




AMLab
@amlab.bsky.social
The official account of the Amsterdam Machine Learning Lab (AMLab) at UvA, co-directed by Max Welling and Jan-Willem van de Meent.
🐳 Controlled Generation with Equivariant Variational Flow Matching
By @eijkelboomfloor.bsky.social , @zmheiko.bsky.social ,
@sharvaree.bsky.social , @erikjbekkers.bsky.social ,
@wellingmax.bsky.social , @canaesseth.bsky.social *, @jwvdm.bsky.social *
📜 As above - paper TBA soon 😉
🧵8 / 8
By @eijkelboomfloor.bsky.social , @zmheiko.bsky.social ,
@sharvaree.bsky.social , @erikjbekkers.bsky.social ,
@wellingmax.bsky.social , @canaesseth.bsky.social *, @jwvdm.bsky.social *
📜 As above - paper TBA soon 😉
🧵8 / 8
May 6, 2025 at 3:03 PM
🐳 Controlled Generation with Equivariant Variational Flow Matching
By @eijkelboomfloor.bsky.social , @zmheiko.bsky.social ,
@sharvaree.bsky.social , @erikjbekkers.bsky.social ,
@wellingmax.bsky.social , @canaesseth.bsky.social *, @jwvdm.bsky.social *
📜 As above - paper TBA soon 😉
🧵8 / 8
By @eijkelboomfloor.bsky.social , @zmheiko.bsky.social ,
@sharvaree.bsky.social , @erikjbekkers.bsky.social ,
@wellingmax.bsky.social , @canaesseth.bsky.social *, @jwvdm.bsky.social *
📜 As above - paper TBA soon 😉
🧵8 / 8
🌊 Exponential Family Variational Flow Matching for Tabular Data Generation
By Andrés Guzmán-Cordero*, @eijkelboomfloor.bsky.social *,
@jwvdm.bsky.social
📜 This paper will be shared soon - keep your eyes open! 🤩
🧵7 / 8
By Andrés Guzmán-Cordero*, @eijkelboomfloor.bsky.social *,
@jwvdm.bsky.social
📜 This paper will be shared soon - keep your eyes open! 🤩
🧵7 / 8
May 6, 2025 at 3:03 PM
🌊 Exponential Family Variational Flow Matching for Tabular Data Generation
By Andrés Guzmán-Cordero*, @eijkelboomfloor.bsky.social *,
@jwvdm.bsky.social
📜 This paper will be shared soon - keep your eyes open! 🤩
🧵7 / 8
By Andrés Guzmán-Cordero*, @eijkelboomfloor.bsky.social *,
@jwvdm.bsky.social
📜 This paper will be shared soon - keep your eyes open! 🤩
🧵7 / 8
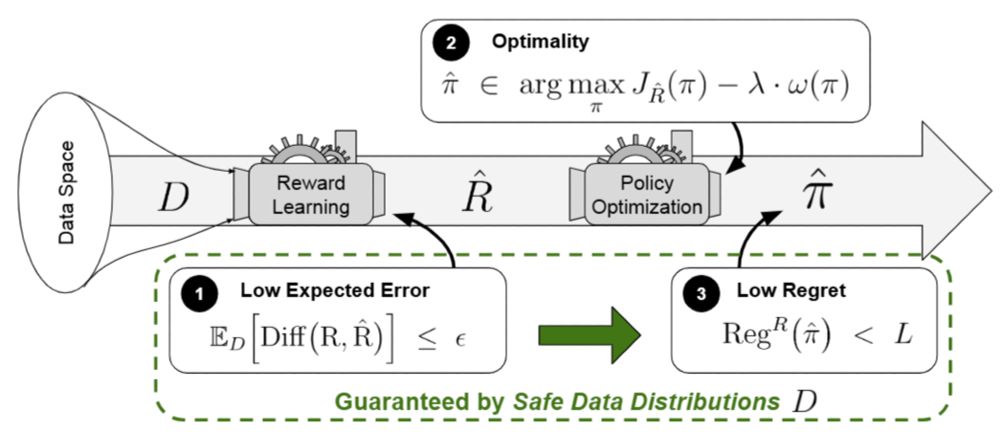
⚠️ The Perils of Optimizing Learned Reward Functions: Low Training Error Does Not Guarantee Low Regret
By Lukas Fluri*, @leon-lang.bsky.social *, Alessandro Abate, Patrick Forré, David Krueger, Joar Skalse
📜 arxiv.org/abs/2406.15753
🧵6 / 8
By Lukas Fluri*, @leon-lang.bsky.social *, Alessandro Abate, Patrick Forré, David Krueger, Joar Skalse
📜 arxiv.org/abs/2406.15753
🧵6 / 8
May 6, 2025 at 2:53 PM
⚠️ The Perils of Optimizing Learned Reward Functions: Low Training Error Does Not Guarantee Low Regret
By Lukas Fluri*, @leon-lang.bsky.social *, Alessandro Abate, Patrick Forré, David Krueger, Joar Skalse
📜 arxiv.org/abs/2406.15753
🧵6 / 8
By Lukas Fluri*, @leon-lang.bsky.social *, Alessandro Abate, Patrick Forré, David Krueger, Joar Skalse
📜 arxiv.org/abs/2406.15753
🧵6 / 8
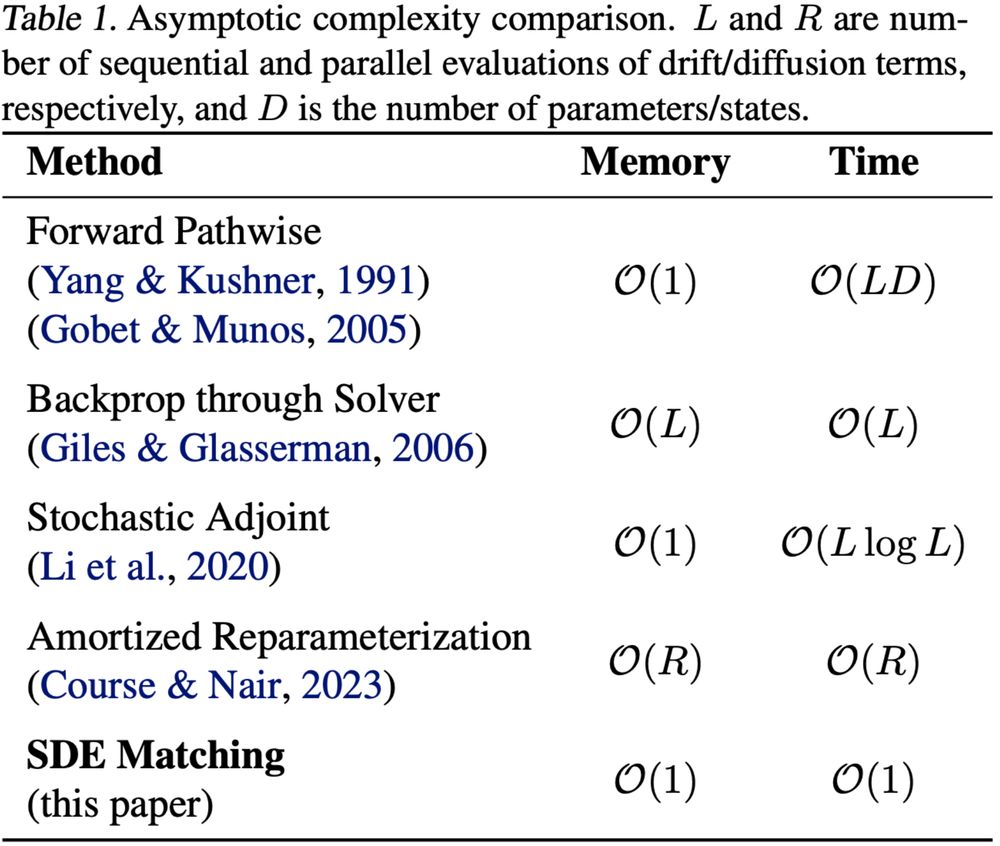
🔁 SDE Matching: Scalable and Simulation-Free Training of Latent Stochastic Differential Equations
By @gbarto.bsky.social , Dmitry Vetrov, @canaesseth.bsky.social
📜 arxiv.org/abs/2502.02472
🧵5 / 8
By @gbarto.bsky.social , Dmitry Vetrov, @canaesseth.bsky.social
📜 arxiv.org/abs/2502.02472
🧵5 / 8
May 6, 2025 at 2:53 PM
🔁 SDE Matching: Scalable and Simulation-Free Training of Latent Stochastic Differential Equations
By @gbarto.bsky.social , Dmitry Vetrov, @canaesseth.bsky.social
📜 arxiv.org/abs/2502.02472
🧵5 / 8
By @gbarto.bsky.social , Dmitry Vetrov, @canaesseth.bsky.social
📜 arxiv.org/abs/2502.02472
🧵5 / 8
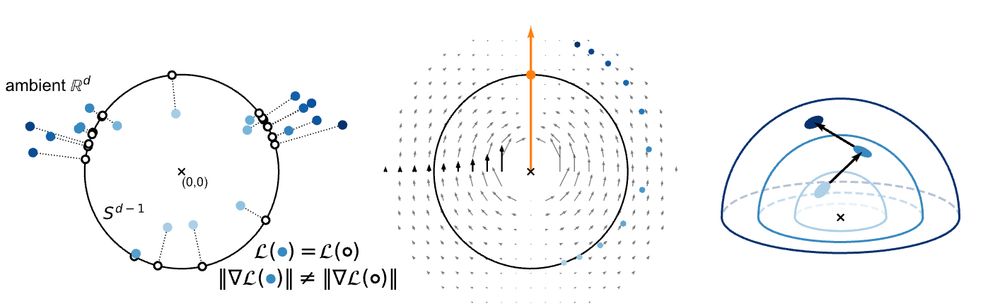
📐 On the Importance of Embedding Norms in Self-Supervised Learning
By Andrew Draganov, @sharvaree.bsky.social , Sebastian Damrich, Jan Niklas Böhm, Lucas Maes, Dmitry Kobak, @erikjbekkers.bsky.social
📜 arxiv.org/abs/2502.09252
🧵4 / 8
By Andrew Draganov, @sharvaree.bsky.social , Sebastian Damrich, Jan Niklas Böhm, Lucas Maes, Dmitry Kobak, @erikjbekkers.bsky.social
📜 arxiv.org/abs/2502.09252
🧵4 / 8
May 6, 2025 at 2:53 PM
📐 On the Importance of Embedding Norms in Self-Supervised Learning
By Andrew Draganov, @sharvaree.bsky.social , Sebastian Damrich, Jan Niklas Böhm, Lucas Maes, Dmitry Kobak, @erikjbekkers.bsky.social
📜 arxiv.org/abs/2502.09252
🧵4 / 8
By Andrew Draganov, @sharvaree.bsky.social , Sebastian Damrich, Jan Niklas Böhm, Lucas Maes, Dmitry Kobak, @erikjbekkers.bsky.social
📜 arxiv.org/abs/2502.09252
🧵4 / 8
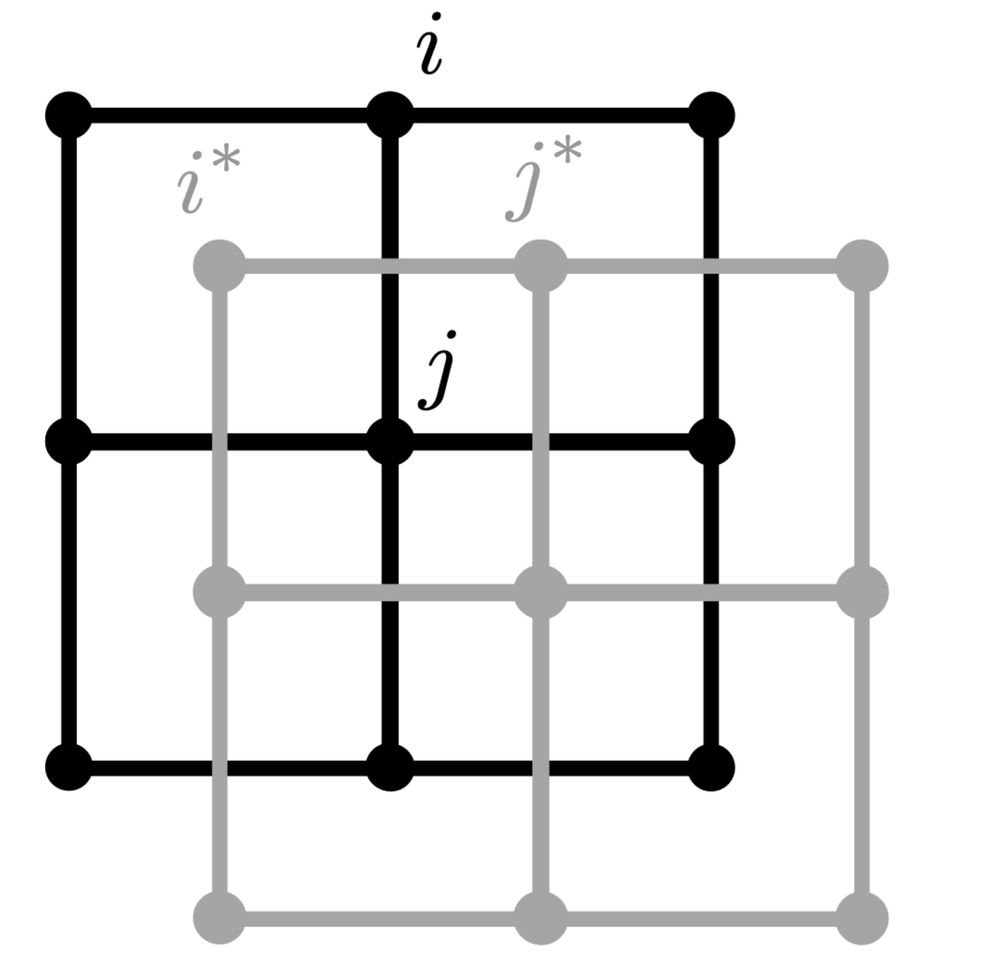
⚖️ A machine learning approach to duality in statistical physics
By Prateek Gupta, Andrea Ferrari, @nabiliqbal.bsky.social
📜 arxiv.org/abs/2411.04838
🧵3 / 8
By Prateek Gupta, Andrea Ferrari, @nabiliqbal.bsky.social
📜 arxiv.org/abs/2411.04838
🧵3 / 8
May 6, 2025 at 2:53 PM
⚖️ A machine learning approach to duality in statistical physics
By Prateek Gupta, Andrea Ferrari, @nabiliqbal.bsky.social
📜 arxiv.org/abs/2411.04838
🧵3 / 8
By Prateek Gupta, Andrea Ferrari, @nabiliqbal.bsky.social
📜 arxiv.org/abs/2411.04838
🧵3 / 8
🐸 Erwin: A Tree-based Hierarchical Transformer for Large-scale Physical Systems
By @maxxxzdn.bsky.social , @jwvdm.bsky.social , @wellingmax.bsky.social
📜 arxiv.org/abs/2502.17019
🧵2 / 8
By @maxxxzdn.bsky.social , @jwvdm.bsky.social , @wellingmax.bsky.social
📜 arxiv.org/abs/2502.17019
🧵2 / 8
May 6, 2025 at 2:53 PM
🐸 Erwin: A Tree-based Hierarchical Transformer for Large-scale Physical Systems
By @maxxxzdn.bsky.social , @jwvdm.bsky.social , @wellingmax.bsky.social
📜 arxiv.org/abs/2502.17019
🧵2 / 8
By @maxxxzdn.bsky.social , @jwvdm.bsky.social , @wellingmax.bsky.social
📜 arxiv.org/abs/2502.17019
🧵2 / 8
Reposted by AMLab

Test of Time Winner
Adam: A Method for Stochastic Optimization
Diederik P. Kingma, Jimmy Ba
Adam revolutionized neural network training, enabling significantly faster convergence and more stable training across a wide variety of architectures and tasks.
Adam: A Method for Stochastic Optimization
Diederik P. Kingma, Jimmy Ba
Adam revolutionized neural network training, enabling significantly faster convergence and more stable training across a wide variety of architectures and tasks.
April 15, 2025 at 3:39 AM
Test of Time Winner
Adam: A Method for Stochastic Optimization
Diederik P. Kingma, Jimmy Ba
Adam revolutionized neural network training, enabling significantly faster convergence and more stable training across a wide variety of architectures and tasks.
Adam: A Method for Stochastic Optimization
Diederik P. Kingma, Jimmy Ba
Adam revolutionized neural network training, enabling significantly faster convergence and more stable training across a wide variety of architectures and tasks.
looks can be deceiving! ;)
December 16, 2024 at 9:32 AM
looks can be deceiving! ;)
Professor Imbens also had a mentoring session with our PhD students actively working on causality, discussing their ideas and the potential impact of their applications! 👨🔬👩🔬
@matyasch.bsky.social @roelhulsman.bsky.social @rmassidda.it @danruxu.bsky.social 🔥
@matyasch.bsky.social @roelhulsman.bsky.social @rmassidda.it @danruxu.bsky.social 🔥

December 13, 2024 at 8:47 AM
Professor Imbens also had a mentoring session with our PhD students actively working on causality, discussing their ideas and the potential impact of their applications! 👨🔬👩🔬
@matyasch.bsky.social @roelhulsman.bsky.social @rmassidda.it @danruxu.bsky.social 🔥
@matyasch.bsky.social @roelhulsman.bsky.social @rmassidda.it @danruxu.bsky.social 🔥