




Anshul Kundaje
@anshulkundaje.bsky.social
Genomics, Machine Learning, Statistics, Big Data and Football (Soccer, GGMU)
@jengreitz.bsky.social l & my lab want to co-hire a computational biologist/biostatistician with project management expertise to help map the regulatory code of the human genome and discover genetic mechanisms of disease.
Details below
careersearch.stanford.edu/jobs/computa...
Plz RT
Details below
careersearch.stanford.edu/jobs/computa...
Plz RT

August 19, 2025 at 12:29 AM
@jengreitz.bsky.social l & my lab want to co-hire a computational biologist/biostatistician with project management expertise to help map the regulatory code of the human genome and discover genetic mechanisms of disease.
Details below
careersearch.stanford.edu/jobs/computa...
Plz RT
Details below
careersearch.stanford.edu/jobs/computa...
Plz RT
Job Alert: A stealth startup focused on non-cancer diagnostics is keen to hire a deep learning for genomics/bio engineer. I am an advisor for the startup & closely involved. Please see the job description below and get in touch if interested. Plz forward.

August 12, 2025 at 12:35 AM
Job Alert: A stealth startup focused on non-cancer diagnostics is keen to hire a deep learning for genomics/bio engineer. I am an advisor for the startup & closely involved. Please see the job description below and get in touch if interested. Plz forward.
Thanks to @riyavsinha.bsky.social in my lab, the IGV browser will natively support dynseq (dynamic sequence tracks) in an upcoming release. These tracks are very useful to directly visualize base-resolution scores (e.g. contribution scores from ML models, conservation etc). 1/
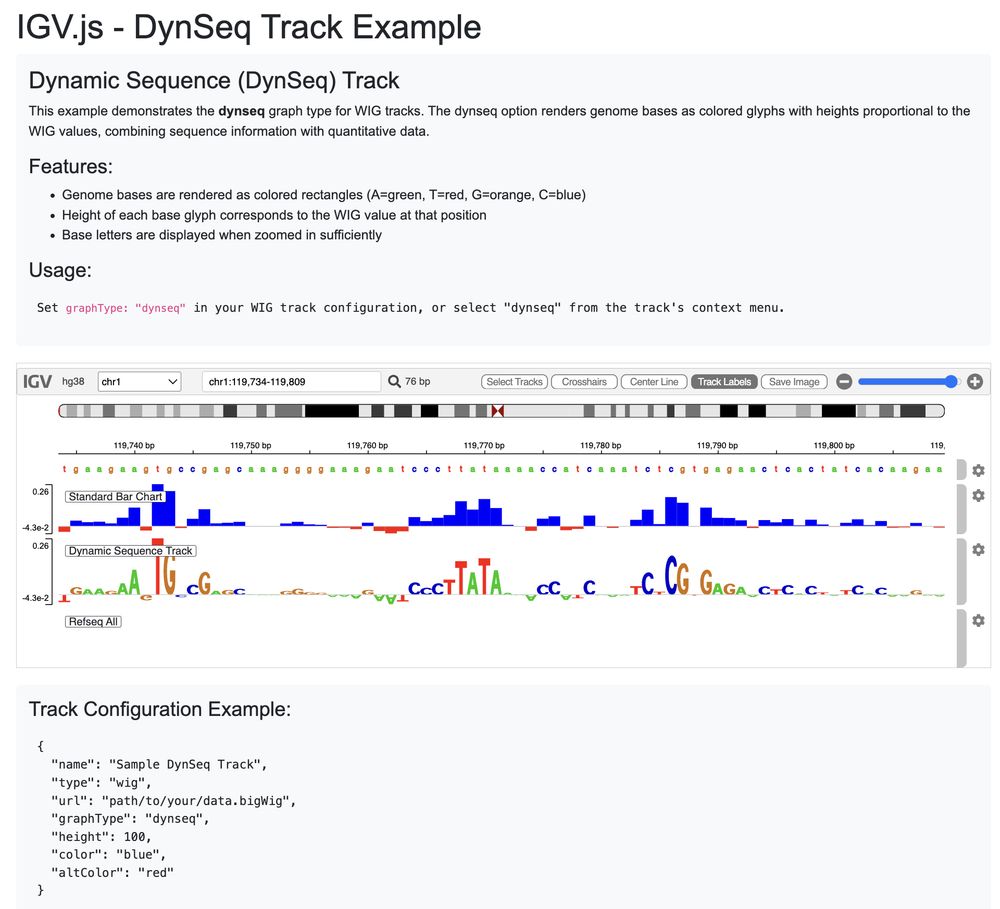
July 29, 2025 at 3:06 PM
Thanks to @riyavsinha.bsky.social in my lab, the IGV browser will natively support dynseq (dynamic sequence tracks) in an upcoming release. These tracks are very useful to directly visualize base-resolution scores (e.g. contribution scores from ML models, conservation etc). 1/
@saramostafavi.bsky.social (@Genentech) & I (@Stanford) r excited to announce co-advised postdoc positions for candidates with deep expertise in ML for bio (especially sequence to function models, causal perturbational models & single cell models). See details below. Pls RT 1/

June 19, 2025 at 8:55 PM
@saramostafavi.bsky.social (@Genentech) & I (@Stanford) r excited to announce co-advised postdoc positions for candidates with deep expertise in ML for bio (especially sequence to function models, causal perturbational models & single cell models). See details below. Pls RT 1/
Today was a big day for the lab. We had two back to back thesis defenses and the defenders defended with great science and character.
Congrats to DR. Kelly Cochran & DR. @soumyakundu.bsky.social on this momentous achievement.
Brilliant scientists with brilliant futures ahead. 🎉🎉🎉
Congrats to DR. Kelly Cochran & DR. @soumyakundu.bsky.social on this momentous achievement.
Brilliant scientists with brilliant futures ahead. 🎉🎉🎉

May 15, 2025 at 5:19 AM
Today was a big day for the lab. We had two back to back thesis defenses and the defenders defended with great science and character.
Congrats to DR. Kelly Cochran & DR. @soumyakundu.bsky.social on this momentous achievement.
Brilliant scientists with brilliant futures ahead. 🎉🎉🎉
Congrats to DR. Kelly Cochran & DR. @soumyakundu.bsky.social on this momentous achievement.
Brilliant scientists with brilliant futures ahead. 🎉🎉🎉
And if you look at Fig S3D in the paper, EVO2 is tested on regulatory caQTL prediction tasks from our DART-EVAL benchmark.
They did not show the ChromBPNet baseline which has an AUROC of 0.77 and 0.89 on these tasks, which is substantially higher than the biggest of the EVO models.
They did not show the ChromBPNet baseline which has an AUROC of 0.77 and 0.89 on these tasks, which is substantially higher than the biggest of the EVO models.

March 5, 2025 at 6:45 AM
And if you look at Fig S3D in the paper, EVO2 is tested on regulatory caQTL prediction tasks from our DART-EVAL benchmark.
They did not show the ChromBPNet baseline which has an AUROC of 0.77 and 0.89 on these tasks, which is substantially higher than the biggest of the EVO models.
They did not show the ChromBPNet baseline which has an AUROC of 0.77 and 0.89 on these tasks, which is substantially higher than the biggest of the EVO models.
AGI has been achieved. All hail Grok 3 (beta)

February 22, 2025 at 10:19 PM
AGI has been achieved. All hail Grok 3 (beta)
Decent turnout today. Good to see that there are plenty of good folks who won't give up without a fight.
Important to take back Congress and Senate as soon as possible.
And to drown Elmo, DOGE and the Orange buffoon in court cases. Do everything possible to slow them down.
Important to take back Congress and Senate as soon as possible.
And to drown Elmo, DOGE and the Orange buffoon in court cases. Do everything possible to slow them down.
February 17, 2025 at 12:00 AM
Decent turnout today. Good to see that there are plenty of good folks who won't give up without a fight.
Important to take back Congress and Senate as soon as possible.
And to drown Elmo, DOGE and the Orange buffoon in court cases. Do everything possible to slow them down.
Important to take back Congress and Senate as soon as possible.
And to drown Elmo, DOGE and the Orange buffoon in court cases. Do everything possible to slow them down.
We see no loss in performance at all for kmers seen in the training data vs. those never seen. (Fig 2E vs 2F).
www.biorxiv.org/content/bior...
5/5
www.biorxiv.org/content/bior...
5/5

January 30, 2025 at 5:41 PM
We see no loss in performance at all for kmers seen in the training data vs. those never seen. (Fig 2E vs 2F).
www.biorxiv.org/content/bior...
5/5
www.biorxiv.org/content/bior...
5/5






If u click on that series ID, it will show the corresponding RNA data
This can be directly & programmatically accessed using the portal API.
Will provide a table that links these to make it a bit easier as well.
This can be directly & programmatically accessed using the portal API.
Will provide a table that links these to make it a bit easier as well.

January 7, 2025 at 11:54 PM
If u click on that series ID, it will show the corresponding RNA data
This can be directly & programmatically accessed using the portal API.
Will provide a table that links these to make it a bit easier as well.
This can be directly & programmatically accessed using the portal API.
Will provide a table that links these to make it a bit easier as well.
Ok so here is an example
Lets say u look at this snATAC dataset www.encodeproject.org/experiments/...
You will notice that the medata has a term called "Multiomic series" (see attached figure). 1/
Lets say u look at this snATAC dataset www.encodeproject.org/experiments/...
You will notice that the medata has a term called "Multiomic series" (see attached figure). 1/

January 7, 2025 at 11:54 PM
Ok so here is an example
Lets say u look at this snATAC dataset www.encodeproject.org/experiments/...
You will notice that the medata has a term called "Multiomic series" (see attached figure). 1/
Lets say u look at this snATAC dataset www.encodeproject.org/experiments/...
You will notice that the medata has a term called "Multiomic series" (see attached figure). 1/
Here is a summary of the ones we evaluated in our benchmark paper
arxiv.org/abs/2412.05430
Span range of tokenization schemes. Conv. r good fit for reg. DNA but not for coding DNA. These models r trained genome-wide so they have to adapt to different classes of DNA. Hence, mostly use transformers.
arxiv.org/abs/2412.05430
Span range of tokenization schemes. Conv. r good fit for reg. DNA but not for coding DNA. These models r trained genome-wide so they have to adapt to different classes of DNA. Hence, mostly use transformers.

December 12, 2024 at 6:31 PM
Here is a summary of the ones we evaluated in our benchmark paper
arxiv.org/abs/2412.05430
Span range of tokenization schemes. Conv. r good fit for reg. DNA but not for coding DNA. These models r trained genome-wide so they have to adapt to different classes of DNA. Hence, mostly use transformers.
arxiv.org/abs/2412.05430
Span range of tokenization schemes. Conv. r good fit for reg. DNA but not for coding DNA. These models r trained genome-wide so they have to adapt to different classes of DNA. Hence, mostly use transformers.
Check out Aman Patel's plenary talk at #ASHG23 #ASHG #ASHG2023 tomorrow. He will explore the regulatory impact of genetic variants from archaic hominids using deep learning models of chromatin accessibility profiles of > 1000 diverse ENCODE biosamples from modern humans! Details below


November 1, 2023 at 1:21 PM