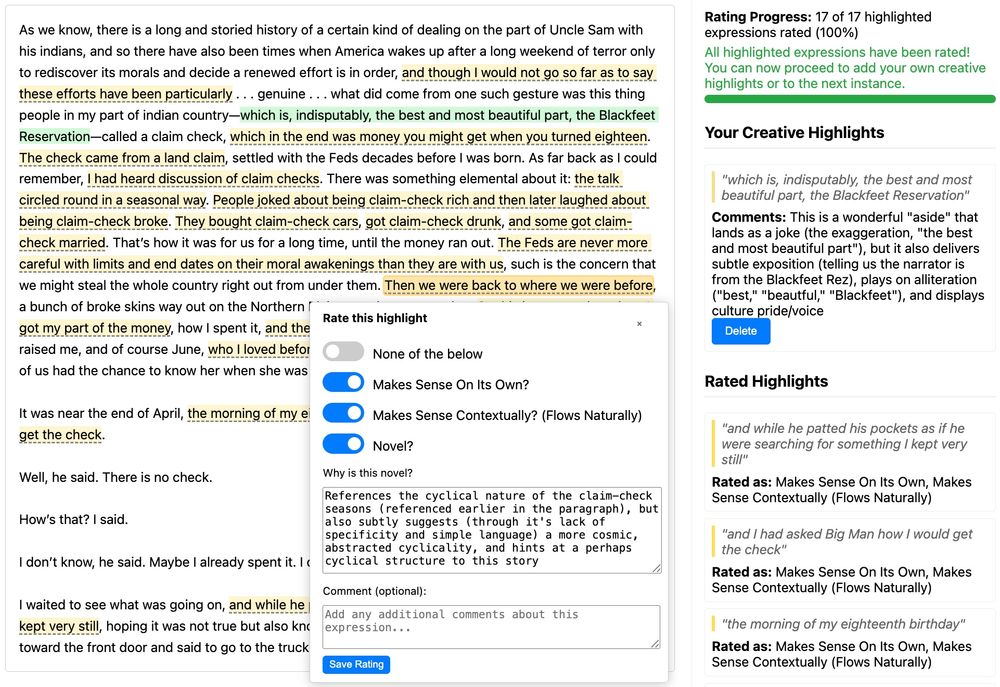
We recruit expert writers with MFA/MA/PhD background. They rated expressions in human- and AI-generated (from fully (code + DATA) open-source OLMo models) passages for if they make sense, are pragmatic, and are novel; they could also highlight any creative expressions.
November 4, 2025 at 3:08 PM
We recruit expert writers with MFA/MA/PhD background. They rated expressions in human- and AI-generated (from fully (code + DATA) open-source OLMo models) passages for if they make sense, are pragmatic, and are novel; they could also highlight any creative expressions.
The standard definition of creativity states the product has to be both novel AND appropriate. Similarly, we operationalize textual creativity as human-judged expression novelty AND sensicality (making sense by itself) + pragmaticality (making sense in context).


November 4, 2025 at 3:08 PM
The standard definition of creativity states the product has to be both novel AND appropriate. Similarly, we operationalize textual creativity as human-judged expression novelty AND sensicality (making sense by itself) + pragmaticality (making sense in context).
See more experiments and details in our paper: arxiv.org/abs/2405.01474
And come see our poster at NAACL :)
Joint work by Shreyas Kulkarni, @tuhinchakr.bsky.social, Smaranda Muresan
And come see our poster at NAACL :)
Joint work by Shreyas Kulkarni, @tuhinchakr.bsky.social, Smaranda Muresan

Understanding Figurative Meaning through Explainable Visual Entailment
Large Vision-Language Models (VLMs) have demonstrated strong capabilities in tasks requiring a fine-grained understanding of literal meaning in images and text, such as visual question-answering or vi...
arxiv.org
May 1, 2025 at 4:30 PM
See more experiments and details in our paper: arxiv.org/abs/2405.01474
And come see our poster at NAACL :)
Joint work by Shreyas Kulkarni, @tuhinchakr.bsky.social, Smaranda Muresan
And come see our poster at NAACL :)
Joint work by Shreyas Kulkarni, @tuhinchakr.bsky.social, Smaranda Muresan
Even powerful models achieve only 50% explanation adequacy rate, suggesting difficulties in reasoning about figurative inputs. Hallucination & unsound reasoning are the most prominent error categories.

May 1, 2025 at 4:30 PM
Even powerful models achieve only 50% explanation adequacy rate, suggesting difficulties in reasoning about figurative inputs. Hallucination & unsound reasoning are the most prominent error categories.
Our main results are:
1. VLMs struggle to generalize from literal to figurative meaning understanding (training on e-ViL only achieves random F1 on our task)
2. Figurative meaning in the image is harder to explain compared to when it is in the text
3. VLMs benefit from image data during fine-tuning
1. VLMs struggle to generalize from literal to figurative meaning understanding (training on e-ViL only achieves random F1 on our task)
2. Figurative meaning in the image is harder to explain compared to when it is in the text
3. VLMs benefit from image data during fine-tuning

May 1, 2025 at 4:30 PM
Our main results are:
1. VLMs struggle to generalize from literal to figurative meaning understanding (training on e-ViL only achieves random F1 on our task)
2. Figurative meaning in the image is harder to explain compared to when it is in the text
3. VLMs benefit from image data during fine-tuning
1. VLMs struggle to generalize from literal to figurative meaning understanding (training on e-ViL only achieves random F1 on our task)
2. Figurative meaning in the image is harder to explain compared to when it is in the text
3. VLMs benefit from image data during fine-tuning
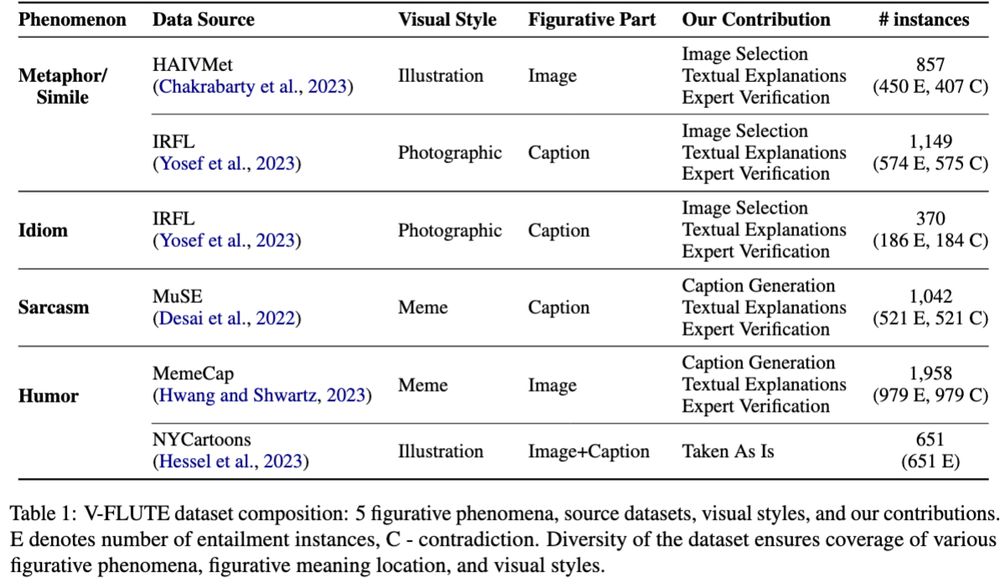
Via human-AI collaboration, we augment existing datasets for multimodal metaphors, sarcasm, and humor with entailed/contradicted captions and textual explanations. The figurative part can be in the image, caption, or both. We benchmarks a variety of models on the resulting data.
May 1, 2025 at 4:30 PM
Via human-AI collaboration, we augment existing datasets for multimodal metaphors, sarcasm, and humor with entailed/contradicted captions and textual explanations. The figurative part can be in the image, caption, or both. We benchmarks a variety of models on the resulting data.
We frame the multimodal figurative meaning understanding problem as an explainable visual entailment task between an image (premise) and its caption (hypothesis). The VLM predicts whether the image entails or contradicts the caption, and shows the reasoning steps in a textual explanation.

May 1, 2025 at 4:30 PM
We frame the multimodal figurative meaning understanding problem as an explainable visual entailment task between an image (premise) and its caption (hypothesis). The VLM predicts whether the image entails or contradicts the caption, and shows the reasoning steps in a textual explanation.