



@anianruoss.bsky.social
Fantastic work by @pardofab.bsky.social, @harrischan.bsky.social, @bonniesjli.bsky.social,
@vladmnih.bsky.social, and Tim Genewein!
All details and many more results in arxiv.org/abs/2412.01441
N/N
@vladmnih.bsky.social, and Tim Genewein!
All details and many more results in arxiv.org/abs/2412.01441
N/N

LMAct: A Benchmark for In-Context Imitation Learning with Long Multimodal Demonstrations
Today's largest foundation models have increasingly general capabilities, yet when used as agents, they often struggle with simple reasoning and decision-making tasks, even though they possess good fa...
arxiv.org
December 3, 2024 at 5:15 PM
Fantastic work by @pardofab.bsky.social, @harrischan.bsky.social, @bonniesjli.bsky.social,
@vladmnih.bsky.social, and Tim Genewein!
All details and many more results in arxiv.org/abs/2412.01441
N/N
@vladmnih.bsky.social, and Tim Genewein!
All details and many more results in arxiv.org/abs/2412.01441
N/N
As a sanity check, we also evaluate how well frontier models can replay the actions from a single demonstration episode (i.e., teacher-forcing, usually we perform dynamic evaluation).
Most models perform well, with the exception of o1-mini, which fails across most tasks.
5/N
Most models perform well, with the exception of o1-mini, which fails across most tasks.
5/N

December 3, 2024 at 5:15 PM
As a sanity check, we also evaluate how well frontier models can replay the actions from a single demonstration episode (i.e., teacher-forcing, usually we perform dynamic evaluation).
Most models perform well, with the exception of o1-mini, which fails across most tasks.
5/N
Most models perform well, with the exception of o1-mini, which fails across most tasks.
5/N
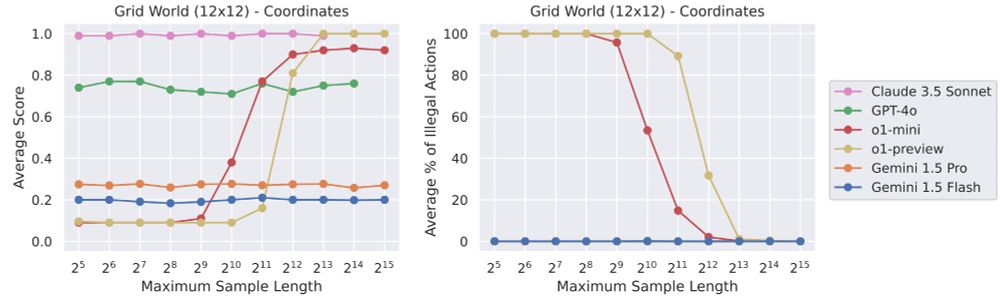
We pressure-test frontier models' in-context imitation learning, using up to 1M context size and up to 10k output ("reasoning") tokens.
For o1-mini/o1-preview, performance crucially depends on having many (at least 8192) output tokens, even in simple decision-making tasks.
4/N
For o1-mini/o1-preview, performance crucially depends on having many (at least 8192) output tokens, even in simple decision-making tasks.
4/N
December 3, 2024 at 5:15 PM
We pressure-test frontier models' in-context imitation learning, using up to 1M context size and up to 10k output ("reasoning") tokens.
For o1-mini/o1-preview, performance crucially depends on having many (at least 8192) output tokens, even in simple decision-making tasks.
4/N
For o1-mini/o1-preview, performance crucially depends on having many (at least 8192) output tokens, even in simple decision-making tasks.
4/N
We evaluate most tasks with different multimodal observation formats (e.g., ASCII, RGB images).
On some tasks, certain models show strong in-context imitation learning (e.g., Gemini 1.5 below). On others, the performance is independent of the expert demonstration episodes.
3/N
On some tasks, certain models show strong in-context imitation learning (e.g., Gemini 1.5 below). On others, the performance is independent of the expert demonstration episodes.
3/N

December 3, 2024 at 5:15 PM
We evaluate most tasks with different multimodal observation formats (e.g., ASCII, RGB images).
On some tasks, certain models show strong in-context imitation learning (e.g., Gemini 1.5 below). On others, the performance is independent of the expert demonstration episodes.
3/N
On some tasks, certain models show strong in-context imitation learning (e.g., Gemini 1.5 below). On others, the performance is independent of the expert demonstration episodes.
3/N
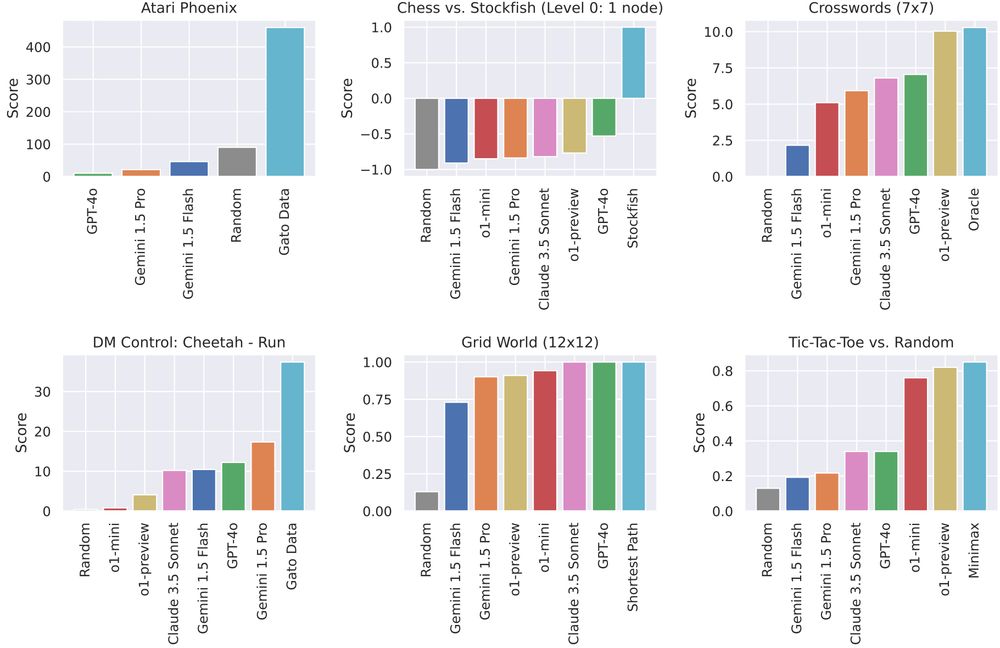
We evaluate
- Phoenix (Atari)
- chess vs weakest version of Stockfish
- crosswords
- cheetah run (DM Control)
- grid world navigation
- tic-tac-toe vs random actions
We compare against a random baseline and an expert policy and use up to 512 expert demonstration episodes:
2/N
- Phoenix (Atari)
- chess vs weakest version of Stockfish
- crosswords
- cheetah run (DM Control)
- grid world navigation
- tic-tac-toe vs random actions
We compare against a random baseline and an expert policy and use up to 512 expert demonstration episodes:
2/N
December 3, 2024 at 5:15 PM
We evaluate
- Phoenix (Atari)
- chess vs weakest version of Stockfish
- crosswords
- cheetah run (DM Control)
- grid world navigation
- tic-tac-toe vs random actions
We compare against a random baseline and an expert policy and use up to 512 expert demonstration episodes:
2/N
- Phoenix (Atari)
- chess vs weakest version of Stockfish
- crosswords
- cheetah run (DM Control)
- grid world navigation
- tic-tac-toe vs random actions
We compare against a random baseline and an expert policy and use up to 512 expert demonstration episodes:
2/N