




Arkil Patel
@arkil.bsky.social
PhD Student at Mila and McGill | Research in ML and NLP | Past: AI2, MSFTResearch
arkilpatel.github.io
arkilpatel.github.io
Pinned
Arkil Patel
@arkil.bsky.social
· Apr 2

Thoughtology paper is out!! 🔥🐳
We study the reasoning chains of DeepSeek-R1 across a variety of tasks and find several surprising and interesting phenomena!
Incredible effort by the entire team!
🌐: mcgill-nlp.github.io/thoughtology/
We study the reasoning chains of DeepSeek-R1 across a variety of tasks and find several surprising and interesting phenomena!
Incredible effort by the entire team!
🌐: mcgill-nlp.github.io/thoughtology/
Reposted by Arkil Patel

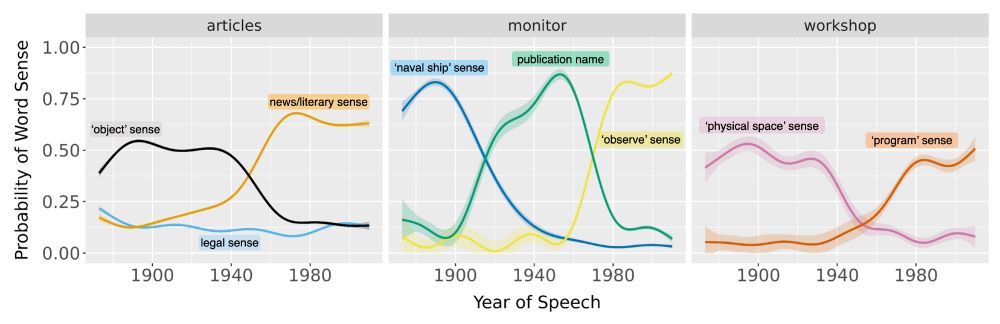
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
July 29, 2025 at 12:06 PM
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
Reposted by Arkil Patel

AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories
We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories.
We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories.

April 15, 2025 at 7:10 PM
AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories
We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories.
We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories.
Thoughtology paper is out!! 🔥🐳
We study the reasoning chains of DeepSeek-R1 across a variety of tasks and find several surprising and interesting phenomena!
Incredible effort by the entire team!
🌐: mcgill-nlp.github.io/thoughtology/
We study the reasoning chains of DeepSeek-R1 across a variety of tasks and find several surprising and interesting phenomena!
Incredible effort by the entire team!
🌐: mcgill-nlp.github.io/thoughtology/
April 2, 2025 at 7:10 AM
Thoughtology paper is out!! 🔥🐳
We study the reasoning chains of DeepSeek-R1 across a variety of tasks and find several surprising and interesting phenomena!
Incredible effort by the entire team!
🌐: mcgill-nlp.github.io/thoughtology/
We study the reasoning chains of DeepSeek-R1 across a variety of tasks and find several surprising and interesting phenomena!
Incredible effort by the entire team!
🌐: mcgill-nlp.github.io/thoughtology/
Reposted by Arkil Patel

Instruction-following retrievers can efficiently and accurately search for harmful and sensitive information on the internet! 🌐💣
Retrievers need to be aligned too! 🚨🚨🚨
Work done with the wonderful Nick and @sivareddyg.bsky.social
🔗 mcgill-nlp.github.io/malicious-ir/
Thread: 🧵👇
Retrievers need to be aligned too! 🚨🚨🚨
Work done with the wonderful Nick and @sivareddyg.bsky.social
🔗 mcgill-nlp.github.io/malicious-ir/
Thread: 🧵👇
Exploiting Instruction-Following Retrievers for Malicious Information Retrieval
Parishad BehnamGhader, Nicholas Meade, Siva Reddy
mcgill-nlp.github.io
March 12, 2025 at 4:15 PM
Instruction-following retrievers can efficiently and accurately search for harmful and sensitive information on the internet! 🌐💣
Retrievers need to be aligned too! 🚨🚨🚨
Work done with the wonderful Nick and @sivareddyg.bsky.social
🔗 mcgill-nlp.github.io/malicious-ir/
Thread: 🧵👇
Retrievers need to be aligned too! 🚨🚨🚨
Work done with the wonderful Nick and @sivareddyg.bsky.social
🔗 mcgill-nlp.github.io/malicious-ir/
Thread: 🧵👇
Llamas browsing the web look cute, but they are capable of causing a lot of harm!
Check out our new Web Agents ∩ Safety benchmark: SafeArena!
Paper: arxiv.org/abs/2503.04957
Check out our new Web Agents ∩ Safety benchmark: SafeArena!
Paper: arxiv.org/abs/2503.04957

March 10, 2025 at 5:51 PM
Llamas browsing the web look cute, but they are capable of causing a lot of harm!
Check out our new Web Agents ∩ Safety benchmark: SafeArena!
Paper: arxiv.org/abs/2503.04957
Check out our new Web Agents ∩ Safety benchmark: SafeArena!
Paper: arxiv.org/abs/2503.04957
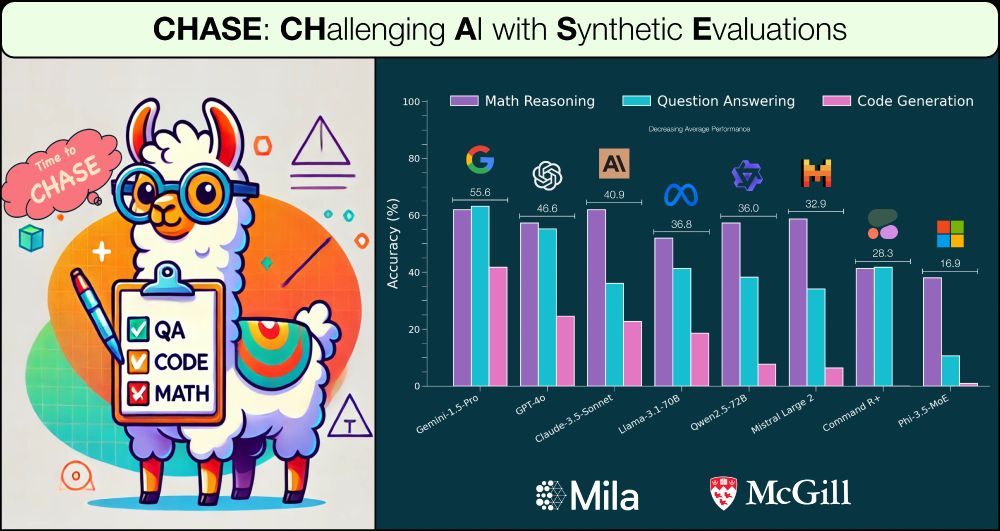
Presenting ✨ 𝐂𝐇𝐀𝐒𝐄: 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐧𝐠 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐢𝐧𝐠 𝐬𝐲𝐧𝐭𝐡𝐞𝐭𝐢𝐜 𝐝𝐚𝐭𝐚 𝐟𝐨𝐫 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 ✨
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵:
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵:
February 21, 2025 at 4:29 PM
Presenting ✨ 𝐂𝐇𝐀𝐒𝐄: 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐧𝐠 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐢𝐧𝐠 𝐬𝐲𝐧𝐭𝐡𝐞𝐭𝐢𝐜 𝐝𝐚𝐭𝐚 𝐟𝐨𝐫 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 ✨
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵:
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵: