



@amouyalsamuel.bsky.social
One intriguing follow-up: some component of the sentence understanding cognitive model fails on GP sentence. Is this component also present in LLMs? If not, then why so many LLMs are influenced by our manipulations in the same way humans are?

March 12, 2025 at 7:12 PM
One intriguing follow-up: some component of the sentence understanding cognitive model fails on GP sentence. Is this component also present in LLMs? If not, then why so many LLMs are influenced by our manipulations in the same way humans are?
There are many more cool insights you can find in our paper.
One takeaway from this paper for the psycholinguistics community: run your reading comprehension experiment on LLM first. You might get a general idea of the human results.
(Last image I swear)
One takeaway from this paper for the psycholinguistics community: run your reading comprehension experiment on LLM first. You might get a general idea of the human results.
(Last image I swear)

March 12, 2025 at 7:12 PM
There are many more cool insights you can find in our paper.
One takeaway from this paper for the psycholinguistics community: run your reading comprehension experiment on LLM first. You might get a general idea of the human results.
(Last image I swear)
One takeaway from this paper for the psycholinguistics community: run your reading comprehension experiment on LLM first. You might get a general idea of the human results.
(Last image I swear)
These experiments replicated the results from the sentence comprehension one: our manipulations had the same effect on the paraphrase or drawing correctness as they had on the sentence comprehension task.
In this image: While the teacher taught the puppies looked at the board.
In this image: While the teacher taught the puppies looked at the board.

March 12, 2025 at 7:12 PM
These experiments replicated the results from the sentence comprehension one: our manipulations had the same effect on the paraphrase or drawing correctness as they had on the sentence comprehension task.
In this image: While the teacher taught the puppies looked at the board.
In this image: While the teacher taught the puppies looked at the board.
We also ran two additional experiments with LLMs that are challenging to perform on humans.
1. We asked the LLM to paraphrase our sentence
2. We asked text-to-image models to draw the sentences
In this image: While the horse pulled the submarine moved silently.
1. We asked the LLM to paraphrase our sentence
2. We asked text-to-image models to draw the sentences
In this image: While the horse pulled the submarine moved silently.

March 12, 2025 at 7:12 PM
We also ran two additional experiments with LLMs that are challenging to perform on humans.
1. We asked the LLM to paraphrase our sentence
2. We asked text-to-image models to draw the sentences
In this image: While the horse pulled the submarine moved silently.
1. We asked the LLM to paraphrase our sentence
2. We asked text-to-image models to draw the sentences
In this image: While the horse pulled the submarine moved silently.
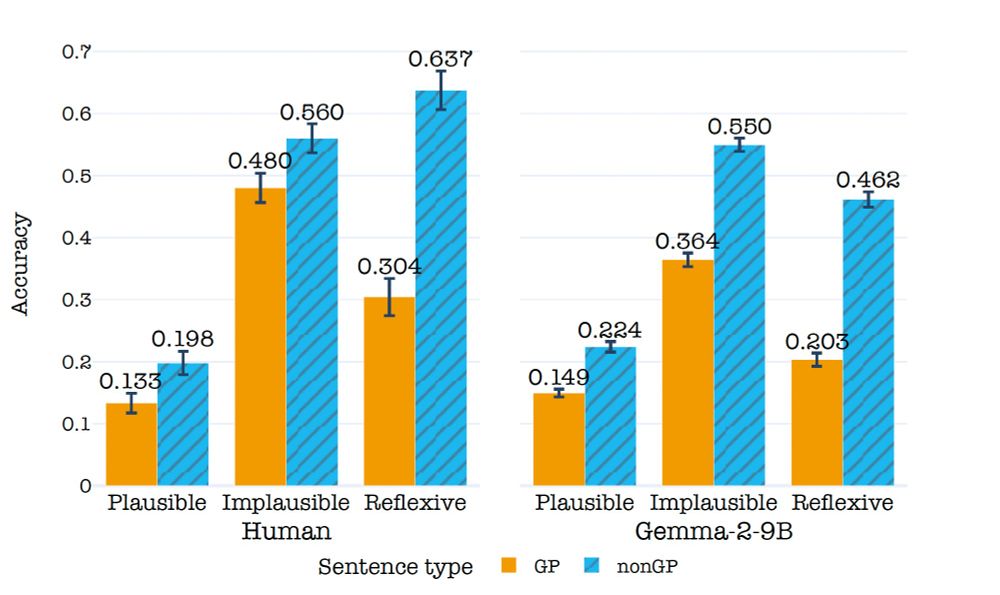
To answer our second question, we ran the same sentence comprehension experiment we ran on humans with over 60 LLMs.
We found that LLMs also struggle with GP sentences and that, interestingly, the manipulations we did to test our hypotheses impacted LLMs as they did with humans
We found that LLMs also struggle with GP sentences and that, interestingly, the manipulations we did to test our hypotheses impacted LLMs as they did with humans
March 12, 2025 at 7:12 PM
To answer our second question, we ran the same sentence comprehension experiment we ran on humans with over 60 LLMs.
We found that LLMs also struggle with GP sentences and that, interestingly, the manipulations we did to test our hypotheses impacted LLMs as they did with humans
We found that LLMs also struggle with GP sentences and that, interestingly, the manipulations we did to test our hypotheses impacted LLMs as they did with humans
In our latest paper with Aya Meltzer-Asscher and @jonathanberant.bsky.social, we try to answer both these questions.
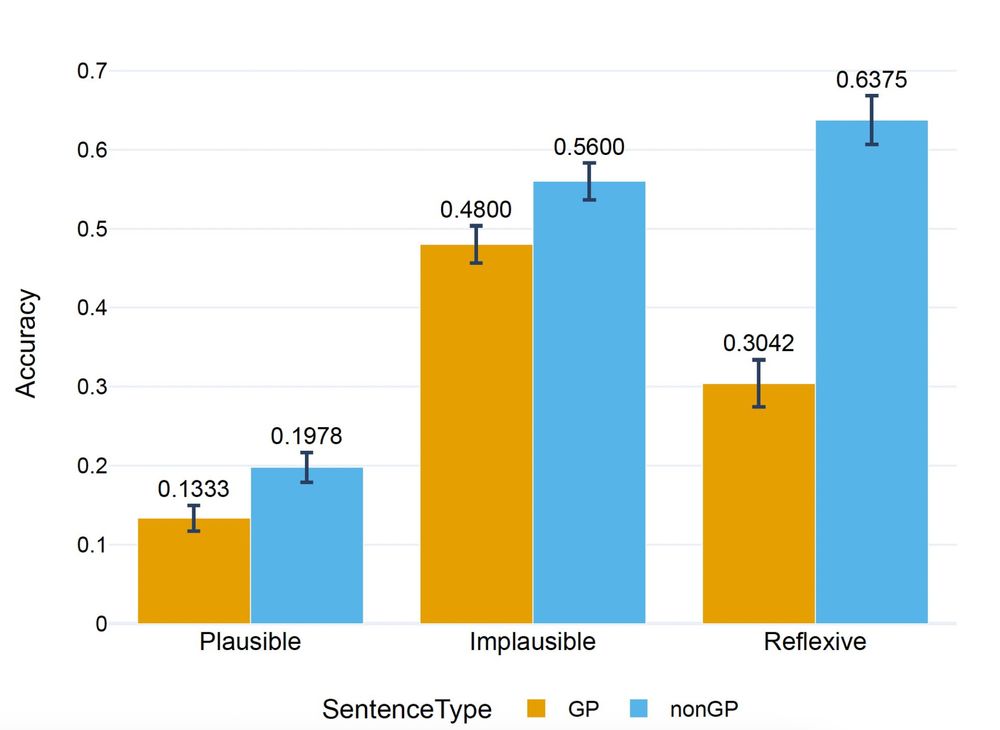
We devise hypotheses explaining why GP sentences are harder to process and test them. Human subjects answered a reading comprehension question about a sentence they read.
We devise hypotheses explaining why GP sentences are harder to process and test them. Human subjects answered a reading comprehension question about a sentence they read.
March 12, 2025 at 7:12 PM
In our latest paper with Aya Meltzer-Asscher and @jonathanberant.bsky.social, we try to answer both these questions.
We devise hypotheses explaining why GP sentences are harder to process and test them. Human subjects answered a reading comprehension question about a sentence they read.
We devise hypotheses explaining why GP sentences are harder to process and test them. Human subjects answered a reading comprehension question about a sentence they read.