



This introduces negligible noise to the original image and does not alter its semantic content at all.

April 30, 2025 at 5:36 PM
This introduces negligible noise to the original image and does not alter its semantic content at all.
We show results against the Tree-Rings, RingID, WIND and Gaussian Shading watermarking schemes and show that we can forge them with 90%+ success using a single watermarked example and a simple adversarial attack.

April 30, 2025 at 5:35 PM
We show results against the Tree-Rings, RingID, WIND and Gaussian Shading watermarking schemes and show that we can forge them with 90%+ success using a single watermarked example and a simple adversarial attack.
Our attack simply consists of perturbing the original image such that we can push it into this vulnerable region for forgery and away from it for removal.

April 30, 2025 at 5:35 PM
Our attack simply consists of perturbing the original image such that we can push it into this vulnerable region for forgery and away from it for removal.
We show that since DDIM inversion takes place with an empty prompt there is an entire region in the clean latent space which gets mapped back to the secret key embedded latent. We in-fact show that this region is linearly separable and can also be used for forgery or removal (used as motivation).

April 30, 2025 at 5:34 PM
We show that since DDIM inversion takes place with an empty prompt there is an entire region in the clean latent space which gets mapped back to the secret key embedded latent. We in-fact show that this region is linearly separable and can also be used for forgery or removal (used as motivation).
Think your latent-noise diffusion watermarking method is robust? Think again!
We show that they are susceptible to simple adversarial attacks that only require one watermarked example and an off-the-shelf encoder. This attack can forge and remove the watermark with very high accuracy.
We show that they are susceptible to simple adversarial attacks that only require one watermarked example and an off-the-shelf encoder. This attack can forge and remove the watermark with very high accuracy.

April 30, 2025 at 5:32 PM
Think your latent-noise diffusion watermarking method is robust? Think again!
We show that they are susceptible to simple adversarial attacks that only require one watermarked example and an off-the-shelf encoder. This attack can forge and remove the watermark with very high accuracy.
We show that they are susceptible to simple adversarial attacks that only require one watermarked example and an off-the-shelf encoder. This attack can forge and remove the watermark with very high accuracy.
This loss is specifically designed as a Gaussian such that unrelated concepts that are far away will not be impacted.
Our approach, TraSCE, achieves SOTA results on various jailbreaking benchmarks aimed at generating NSFW content. (5/n)
Our approach, TraSCE, achieves SOTA results on various jailbreaking benchmarks aimed at generating NSFW content. (5/n)

December 18, 2024 at 8:11 PM
This loss is specifically designed as a Gaussian such that unrelated concepts that are far away will not be impacted.
Our approach, TraSCE, achieves SOTA results on various jailbreaking benchmarks aimed at generating NSFW content. (5/n)
Our approach, TraSCE, achieves SOTA results on various jailbreaking benchmarks aimed at generating NSFW content. (5/n)
Diffusion models are amazing at generating high-quality images of what you ask them for, but can also generate things you didn't ask for. How do you stop a diffusion model from generating unwanted content such as nudity, violence, or the style of a particular artist? We introduce TraSCE (1/n)

December 18, 2024 at 8:07 PM
Diffusion models are amazing at generating high-quality images of what you ask them for, but can also generate things you didn't ask for. How do you stop a diffusion model from generating unwanted content such as nudity, violence, or the style of a particular artist? We introduce TraSCE (1/n)
We apply either no guidance or opposite guidance till an ideal transition point occurs. Where switching to standard classifier-free guidance is unlikely to generate a memorized image.

December 4, 2024 at 9:05 PM
We apply either no guidance or opposite guidance till an ideal transition point occurs. Where switching to standard classifier-free guidance is unlikely to generate a memorized image.
Have you ever wondered why diffusion models memorize and all initializations lead to the same training sample? As we show, this is because like in dynamic systems, the memorized sample acts as an attractor and a corresponding attraction basin is formed in the denoising trajectory.
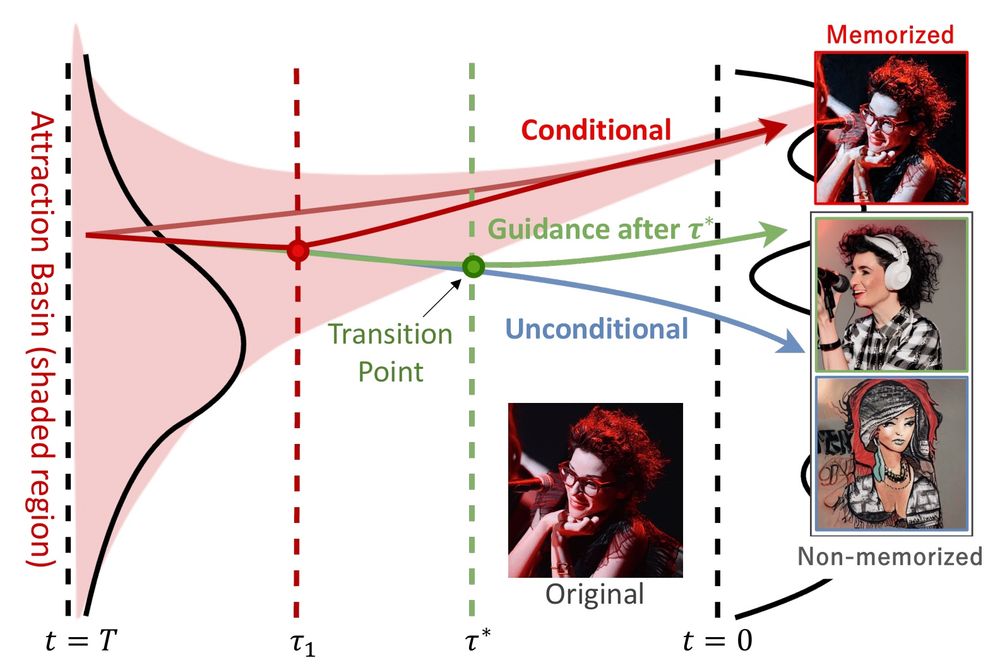
December 4, 2024 at 9:03 PM
Have you ever wondered why diffusion models memorize and all initializations lead to the same training sample? As we show, this is because like in dynamic systems, the memorized sample acts as an attractor and a corresponding attraction basin is formed in the denoising trajectory.