




Ari Benjamin
@aribenjamin.bsky.social
The logic of 'rising stars' programs is that science needs to retain top talent. But if anything, I've seen more brilliant minds leave science due to the culture of individualist careerism that these awards contribute to, and are a symptom of.
November 12, 2025 at 7:22 PM
The logic of 'rising stars' programs is that science needs to retain top talent. But if anything, I've seen more brilliant minds leave science due to the culture of individualist careerism that these awards contribute to, and are a symptom of.
For example, if you spatially cluster the brain based on transcriptomics (e.g. www.biorxiv.org/content/10.1...) the clusters barely match functional areas.
IMO, data converges: we need to revisit the atlas.
But I agree broadly: brain tissue is far from homogenous, and we neglect it at our peril.
IMO, data converges: we need to revisit the atlas.
But I agree broadly: brain tissue is far from homogenous, and we neglect it at our peril.
November 6, 2025 at 2:24 PM
For example, if you spatially cluster the brain based on transcriptomics (e.g. www.biorxiv.org/content/10.1...) the clusters barely match functional areas.
IMO, data converges: we need to revisit the atlas.
But I agree broadly: brain tissue is far from homogenous, and we neglect it at our peril.
IMO, data converges: we need to revisit the atlas.
But I agree broadly: brain tissue is far from homogenous, and we neglect it at our peril.
We've reanalyzed this dataset to predict functional brain areas from transcriptomic data, with some success (www.biorxiv.org/content/10.1...).
Yet if there is controversy around how areas are defined from neural recordings, cell diversity is equally as confusing a signal.... (1/2)
Yet if there is controversy around how areas are defined from neural recordings, cell diversity is equally as confusing a signal.... (1/2)

TissueFormer: a neural network for labeling tissue from grouped single-cell RNA profiles
Single-cell RNA sequencing technologies have enabled unprecedented insights into gene expression and are poised to transform clinical diagnostics. At present, most computational approaches for interpr...
www.biorxiv.org
November 6, 2025 at 2:24 PM
We've reanalyzed this dataset to predict functional brain areas from transcriptomic data, with some success (www.biorxiv.org/content/10.1...).
Yet if there is controversy around how areas are defined from neural recordings, cell diversity is equally as confusing a signal.... (1/2)
Yet if there is controversy around how areas are defined from neural recordings, cell diversity is equally as confusing a signal.... (1/2)
My confidence in that last sentence was less than 100%. But what was it? And if I had said "absolutely positive" somewhere, what then?
If you can't quantify natural language uncertainty, you can't train for it. At least explicitly. Thus all we have are RLHF approaches
If you can't quantify natural language uncertainty, you can't train for it. At least explicitly. Thus all we have are RLHF approaches
October 14, 2025 at 9:00 PM
My confidence in that last sentence was less than 100%. But what was it? And if I had said "absolutely positive" somewhere, what then?
If you can't quantify natural language uncertainty, you can't train for it. At least explicitly. Thus all we have are RLHF approaches
If you can't quantify natural language uncertainty, you can't train for it. At least explicitly. Thus all we have are RLHF approaches
True, but I think that's something different. Among the uncertainties flying around in Bayes stats – epistemic uncertainty over model weights, aleatoric uncertainty reflected in output probabilities, etc – none of them capture hedging in natural language. (1/2)
October 14, 2025 at 9:00 PM
True, but I think that's something different. Among the uncertainties flying around in Bayes stats – epistemic uncertainty over model weights, aleatoric uncertainty reflected in output probabilities, etc – none of them capture hedging in natural language. (1/2)
One hurdle: how do you reliably quantify the uncertainty expressed in a natural language paragraph?
If you gave me this measure for all data in the wild, and it was differentiable wrt the model, one might take a likelihood-max approach (plus calibration etc)
If you gave me this measure for all data in the wild, and it was differentiable wrt the model, one might take a likelihood-max approach (plus calibration etc)
October 14, 2025 at 8:18 PM
One hurdle: how do you reliably quantify the uncertainty expressed in a natural language paragraph?
If you gave me this measure for all data in the wild, and it was differentiable wrt the model, one might take a likelihood-max approach (plus calibration etc)
If you gave me this measure for all data in the wild, and it was differentiable wrt the model, one might take a likelihood-max approach (plus calibration etc)
Truly. ‘The use of state power for personal vendettas and returning personal favors’ is what we see daily. It’s plain corruption and I don’t know why that’s not the front message
October 10, 2025 at 3:55 AM
Truly. ‘The use of state power for personal vendettas and returning personal favors’ is what we see daily. It’s plain corruption and I don’t know why that’s not the front message
Under the hood, this
1) gets the avg (pseudobulk) gene expression of each type,
2) computes the similarity matrix,
3) projects expression into a 3D space using MDS, and
4) interprets the space as a perceptually uniform color space (LUV)
1) gets the avg (pseudobulk) gene expression of each type,
2) computes the similarity matrix,
3) projects expression into a 3D space using MDS, and
4) interprets the space as a perceptually uniform color space (LUV)
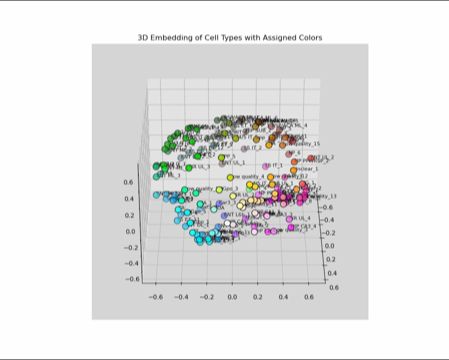
September 18, 2025 at 4:03 PM
Under the hood, this
1) gets the avg (pseudobulk) gene expression of each type,
2) computes the similarity matrix,
3) projects expression into a 3D space using MDS, and
4) interprets the space as a perceptually uniform color space (LUV)
1) gets the avg (pseudobulk) gene expression of each type,
2) computes the similarity matrix,
3) projects expression into a 3D space using MDS, and
4) interprets the space as a perceptually uniform color space (LUV)
To make these colormaps, I made an easy python package:
```
!pip install colormycells
# Create a colormap based on cell type similarities
colors = get_colormap(adata, key="cell_type")
# Plot your cells
sc.pl.umap(adata, color="cell_type", palette=colors)
````
github.com/ZadorLaborat...
```
!pip install colormycells
# Create a colormap based on cell type similarities
colors = get_colormap(adata, key="cell_type")
# Plot your cells
sc.pl.umap(adata, color="cell_type", palette=colors)
````
github.com/ZadorLaborat...
github.com
September 18, 2025 at 4:03 PM
To make these colormaps, I made an easy python package:
```
!pip install colormycells
# Create a colormap based on cell type similarities
colors = get_colormap(adata, key="cell_type")
# Plot your cells
sc.pl.umap(adata, color="cell_type", palette=colors)
````
github.com/ZadorLaborat...
```
!pip install colormycells
# Create a colormap based on cell type similarities
colors = get_colormap(adata, key="cell_type")
# Plot your cells
sc.pl.umap(adata, color="cell_type", palette=colors)
````
github.com/ZadorLaborat...
When colors reflect the actual differences between cell types, you can see things you wouldn't otherwise. For the mouse cortex, see how the layers form a rainbow, indicating a gradient of gene expression.
I also think this makes pretty plots 🌈 so that's nice.
I also think this makes pretty plots 🌈 so that's nice.
September 18, 2025 at 4:03 PM
When colors reflect the actual differences between cell types, you can see things you wouldn't otherwise. For the mouse cortex, see how the layers form a rainbow, indicating a gradient of gene expression.
I also think this makes pretty plots 🌈 so that's nice.
I also think this makes pretty plots 🌈 so that's nice.
Good scientific plotting uses color to convey meaning. We don't want to distract readers. Yet with default categorical maps,
(-) some cell types jump out for no reason
(-) perceptual similarity between colors is meaningless
(-) fewer colors than types, leading to repeats
(-) some cell types jump out for no reason
(-) perceptual similarity between colors is meaningless
(-) fewer colors than types, leading to repeats

September 18, 2025 at 4:03 PM
Good scientific plotting uses color to convey meaning. We don't want to distract readers. Yet with default categorical maps,
(-) some cell types jump out for no reason
(-) perceptual similarity between colors is meaningless
(-) fewer colors than types, leading to repeats
(-) some cell types jump out for no reason
(-) perceptual similarity between colors is meaningless
(-) fewer colors than types, leading to repeats
I think this is the right view. But it’s worth adding that a large section of neuroscience defines specialization by what areas ‘encode for’, defined predictively.
Rather than the bell tolling for local specialization, it might be tolling for that ‘functional’ stim-response paradigm
Rather than the bell tolling for local specialization, it might be tolling for that ‘functional’ stim-response paradigm
September 4, 2025 at 6:02 PM
I think this is the right view. But it’s worth adding that a large section of neuroscience defines specialization by what areas ‘encode for’, defined predictively.
Rather than the bell tolling for local specialization, it might be tolling for that ‘functional’ stim-response paradigm
Rather than the bell tolling for local specialization, it might be tolling for that ‘functional’ stim-response paradigm
