



Anja Reusch
@anja.re
👩💻 Postdoc @ Technion, interested in Interpretability in IR 🔎 and NLP 💬
Reposted by Anja Reusch

🤔What happens when LLM agents choose between achieving their goals and avoiding harm to humans in realistic management scenarios? Are LLMs pragmatic or prefer to avoid human harm?
🚀 New paper out: ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs🚀🧵
🚀 New paper out: ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs🚀🧵

October 8, 2025 at 3:14 PM
🤔What happens when LLM agents choose between achieving their goals and avoiding harm to humans in realistic management scenarios? Are LLMs pragmatic or prefer to avoid human harm?
🚀 New paper out: ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs🚀🧵
🚀 New paper out: ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs🚀🧵
Reposted by Anja Reusch

If you're at #ICML2025, chat with me, @sarah-nlp.bsky.social, Atticus, and others at our poster 11am - 1:30pm at East #1205! We're establishing a 𝗠echanistic 𝗜nterpretability 𝗕enchmark.
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!

July 17, 2025 at 5:45 PM
If you're at #ICML2025, chat with me, @sarah-nlp.bsky.social, Atticus, and others at our poster 11am - 1:30pm at East #1205! We're establishing a 𝗠echanistic 𝗜nterpretability 𝗕enchmark.
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
Reposted by Anja Reusch

Working on circuit discovery in LMs?
Consider submitting your work to the MIB Shared Task, part of #BlackboxNLP at @emnlpmeeting.bsky.social 2025!
The goal: benchmark existing MI methods and identify promising directions to precisely and concisely recover causal pathways in LMs >>
Consider submitting your work to the MIB Shared Task, part of #BlackboxNLP at @emnlpmeeting.bsky.social 2025!
The goal: benchmark existing MI methods and identify promising directions to precisely and concisely recover causal pathways in LMs >>

June 24, 2025 at 2:24 PM
Working on circuit discovery in LMs?
Consider submitting your work to the MIB Shared Task, part of #BlackboxNLP at @emnlpmeeting.bsky.social 2025!
The goal: benchmark existing MI methods and identify promising directions to precisely and concisely recover causal pathways in LMs >>
Consider submitting your work to the MIB Shared Task, part of #BlackboxNLP at @emnlpmeeting.bsky.social 2025!
The goal: benchmark existing MI methods and identify promising directions to precisely and concisely recover causal pathways in LMs >>
Reposted by Anja Reusch

🚨 We're looking for more reviewers for the workshop!
📆 Review period: May 24-June 7
If you're passionate about making interpretability useful and want to help shape the conversation, we'd love your input.
💡🔍 Self-nominate here:
docs.google.com/forms/d/e/1F...
📆 Review period: May 24-June 7
If you're passionate about making interpretability useful and want to help shape the conversation, we'd love your input.
💡🔍 Self-nominate here:
docs.google.com/forms/d/e/1F...

May 20, 2025 at 12:05 AM
🚨 We're looking for more reviewers for the workshop!
📆 Review period: May 24-June 7
If you're passionate about making interpretability useful and want to help shape the conversation, we'd love your input.
💡🔍 Self-nominate here:
docs.google.com/forms/d/e/1F...
📆 Review period: May 24-June 7
If you're passionate about making interpretability useful and want to help shape the conversation, we'd love your input.
💡🔍 Self-nominate here:
docs.google.com/forms/d/e/1F...
Reposted by Anja Reusch

We knew many of you wanted to submit to our Actionable Interpretability workshop, but we didn’t expect to crash Overleaf! 😏🍃
Only 5 days left ⏰!
Got a paper accepted to ICML that fits our theme?
Submit it to our conference track!
👉 @actinterp.bsky.social
Only 5 days left ⏰!
Got a paper accepted to ICML that fits our theme?
Submit it to our conference track!
👉 @actinterp.bsky.social

May 14, 2025 at 1:04 PM
We knew many of you wanted to submit to our Actionable Interpretability workshop, but we didn’t expect to crash Overleaf! 😏🍃
Only 5 days left ⏰!
Got a paper accepted to ICML that fits our theme?
Submit it to our conference track!
👉 @actinterp.bsky.social
Only 5 days left ⏰!
Got a paper accepted to ICML that fits our theme?
Submit it to our conference track!
👉 @actinterp.bsky.social
Reposted by Anja Reusch

Deadline extended! ⏳
The Actionable Interpretability Workshop at #ICML2025 has moved its submission deadline to May 19th. More time to submit your work 🔍🧠✨ Don’t miss out!
The Actionable Interpretability Workshop at #ICML2025 has moved its submission deadline to May 19th. More time to submit your work 🔍🧠✨ Don’t miss out!

May 3, 2025 at 8:00 PM
Deadline extended! ⏳
The Actionable Interpretability Workshop at #ICML2025 has moved its submission deadline to May 19th. More time to submit your work 🔍🧠✨ Don’t miss out!
The Actionable Interpretability Workshop at #ICML2025 has moved its submission deadline to May 19th. More time to submit your work 🔍🧠✨ Don’t miss out!
Reposted by Anja Reusch
Lots of progress in mech interp (MI) lately! But how can we measure when new mech interp methods yield real improvements over prior work?
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!

April 23, 2025 at 6:15 PM
Lots of progress in mech interp (MI) lately! But how can we measure when new mech interp methods yield real improvements over prior work?
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
Reposted by Anja Reusch
🚨 Call for Papers is Out!
The First Workshop on 𝐀𝐜𝐭𝐢𝐨𝐧𝐚𝐛𝐥𝐞 𝐈𝐧𝐭𝐞𝐫𝐩𝐫𝐞𝐭𝐚𝐛𝐢𝐥𝐢𝐭𝐲 will be held at ICML 2025 in Vancouver!
📅 Submission Deadline: May 9
Follow us >> @ActInterp
🧠Topics of interest include: 👇
The First Workshop on 𝐀𝐜𝐭𝐢𝐨𝐧𝐚𝐛𝐥𝐞 𝐈𝐧𝐭𝐞𝐫𝐩𝐫𝐞𝐭𝐚𝐛𝐢𝐥𝐢𝐭𝐲 will be held at ICML 2025 in Vancouver!
📅 Submission Deadline: May 9
Follow us >> @ActInterp
🧠Topics of interest include: 👇

April 7, 2025 at 1:51 PM
🚨 Call for Papers is Out!
The First Workshop on 𝐀𝐜𝐭𝐢𝐨𝐧𝐚𝐛𝐥𝐞 𝐈𝐧𝐭𝐞𝐫𝐩𝐫𝐞𝐭𝐚𝐛𝐢𝐥𝐢𝐭𝐲 will be held at ICML 2025 in Vancouver!
📅 Submission Deadline: May 9
Follow us >> @ActInterp
🧠Topics of interest include: 👇
The First Workshop on 𝐀𝐜𝐭𝐢𝐨𝐧𝐚𝐛𝐥𝐞 𝐈𝐧𝐭𝐞𝐫𝐩𝐫𝐞𝐭𝐚𝐛𝐢𝐥𝐢𝐭𝐲 will be held at ICML 2025 in Vancouver!
📅 Submission Deadline: May 9
Follow us >> @ActInterp
🧠Topics of interest include: 👇
Reposted by Anja Reusch

Have work on the actionable impact of interpretability findings? Consider submitting to our Actionable Interpretability workshop at ICML! See below for more info.
Website: actionable-interpretability.github.io
Deadline: May 9
Website: actionable-interpretability.github.io
Deadline: May 9
🎉 Our Actionable Interpretability workshop has been accepted to #ICML2025! 🎉
> Follow @actinterp.bsky.social
> Website actionable-interpretability.github.io
@talhaklay.bsky.social @anja.re @mariusmosbach.bsky.social @sarah-nlp.bsky.social @iftenney.bsky.social
Paper submission deadline: May 9th!
> Follow @actinterp.bsky.social
> Website actionable-interpretability.github.io
@talhaklay.bsky.social @anja.re @mariusmosbach.bsky.social @sarah-nlp.bsky.social @iftenney.bsky.social
Paper submission deadline: May 9th!

April 3, 2025 at 5:58 PM
Have work on the actionable impact of interpretability findings? Consider submitting to our Actionable Interpretability workshop at ICML! See below for more info.
Website: actionable-interpretability.github.io
Deadline: May 9
Website: actionable-interpretability.github.io
Deadline: May 9
Reposted by Anja Reusch

🎉 Our Actionable Interpretability workshop has been accepted to #ICML2025! 🎉
> Follow @actinterp.bsky.social
> Website actionable-interpretability.github.io
@talhaklay.bsky.social @anja.re @mariusmosbach.bsky.social @sarah-nlp.bsky.social @iftenney.bsky.social
Paper submission deadline: May 9th!
> Follow @actinterp.bsky.social
> Website actionable-interpretability.github.io
@talhaklay.bsky.social @anja.re @mariusmosbach.bsky.social @sarah-nlp.bsky.social @iftenney.bsky.social
Paper submission deadline: May 9th!
March 31, 2025 at 4:59 PM
🎉 Our Actionable Interpretability workshop has been accepted to #ICML2025! 🎉
> Follow @actinterp.bsky.social
> Website actionable-interpretability.github.io
@talhaklay.bsky.social @anja.re @mariusmosbach.bsky.social @sarah-nlp.bsky.social @iftenney.bsky.social
Paper submission deadline: May 9th!
> Follow @actinterp.bsky.social
> Website actionable-interpretability.github.io
@talhaklay.bsky.social @anja.re @mariusmosbach.bsky.social @sarah-nlp.bsky.social @iftenney.bsky.social
Paper submission deadline: May 9th!
Reposted by Anja Reusch
(ICLR) How do LLMs perform arithmetic operations? Do they implement robust algorithms, or rely on heuristics? We find that they rely on a "bag of heuristics" that work well—but on a limited range of inputs.
Led by Yaniv Nikankin: arxiv.org/abs/2410.21272
Led by Yaniv Nikankin: arxiv.org/abs/2410.21272

Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics
Do large language models (LLMs) solve reasoning tasks by learning robust generalizable algorithms, or do they memorize training data? To investigate this question, we use arithmetic reasoning as a rep...
arxiv.org
March 11, 2025 at 2:30 PM
(ICLR) How do LLMs perform arithmetic operations? Do they implement robust algorithms, or rely on heuristics? We find that they rely on a "bag of heuristics" that work well—but on a limited range of inputs.
Led by Yaniv Nikankin: arxiv.org/abs/2410.21272
Led by Yaniv Nikankin: arxiv.org/abs/2410.21272
Reposted by Anja Reusch
1/13 LLM circuits tell us where the computation happens inside the model—but the computation varies by token position, a key detail often ignored!
We propose a method to automatically find position-aware circuits, improving faithfulness while keeping circuits compact. 🧵👇
We propose a method to automatically find position-aware circuits, improving faithfulness while keeping circuits compact. 🧵👇

March 6, 2025 at 10:15 PM
1/13 LLM circuits tell us where the computation happens inside the model—but the computation varies by token position, a key detail often ignored!
We propose a method to automatically find position-aware circuits, improving faithfulness while keeping circuits compact. 🧵👇
We propose a method to automatically find position-aware circuits, improving faithfulness while keeping circuits compact. 🧵👇
Reposted by Anja Reusch

🚨New arXiv preprint!🚨
LLMs can hallucinate - but did you know they can do so with high certainty even when they know the correct answer? 🤯
We find those hallucinations in our latest work with @itay-itzhak.bsky.social, @fbarez.bsky.social, @gabistanovsky.bsky.social and Yonatan Belinkov
LLMs can hallucinate - but did you know they can do so with high certainty even when they know the correct answer? 🤯
We find those hallucinations in our latest work with @itay-itzhak.bsky.social, @fbarez.bsky.social, @gabistanovsky.bsky.social and Yonatan Belinkov

February 19, 2025 at 3:50 PM
🚨New arXiv preprint!🚨
LLMs can hallucinate - but did you know they can do so with high certainty even when they know the correct answer? 🤯
We find those hallucinations in our latest work with @itay-itzhak.bsky.social, @fbarez.bsky.social, @gabistanovsky.bsky.social and Yonatan Belinkov
LLMs can hallucinate - but did you know they can do so with high certainty even when they know the correct answer? 🤯
We find those hallucinations in our latest work with @itay-itzhak.bsky.social, @fbarez.bsky.social, @gabistanovsky.bsky.social and Yonatan Belinkov
Reposted by Anja Reusch
🚨🚨 New preprint 🚨🚨
Ever wonder whether verbalized CoTs correspond to the internal reasoning process of the model?
We propose a novel parametric faithfulness approach, which erases information contained in CoT steps from the model parameters to assess CoT faithfulness.
arxiv.org/abs/2502.14829
Ever wonder whether verbalized CoTs correspond to the internal reasoning process of the model?
We propose a novel parametric faithfulness approach, which erases information contained in CoT steps from the model parameters to assess CoT faithfulness.
arxiv.org/abs/2502.14829

Measuring Faithfulness of Chains of Thought by Unlearning Reasoning Steps
When prompted to think step-by-step, language models (LMs) produce a chain of thought (CoT), a sequence of reasoning steps that the model supposedly used to produce its prediction. However, despite mu...
arxiv.org
February 21, 2025 at 12:43 PM
🚨🚨 New preprint 🚨🚨
Ever wonder whether verbalized CoTs correspond to the internal reasoning process of the model?
We propose a novel parametric faithfulness approach, which erases information contained in CoT steps from the model parameters to assess CoT faithfulness.
arxiv.org/abs/2502.14829
Ever wonder whether verbalized CoTs correspond to the internal reasoning process of the model?
We propose a novel parametric faithfulness approach, which erases information contained in CoT steps from the model parameters to assess CoT faithfulness.
arxiv.org/abs/2502.14829
Reposted by Anja Reusch

I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
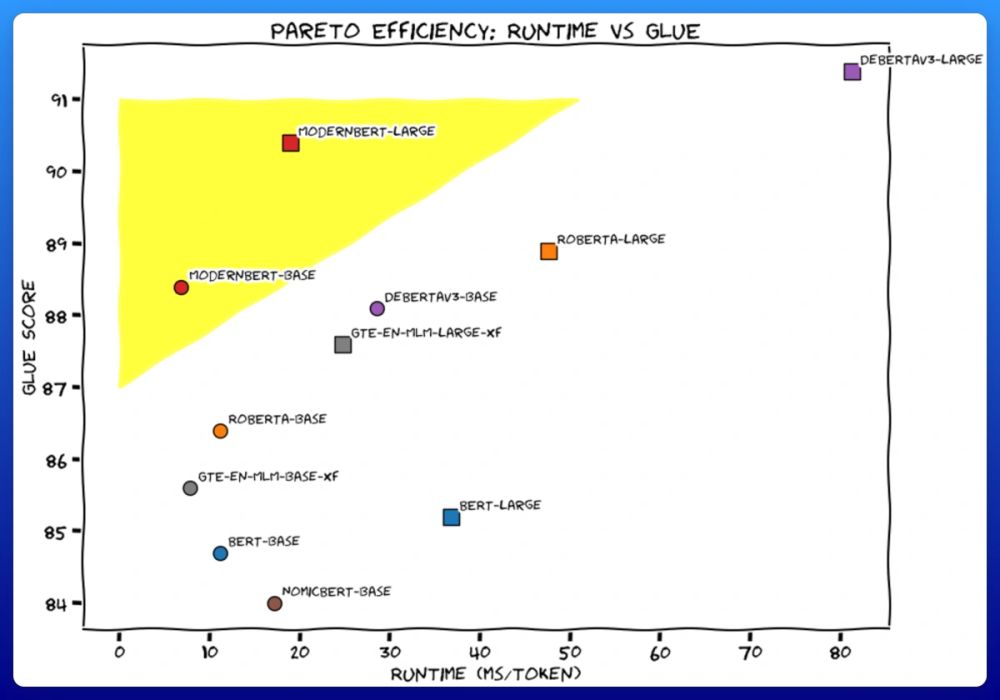
December 19, 2024 at 4:45 PM
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵