




Arianna Bisazza
@arianna-bis.bsky.social
Associate Professor at GroNLP ( @gronlp.bsky.social ) #NLP | Multilingualism | Interpretability | Language Learning in Humans vs NeuralNets | Mum^2
Head of the InClow research group: https://inclow-lm.github.io/
Head of the InClow research group: https://inclow-lm.github.io/
Reposted by Arianna Bisazza

👀 Look what 🎅 has broght just before Christmas 🎁: a brand new Research Master in Natural Language Processing at @facultyofartsug.bsky.social @rug.nl
Program: www.rug.nl/masters/natu...
Applications (2026/2027) are open! Come and study with us (you will also learn why we have a 🐮 in our logo)
Program: www.rug.nl/masters/natu...
Applications (2026/2027) are open! Come and study with us (you will also learn why we have a 🐮 in our logo)

Natural Language Processing
How do you build Large Language Models? How do humans experience Natural Language Processing (NLP) applications in their daily lives? And how can we...
www.rug.nl
December 18, 2025 at 11:28 AM
👀 Look what 🎅 has broght just before Christmas 🎁: a brand new Research Master in Natural Language Processing at @facultyofartsug.bsky.social @rug.nl
Program: www.rug.nl/masters/natu...
Applications (2026/2027) are open! Come and study with us (you will also learn why we have a 🐮 in our logo)
Program: www.rug.nl/masters/natu...
Applications (2026/2027) are open! Come and study with us (you will also learn why we have a 🐮 in our logo)
Reposted by Arianna Bisazza

Wrapping up my oral presentations today with our TACL paper "QE4PE: Quality Estimation for Human Post-editing" at the Interpretability morning session #EMNLP2025 (Room A104, 11:45 China time)!
Paper: arxiv.org/abs/2503.03044
Slides/video/poster: underline.io/lecture/1315...
Paper: arxiv.org/abs/2503.03044
Slides/video/poster: underline.io/lecture/1315...

November 7, 2025 at 2:50 AM
Wrapping up my oral presentations today with our TACL paper "QE4PE: Quality Estimation for Human Post-editing" at the Interpretability morning session #EMNLP2025 (Room A104, 11:45 China time)!
Paper: arxiv.org/abs/2503.03044
Slides/video/poster: underline.io/lecture/1315...
Paper: arxiv.org/abs/2503.03044
Slides/video/poster: underline.io/lecture/1315...
Interested in agent simulations of language change & pragmatic naming behavior?
Come check our poster TODAY (Fri, Nov 7, 12:30 - 13:30) #EMNLP!
Come check our poster TODAY (Fri, Nov 7, 12:30 - 13:30) #EMNLP!
There’s more to Neural Nets than big fat LLMs!
We’ve built a NN-agent framework to simulate how people choose the best word in a given communication context (i.e. pragmatic naming behavior).
With @yuqing0304.bsky.social, @ecesuurker.bsky.social, Tessa Verhoef, @gboleda.bsky.social
We’ve built a NN-agent framework to simulate how people choose the best word in a given communication context (i.e. pragmatic naming behavior).
With @yuqing0304.bsky.social, @ecesuurker.bsky.social, Tessa Verhoef, @gboleda.bsky.social
November 7, 2025 at 12:56 AM
Interested in agent simulations of language change & pragmatic naming behavior?
Come check our poster TODAY (Fri, Nov 7, 12:30 - 13:30) #EMNLP!
Come check our poster TODAY (Fri, Nov 7, 12:30 - 13:30) #EMNLP!
Benchmarks of linguistic minimal pairs are key for LM evaluation & help us overcome the English-centric bias in NLP research
Come to our poster TODAY (Fr 7 Nov 10.30-12.00) #EMNLP to meet TurBLiMP, a new benchmark for Turkish, revealing how LLMs deal with free-order, morphologically rich languages
Come to our poster TODAY (Fr 7 Nov 10.30-12.00) #EMNLP to meet TurBLiMP, a new benchmark for Turkish, revealing how LLMs deal with free-order, morphologically rich languages
Proud to introduce TurBLiMP, the 1st benchmark of minimal pairs for free-order, morphologically rich Turkish language!
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social

TurBLiMP: A Turkish Benchmark of Linguistic Minimal Pairs
We introduce TurBLiMP, the first Turkish benchmark of linguistic minimal pairs, designed to evaluate the linguistic abilities of monolingual and multilingual language models (LMs). Covering 16 linguis...
arxiv.org
November 6, 2025 at 9:24 PM
Benchmarks of linguistic minimal pairs are key for LM evaluation & help us overcome the English-centric bias in NLP research
Come to our poster TODAY (Fr 7 Nov 10.30-12.00) #EMNLP to meet TurBLiMP, a new benchmark for Turkish, revealing how LLMs deal with free-order, morphologically rich languages
Come to our poster TODAY (Fr 7 Nov 10.30-12.00) #EMNLP to meet TurBLiMP, a new benchmark for Turkish, revealing how LLMs deal with free-order, morphologically rich languages
Reposted by Arianna Bisazza

I'm in Suzhou to present our work on MultiBLiMP, Friday @ 11:45 in the Multilinguality session (A301)!
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768

November 6, 2025 at 7:08 AM
I'm in Suzhou to present our work on MultiBLiMP, Friday @ 11:45 in the Multilinguality session (A301)!
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768
Interested in developmentally plausible LMs, and the role of child-directed language data?
Come to our poster TODAY (Fr 7 Nov, 10.30-12.00) #EMNLP!
Come to our poster TODAY (Fr 7 Nov, 10.30-12.00) #EMNLP!
“Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models”
I’m happy to share that the preprint of my first PhD project is now online!
🎊 Paper: arxiv.org/abs/2505.23689
I’m happy to share that the preprint of my first PhD project is now online!
🎊 Paper: arxiv.org/abs/2505.23689

Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models
Seminal work by Huebner et al. (2021) showed that language models (LMs) trained on English Child-Directed Language (CDL) can reach similar syntactic abilities as LMs trained on much larger amounts of ...
arxiv.org
November 6, 2025 at 9:13 PM
Interested in developmentally plausible LMs, and the role of child-directed language data?
Come to our poster TODAY (Fr 7 Nov, 10.30-12.00) #EMNLP!
Come to our poster TODAY (Fr 7 Nov, 10.30-12.00) #EMNLP!
There’s more to Neural Nets than big fat LLMs!
We’ve built a NN-agent framework to simulate how people choose the best word in a given communication context (i.e. pragmatic naming behavior).
With @yuqing0304.bsky.social, @ecesuurker.bsky.social, Tessa Verhoef, @gboleda.bsky.social
We’ve built a NN-agent framework to simulate how people choose the best word in a given communication context (i.e. pragmatic naming behavior).
With @yuqing0304.bsky.social, @ecesuurker.bsky.social, Tessa Verhoef, @gboleda.bsky.social

November 6, 2025 at 9:07 PM
There’s more to Neural Nets than big fat LLMs!
We’ve built a NN-agent framework to simulate how people choose the best word in a given communication context (i.e. pragmatic naming behavior).
With @yuqing0304.bsky.social, @ecesuurker.bsky.social, Tessa Verhoef, @gboleda.bsky.social
We’ve built a NN-agent framework to simulate how people choose the best word in a given communication context (i.e. pragmatic naming behavior).
With @yuqing0304.bsky.social, @ecesuurker.bsky.social, Tessa Verhoef, @gboleda.bsky.social
Thrilled to be heading to Suzhou with a big team of GroNLP'ers 🐮
Interested in Interpretable, Cognitively inspired, Low-resource LMs? Don't miss our posters & talks #EMNLP2025!
Interested in Interpretable, Cognitively inspired, Low-resource LMs? Don't miss our posters & talks #EMNLP2025!
With only a week left for #EMNLP2025, we are happy to announce all the works we 🐮 will present 🥳 - come and say "hi" to our posters and presentations during the Main and the co-located events (*SEM and workshops) See you in Suzhou ✈️


October 31, 2025 at 10:50 PM
Thrilled to be heading to Suzhou with a big team of GroNLP'ers 🐮
Interested in Interpretable, Cognitively inspired, Low-resource LMs? Don't miss our posters & talks #EMNLP2025!
Interested in Interpretable, Cognitively inspired, Low-resource LMs? Don't miss our posters & talks #EMNLP2025!
Reposted by Arianna Bisazza

[1/]💡New Paper
Large reasoning models (LRMs) are strong in English — but how well do they reason in your language?
Our latest work uncovers their limitation and a clear trade-off:
Controlling Thinking Trace Language Comes at the Cost of Accuracy
📄Link: arxiv.org/abs/2505.22888
Large reasoning models (LRMs) are strong in English — but how well do they reason in your language?
Our latest work uncovers their limitation and a clear trade-off:
Controlling Thinking Trace Language Comes at the Cost of Accuracy
📄Link: arxiv.org/abs/2505.22888

May 30, 2025 at 1:09 PM
[1/]💡New Paper
Large reasoning models (LRMs) are strong in English — but how well do they reason in your language?
Our latest work uncovers their limitation and a clear trade-off:
Controlling Thinking Trace Language Comes at the Cost of Accuracy
📄Link: arxiv.org/abs/2505.22888
Large reasoning models (LRMs) are strong in English — but how well do they reason in your language?
Our latest work uncovers their limitation and a clear trade-off:
Controlling Thinking Trace Language Comes at the Cost of Accuracy
📄Link: arxiv.org/abs/2505.22888
Reposted by Arianna Bisazza

𝐃𝐨 𝐲𝐨𝐮 𝐫𝐞𝐚𝐥𝐥𝐲 𝐰𝐚𝐧𝐭 𝐭𝐨 𝐬𝐞𝐞 𝐰𝐡𝐚𝐭 𝐦𝐮𝐥𝐭𝐢𝐥𝐢𝐧𝐠𝐮𝐚𝐥 𝐞𝐟𝐟𝐨𝐫𝐭 𝐥𝐨𝐨𝐤𝐬 𝐥𝐢𝐤𝐞? 🇨🇳🇮🇩🇸🇪
Here’s the proof! 𝐁𝐚𝐛𝐲𝐁𝐚𝐛𝐞𝐥𝐋𝐌 is the first Multilingual Benchmark of Developmentally Plausible Training Data available for 45 languages to the NLP community 🎉
arxiv.org/abs/2510.10159
Here’s the proof! 𝐁𝐚𝐛𝐲𝐁𝐚𝐛𝐞𝐥𝐋𝐌 is the first Multilingual Benchmark of Developmentally Plausible Training Data available for 45 languages to the NLP community 🎉
arxiv.org/abs/2510.10159

October 14, 2025 at 5:01 PM
𝐃𝐨 𝐲𝐨𝐮 𝐫𝐞𝐚𝐥𝐥𝐲 𝐰𝐚𝐧𝐭 𝐭𝐨 𝐬𝐞𝐞 𝐰𝐡𝐚𝐭 𝐦𝐮𝐥𝐭𝐢𝐥𝐢𝐧𝐠𝐮𝐚𝐥 𝐞𝐟𝐟𝐨𝐫𝐭 𝐥𝐨𝐨𝐤𝐬 𝐥𝐢𝐤𝐞? 🇨🇳🇮🇩🇸🇪
Here’s the proof! 𝐁𝐚𝐛𝐲𝐁𝐚𝐛𝐞𝐥𝐋𝐌 is the first Multilingual Benchmark of Developmentally Plausible Training Data available for 45 languages to the NLP community 🎉
arxiv.org/abs/2510.10159
Here’s the proof! 𝐁𝐚𝐛𝐲𝐁𝐚𝐛𝐞𝐥𝐋𝐌 is the first Multilingual Benchmark of Developmentally Plausible Training Data available for 45 languages to the NLP community 🎉
arxiv.org/abs/2510.10159
Reposted by Arianna Bisazza

📢 Announcing the First Workshop on Multilingual and Multicultural Evaluation (MME) at #EACL2026 🇲🇦
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025

October 20, 2025 at 10:37 AM
📢 Announcing the First Workshop on Multilingual and Multicultural Evaluation (MME) at #EACL2026 🇲🇦
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
Reposted by Arianna Bisazza

Delighted to share that our paper "Reading Between the Prompts: How Stereotypes Shape LLM's Implicit Personalization" (joint work with @arianna-bis.bsky.social and Raquel Fernández) got accepted to the main conference of #EMNLP
Can't wait to discuss our work at #EMNLP2025 in Suzhou this November!
Can't wait to discuss our work at #EMNLP2025 in Suzhou this November!
Do LLMs assume demographic information based on stereotypes?
We (@arianna-bis.bsky.social, Raquel Fernández and I) answered this question in our new paper: "Reading Between the Prompts: How Stereotypes Shape LLM's Implicit Personalization".
🧵
arxiv.org/abs/2505.16467
We (@arianna-bis.bsky.social, Raquel Fernández and I) answered this question in our new paper: "Reading Between the Prompts: How Stereotypes Shape LLM's Implicit Personalization".
🧵
arxiv.org/abs/2505.16467

August 21, 2025 at 8:59 AM
Delighted to share that our paper "Reading Between the Prompts: How Stereotypes Shape LLM's Implicit Personalization" (joint work with @arianna-bis.bsky.social and Raquel Fernández) got accepted to the main conference of #EMNLP
Can't wait to discuss our work at #EMNLP2025 in Suzhou this November!
Can't wait to discuss our work at #EMNLP2025 in Suzhou this November!
Proud to introduce TurBLiMP, the 1st benchmark of minimal pairs for free-order, morphologically rich Turkish language!
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social
TurBLiMP: A Turkish Benchmark of Linguistic Minimal Pairs
We introduce TurBLiMP, the first Turkish benchmark of linguistic minimal pairs, designed to evaluate the linguistic abilities of monolingual and multilingual language models (LMs). Covering 16 linguis...
arxiv.org
June 19, 2025 at 4:28 PM
Proud to introduce TurBLiMP, the 1st benchmark of minimal pairs for free-order, morphologically rich Turkish language!
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social
One step further in our quest to bring interpretability techniques to the service of MT end users: Are uncertainty & model-internals based metrics a viable alternative to supervised word-level quality estimation?
New paper w/ @gsarti.com
@zouharvi.bsky.social @malvinanissim.bsky.social
New paper w/ @gsarti.com
@zouharvi.bsky.social @malvinanissim.bsky.social
📢 New paper: Can unsupervised metrics extracted from MT models detect their translation errors reliably? Do annotators even *agree* on what constitutes an error? 🧐
We compare uncertainty- and interp-based WQE metrics across 12 directions, with some surprising findings!
🧵 1/
We compare uncertainty- and interp-based WQE metrics across 12 directions, with some surprising findings!
🧵 1/

May 31, 2025 at 6:58 PM
One step further in our quest to bring interpretability techniques to the service of MT end users: Are uncertainty & model-internals based metrics a viable alternative to supervised word-level quality estimation?
New paper w/ @gsarti.com
@zouharvi.bsky.social @malvinanissim.bsky.social
New paper w/ @gsarti.com
@zouharvi.bsky.social @malvinanissim.bsky.social
Large Reasoning Models are raising the bar for answer accuracy & transparency, but how does that work in multilingual settings? Can LRMs reason in your language, and what does that entail?
New preprint led by @jiruiqi.bsky.social and @shan23chen.bsky.social!
New preprint led by @jiruiqi.bsky.social and @shan23chen.bsky.social!
[1/]💡New Paper
Large reasoning models (LRMs) are strong in English — but how well do they reason in your language?
Our latest work uncovers their limitation and a clear trade-off:
Controlling Thinking Trace Language Comes at the Cost of Accuracy
📄Link: arxiv.org/abs/2505.22888
Large reasoning models (LRMs) are strong in English — but how well do they reason in your language?
Our latest work uncovers their limitation and a clear trade-off:
Controlling Thinking Trace Language Comes at the Cost of Accuracy
📄Link: arxiv.org/abs/2505.22888
May 31, 2025 at 2:01 PM
Large Reasoning Models are raising the bar for answer accuracy & transparency, but how does that work in multilingual settings? Can LRMs reason in your language, and what does that entail?
New preprint led by @jiruiqi.bsky.social and @shan23chen.bsky.social!
New preprint led by @jiruiqi.bsky.social and @shan23chen.bsky.social!
Following the success story of BabyBERTa, I & many other NLPers have turned to language acquisition for inspiration. In this new paper we show that using Child-Directed Language as training data is unfortunately *not* beneficial for syntax learning, at least not in the traditional LM training regime
“Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models”
I’m happy to share that the preprint of my first PhD project is now online!
🎊 Paper: arxiv.org/abs/2505.23689
I’m happy to share that the preprint of my first PhD project is now online!
🎊 Paper: arxiv.org/abs/2505.23689
Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models
Seminal work by Huebner et al. (2021) showed that language models (LMs) trained on English Child-Directed Language (CDL) can reach similar syntactic abilities as LMs trained on much larger amounts of ...
arxiv.org
May 30, 2025 at 8:45 PM
Following the success story of BabyBERTa, I & many other NLPers have turned to language acquisition for inspiration. In this new paper we show that using Child-Directed Language as training data is unfortunately *not* beneficial for syntax learning, at least not in the traditional LM training regime
Thinking LLM treats you just like an average user? Think again!
@veraneplenbroek.bsky.social‘s analysis shows LLMs behave differently according to your gender, race & more. Implicit personalization is always at work & is strongly based on your conversation topics.
Great collab w/ Raquel Fernández ⤵️
@veraneplenbroek.bsky.social‘s analysis shows LLMs behave differently according to your gender, race & more. Implicit personalization is always at work & is strongly based on your conversation topics.
Great collab w/ Raquel Fernández ⤵️
Do LLMs assume demographic information based on stereotypes?
We (@arianna-bis.bsky.social, Raquel Fernández and I) answered this question in our new paper: "Reading Between the Prompts: How Stereotypes Shape LLM's Implicit Personalization".
🧵
arxiv.org/abs/2505.16467
We (@arianna-bis.bsky.social, Raquel Fernández and I) answered this question in our new paper: "Reading Between the Prompts: How Stereotypes Shape LLM's Implicit Personalization".
🧵
arxiv.org/abs/2505.16467
May 28, 2025 at 8:37 PM
Thinking LLM treats you just like an average user? Think again!
@veraneplenbroek.bsky.social‘s analysis shows LLMs behave differently according to your gender, race & more. Implicit personalization is always at work & is strongly based on your conversation topics.
Great collab w/ Raquel Fernández ⤵️
@veraneplenbroek.bsky.social‘s analysis shows LLMs behave differently according to your gender, race & more. Implicit personalization is always at work & is strongly based on your conversation topics.
Great collab w/ Raquel Fernández ⤵️
Happy to be part of this collaboration on personalizing translation style in the literary domain. Besides classical multi-shot prompting, various steering techniques show promising results & bring new insights! See thread ⤵️
W/ @danielsc4.it @gsarti.com ElisabettaFersini, @malvinanissim.bsky.social
W/ @danielsc4.it @gsarti.com ElisabettaFersini, @malvinanissim.bsky.social
May 27, 2025 at 8:41 PM
Happy to be part of this collaboration on personalizing translation style in the literary domain. Besides classical multi-shot prompting, various steering techniques show promising results & bring new insights! See thread ⤵️
W/ @danielsc4.it @gsarti.com ElisabettaFersini, @malvinanissim.bsky.social
W/ @danielsc4.it @gsarti.com ElisabettaFersini, @malvinanissim.bsky.social
Reposted by Arianna Bisazza
Excited to share that "Cross-Lingual Transfer of Debiasing and Detoxification in Multilingual LLMs: An Extensive Investigation" arxiv.org/abs/2412.14050 got accepted to ACL Findings! 🎉 #ACL2025 Big thanks to my supervisors Raquel Fernández and @arianna-bis.bsky.social for their guidance and support!

May 21, 2025 at 2:35 PM
Excited to share that "Cross-Lingual Transfer of Debiasing and Detoxification in Multilingual LLMs: An Extensive Investigation" arxiv.org/abs/2412.14050 got accepted to ACL Findings! 🎉 #ACL2025 Big thanks to my supervisors Raquel Fernández and @arianna-bis.bsky.social for their guidance and support!
RAG is a powerful way to improve LLMs' answering abilities across many languages. But how do LLMs deal with multilingual contexts? Do they answer consistently when the retrieved info is provided to them in different languages?
Joint work w/ @jiruiqi.bsky.social & Raquel_Fernández
See thread! ⤵️
Joint work w/ @jiruiqi.bsky.social & Raquel_Fernández
See thread! ⤵️
✨ New Paper ✨
[1/] Retrieving passages from many languages can boost retrieval augmented generation (RAG) performance, but how good are LLMs at dealing with multilingual contexts in the prompt?
📄 Check it out: arxiv.org/abs/2504.00597
(w/ @arianna-bis.bsky.social @Raquel_Fernández)
#NLProc
[1/] Retrieving passages from many languages can boost retrieval augmented generation (RAG) performance, but how good are LLMs at dealing with multilingual contexts in the prompt?
📄 Check it out: arxiv.org/abs/2504.00597
(w/ @arianna-bis.bsky.social @Raquel_Fernández)
#NLProc

April 18, 2025 at 10:01 AM
RAG is a powerful way to improve LLMs' answering abilities across many languages. But how do LLMs deal with multilingual contexts? Do they answer consistently when the retrieved info is provided to them in different languages?
Joint work w/ @jiruiqi.bsky.social & Raquel_Fernández
See thread! ⤵️
Joint work w/ @jiruiqi.bsky.social & Raquel_Fernández
See thread! ⤵️
Modern LLMs "speak" hundreds of languages... but do they really?
Multilinguality claims are often based on downstream tasks like QA & MT, while *formal* linguistic competence remains hard to gauge in lots of languages
Meet MultiBLiMP!
(joint work w/ @jumelet.bsky.social & @weissweiler.bsky.social)
Multilinguality claims are often based on downstream tasks like QA & MT, while *formal* linguistic competence remains hard to gauge in lots of languages
Meet MultiBLiMP!
(joint work w/ @jumelet.bsky.social & @weissweiler.bsky.social)
✨New paper ✨
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
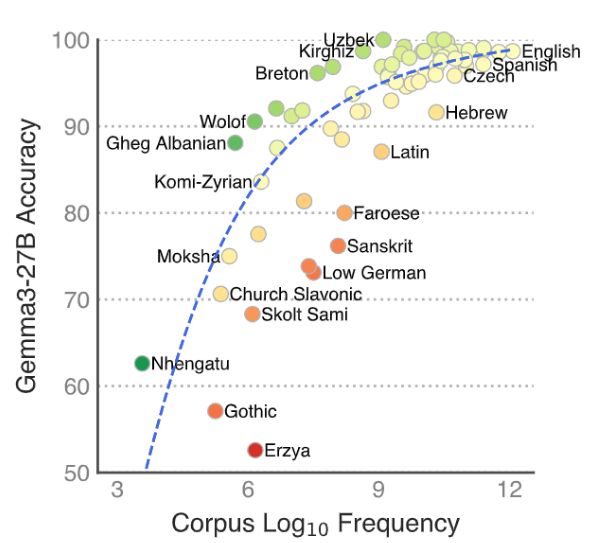
April 8, 2025 at 12:27 PM
Modern LLMs "speak" hundreds of languages... but do they really?
Multilinguality claims are often based on downstream tasks like QA & MT, while *formal* linguistic competence remains hard to gauge in lots of languages
Meet MultiBLiMP!
(joint work w/ @jumelet.bsky.social & @weissweiler.bsky.social)
Multilinguality claims are often based on downstream tasks like QA & MT, while *formal* linguistic competence remains hard to gauge in lots of languages
Meet MultiBLiMP!
(joint work w/ @jumelet.bsky.social & @weissweiler.bsky.social)
Thanks to @haspelmath.bsky.social I just discovered this great collection of hypotheses extracted from evolutionary linguistics and typology papers, represented as a graph where linguistic properties are linked to others via different relations.
correlation-machine.com/CHIELD/varia...
correlation-machine.com/CHIELD/varia...

April 4, 2025 at 3:54 PM
Thanks to @haspelmath.bsky.social I just discovered this great collection of hypotheses extracted from evolutionary linguistics and typology papers, represented as a graph where linguistic properties are linked to others via different relations.
correlation-machine.com/CHIELD/varia...
correlation-machine.com/CHIELD/varia...
April 4, 2025 at 7:28 AM
Reposted by Arianna Bisazza
🚨 The CoNLL deadline is just 2 days away! 🚨
Submit your work by March 14th, 11:59 PM (AoE, UTC-12)
Don't miss out! ⏳
🔗 Submission links: conll.org
#CoNLL2025 #NLP #CoNLL
Submit your work by March 14th, 11:59 PM (AoE, UTC-12)
Don't miss out! ⏳
🔗 Submission links: conll.org
#CoNLL2025 #NLP #CoNLL
CoNLL 2025 | CoNLL
conll.org
March 12, 2025 at 3:33 PM
🚨 The CoNLL deadline is just 2 days away! 🚨
Submit your work by March 14th, 11:59 PM (AoE, UTC-12)
Don't miss out! ⏳
🔗 Submission links: conll.org
#CoNLL2025 #NLP #CoNLL
Submit your work by March 14th, 11:59 PM (AoE, UTC-12)
Don't miss out! ⏳
🔗 Submission links: conll.org
#CoNLL2025 #NLP #CoNLL
📣 Soon-to-open PhD position @gronlp.bsky.social:
Come work with Annemarie van Dooren, @yevgenm.bsky.social and myself on a new project bridging Computational Linguistics methods and Language Acquisition questions, with a focus on the learning of modal verbs.
Come work with Annemarie van Dooren, @yevgenm.bsky.social and myself on a new project bridging Computational Linguistics methods and Language Acquisition questions, with a focus on the learning of modal verbs.

Interested in a paid PhD position in the Netherlands? Join me, Annemarie van Dooren, and @arianna-bis.bsky.social on a project to develop computational models of modal verb acquisition. A job ad will be out soon, but here's a preview: yevgen.web.rug.nl/phd.pdf
yevgen.web.rug.nl
March 11, 2025 at 2:32 PM
📣 Soon-to-open PhD position @gronlp.bsky.social:
Come work with Annemarie van Dooren, @yevgenm.bsky.social and myself on a new project bridging Computational Linguistics methods and Language Acquisition questions, with a focus on the learning of modal verbs.
Come work with Annemarie van Dooren, @yevgenm.bsky.social and myself on a new project bridging Computational Linguistics methods and Language Acquisition questions, with a focus on the learning of modal verbs.