



Andrea de Varda
@andreadevarda.bsky.social
Token count also captures differences across tasks. Avg. token count predicts avg. RT across domains (r = 0.97, left), and even item-level RTs across all tasks (r = 0.92 (!!), right). (5/6)

November 19, 2025 at 8:14 PM
Token count also captures differences across tasks. Avg. token count predicts avg. RT across domains (r = 0.97, left), and even item-level RTs across all tasks (r = 0.92 (!!), right). (5/6)
We found that the number of reasoning tokens generated by the model reliably correlates with human RTs within each task (mean r = 0.57, all ps < .001). (4/6)

November 19, 2025 at 8:14 PM
We found that the number of reasoning tokens generated by the model reliably correlates with human RTs within each task (mean r = 0.57, all ps < .001). (4/6)
Large reasoning models can solve many reasoning problems, but do their computations reflect how humans think?
We compared human RTs to DeepSeek-R1’s CoT length across seven tasks: arithmetic (numeric & verbal), logic (syllogisms & ALE), relational reasoning, intuitive reasoning, and ARC (3/6)
We compared human RTs to DeepSeek-R1’s CoT length across seven tasks: arithmetic (numeric & verbal), logic (syllogisms & ALE), relational reasoning, intuitive reasoning, and ARC (3/6)

November 19, 2025 at 8:14 PM
Large reasoning models can solve many reasoning problems, but do their computations reflect how humans think?
We compared human RTs to DeepSeek-R1’s CoT length across seven tasks: arithmetic (numeric & verbal), logic (syllogisms & ALE), relational reasoning, intuitive reasoning, and ARC (3/6)
We compared human RTs to DeepSeek-R1’s CoT length across seven tasks: arithmetic (numeric & verbal), logic (syllogisms & ALE), relational reasoning, intuitive reasoning, and ARC (3/6)
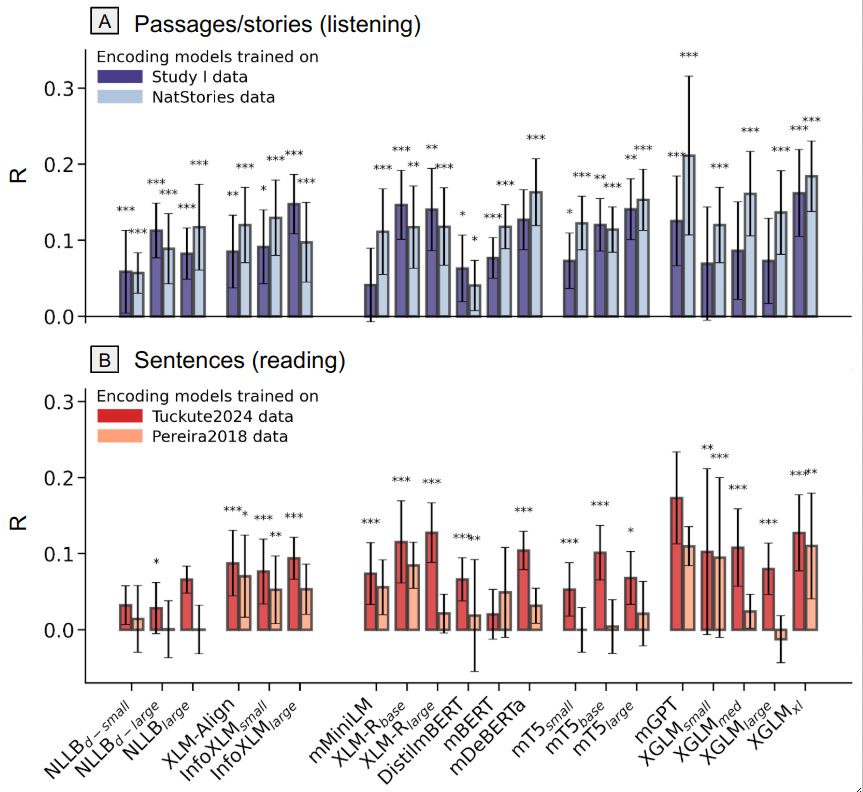
Encoding models trained on existing fMRI datasets successfully predicted responses in new languages, generalizing across stimuli types and modalities (11/)
February 4, 2025 at 6:03 PM
Encoding models trained on existing fMRI datasets successfully predicted responses in new languages, generalizing across stimuli types and modalities (11/)
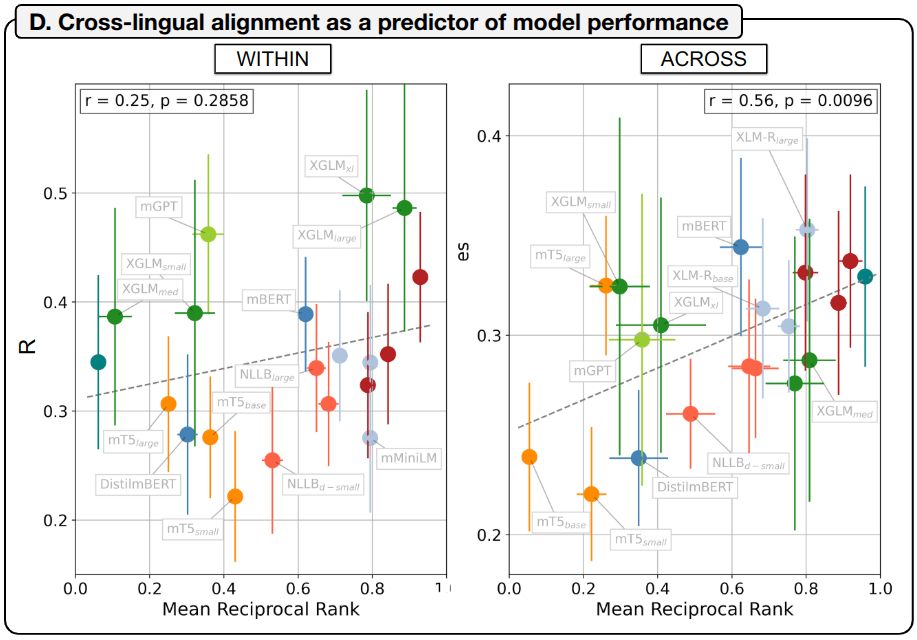
In the “across” condition, performance improves for models with stronger cross-lingual semantic alignment (where translations cluster together in the embedding space) (9/)
February 4, 2025 at 6:03 PM
In the “across” condition, performance improves for models with stronger cross-lingual semantic alignment (where translations cluster together in the embedding space) (9/)
But what kind of model properties influence LM-to-brain alignment across languages?
In the “within” condition, encoding performance is highest for models with good next-word prediction abilities (8/)
In the “within” condition, encoding performance is highest for models with good next-word prediction abilities (8/)
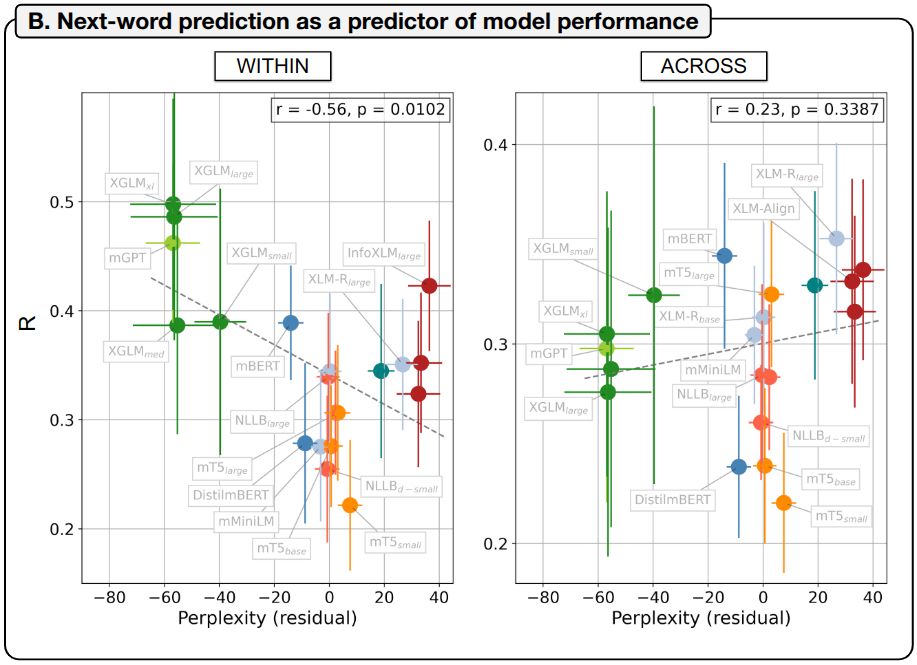
February 4, 2025 at 6:03 PM
But what kind of model properties influence LM-to-brain alignment across languages?
In the “within” condition, encoding performance is highest for models with good next-word prediction abilities (8/)
In the “within” condition, encoding performance is highest for models with good next-word prediction abilities (8/)
We also replicated in a cross-lingual setting the finding that the best fit to brain responses is obtained in intermediate-to-deep layers (for each subplot pair, the left one is “within”, the right one “across”) (7/)
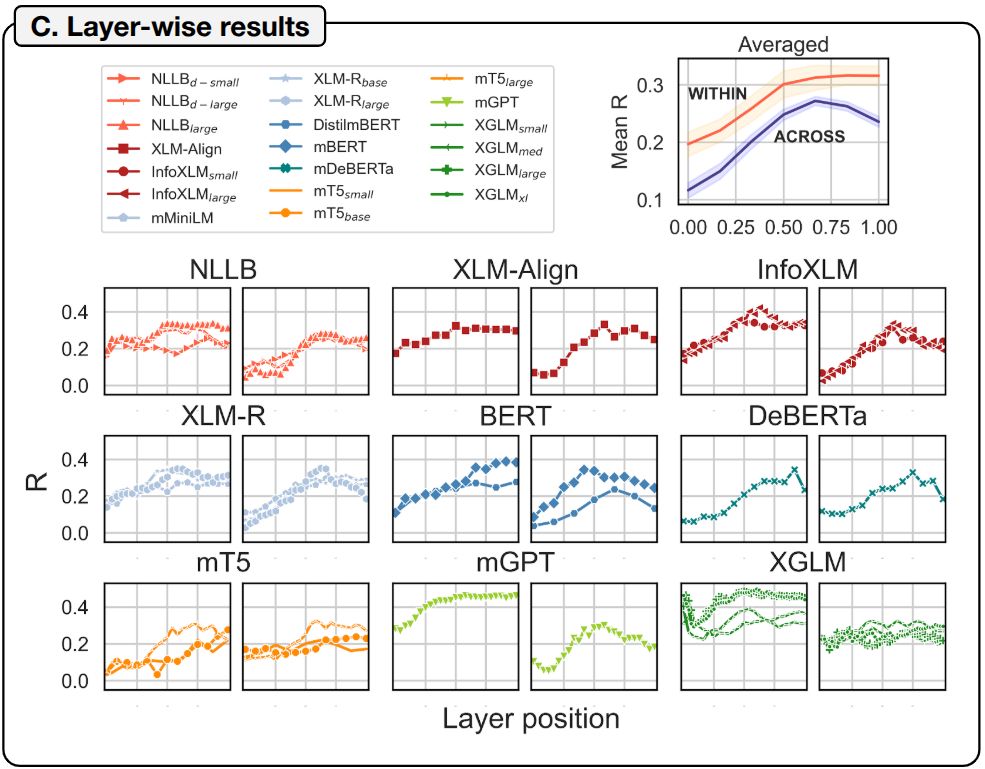
February 4, 2025 at 6:03 PM
We also replicated in a cross-lingual setting the finding that the best fit to brain responses is obtained in intermediate-to-deep layers (for each subplot pair, the left one is “within”, the right one “across”) (7/)
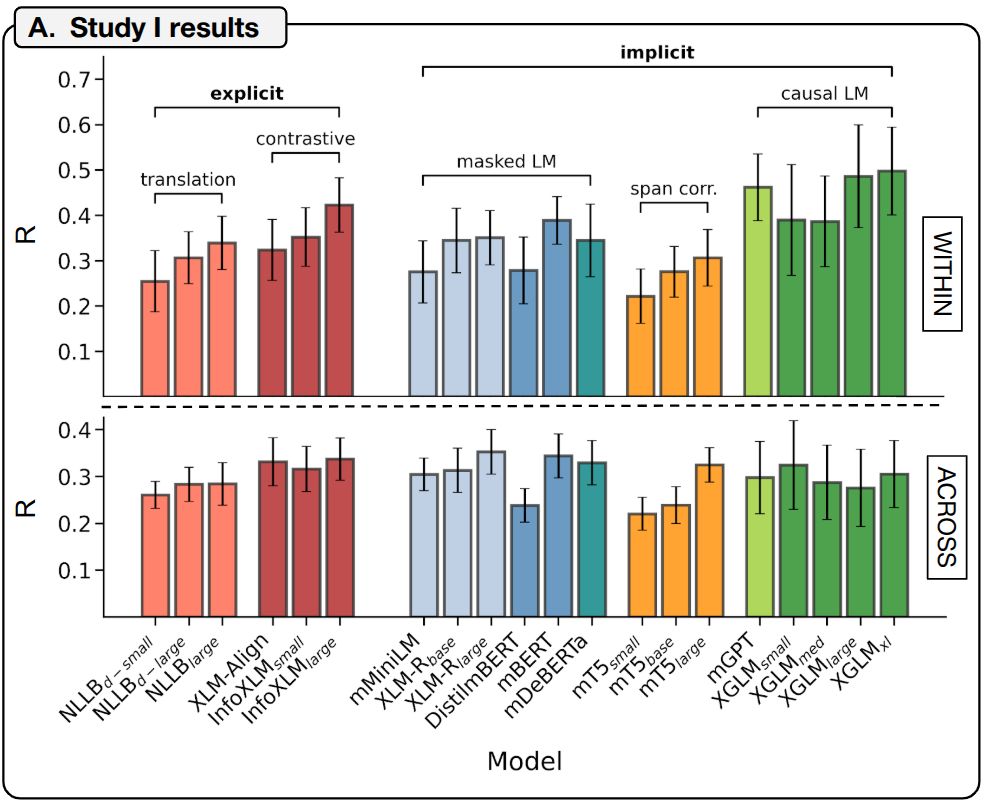
We evaluated 20 multilingual LMs with different architectures and training objectives, and all of them were able to predict brain responses in the various languages (“within”) and critically, generalized zero-shot to unseen languages (“across”) (6/)
February 4, 2025 at 6:03 PM
We evaluated 20 multilingual LMs with different architectures and training objectives, and all of them were able to predict brain responses in the various languages (“within”) and critically, generalized zero-shot to unseen languages (“across”) (6/)
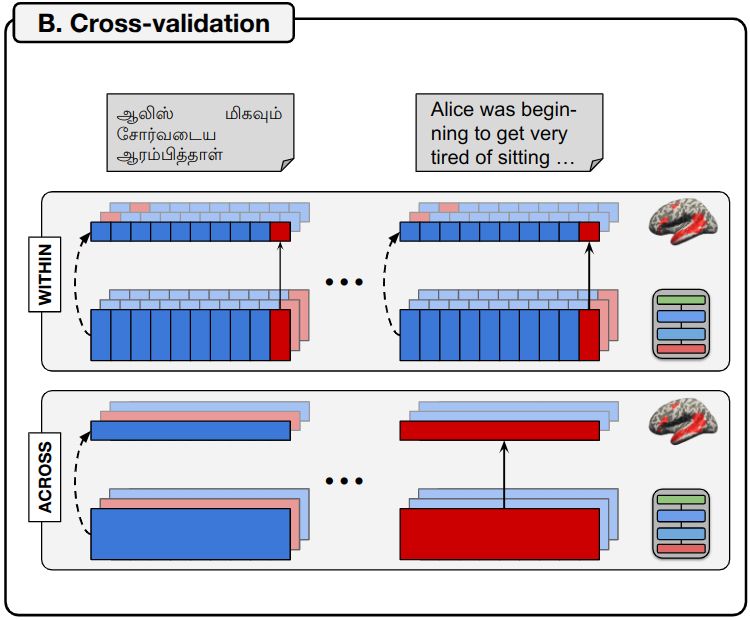
Critically, we fit two kinds of encoding models:
1️⃣ “within” encoding models, training and testing on data from a single language with cross-validation
2️⃣ “across” encoding models, training in N-1 languages and testing in the left-out language (5/)
1️⃣ “within” encoding models, training and testing on data from a single language with cross-validation
2️⃣ “across” encoding models, training in N-1 languages and testing in the left-out language (5/)
February 4, 2025 at 6:03 PM
Critically, we fit two kinds of encoding models:
1️⃣ “within” encoding models, training and testing on data from a single language with cross-validation
2️⃣ “across” encoding models, training in N-1 languages and testing in the left-out language (5/)
1️⃣ “within” encoding models, training and testing on data from a single language with cross-validation
2️⃣ “across” encoding models, training in N-1 languages and testing in the left-out language (5/)
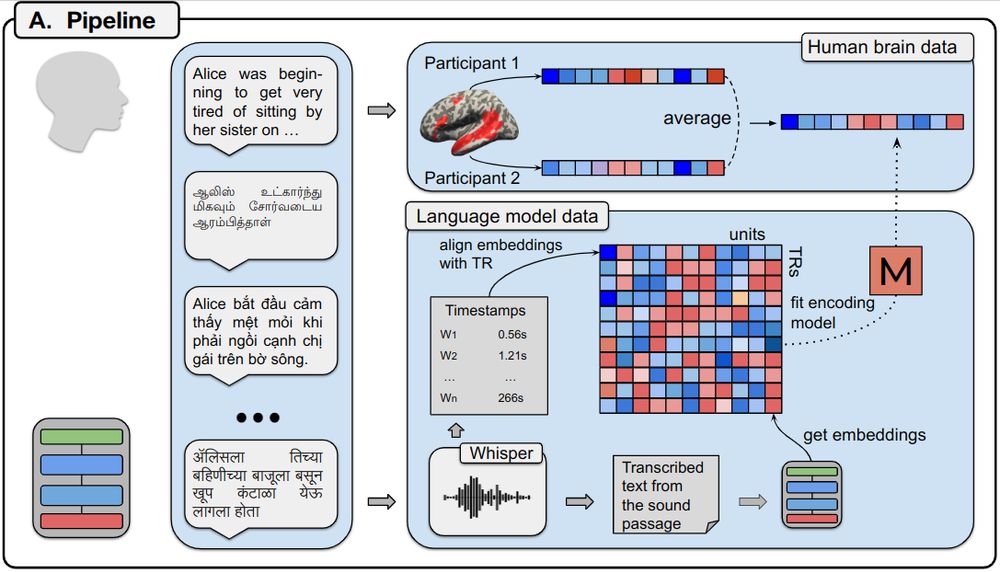
In Study I, we:
1️⃣ Present participants with auditory passages and record their brain responses in the language network
2️⃣ Extract contextualized word embeddings from multilingual LMs
3️⃣ Fit encoding models predicting brain activity from the embeddings (4/)
1️⃣ Present participants with auditory passages and record their brain responses in the language network
2️⃣ Extract contextualized word embeddings from multilingual LMs
3️⃣ Fit encoding models predicting brain activity from the embeddings (4/)
February 4, 2025 at 6:03 PM
In Study I, we:
1️⃣ Present participants with auditory passages and record their brain responses in the language network
2️⃣ Extract contextualized word embeddings from multilingual LMs
3️⃣ Fit encoding models predicting brain activity from the embeddings (4/)
1️⃣ Present participants with auditory passages and record their brain responses in the language network
2️⃣ Extract contextualized word embeddings from multilingual LMs
3️⃣ Fit encoding models predicting brain activity from the embeddings (4/)