


Amit Goldenberg
@amit-goldenberg.bsky.social
I study emotions, collectives, technology and their interaction. Harvard Business School | Harvard Psych (affiliated) | D3
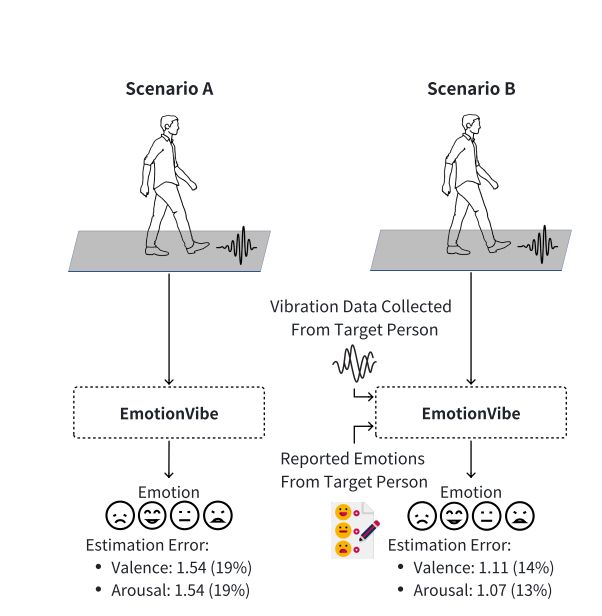
The mean absolute error of the model after training was 1.11, which means the model was off by about one point on average. This is not bad, or even surprisingly good, especially given that valence results were restricted to a pretty narrow range, but can we predict valence? Not sure.
April 1, 2025 at 2:41 PM
The mean absolute error of the model after training was 1.11, which means the model was off by about one point on average. This is not bad, or even surprisingly good, especially given that valence results were restricted to a pretty narrow range, but can we predict valence? Not sure.
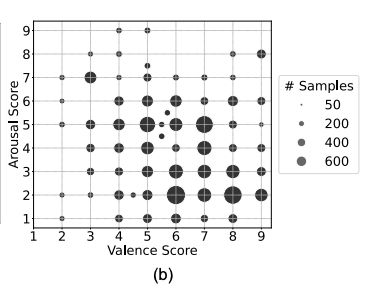
As for the results – it's unclear whether the music impacted emotions in the expected direction (not reported in the paper). One thing is clear: the valence scale – which ranged from very negative -1 to very positive 9 – had valence results mostly between 3 and 9, so no strong negative valence.
April 1, 2025 at 2:41 PM
As for the results – it's unclear whether the music impacted emotions in the expected direction (not reported in the paper). One thing is clear: the valence scale – which ranged from very negative -1 to very positive 9 – had valence results mostly between 3 and 9, so no strong negative valence.
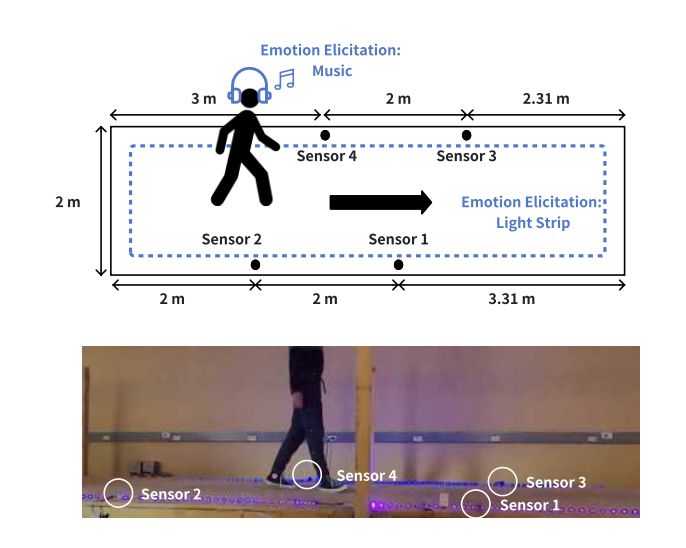
The paper asked 20 people to walk while listening to music that was previously validated to elicit different emotions. For example, to elicit high-arousal negative emotions (akin to anger or fear), participants heard music from Dracula or high-wire stunts and lighting was red/yellow shining.
April 1, 2025 at 2:41 PM
The paper asked 20 people to walk while listening to music that was previously validated to elicit different emotions. For example, to elicit high-arousal negative emotions (akin to anger or fear), participants heard music from Dracula or high-wire stunts and lighting was red/yellow shining.
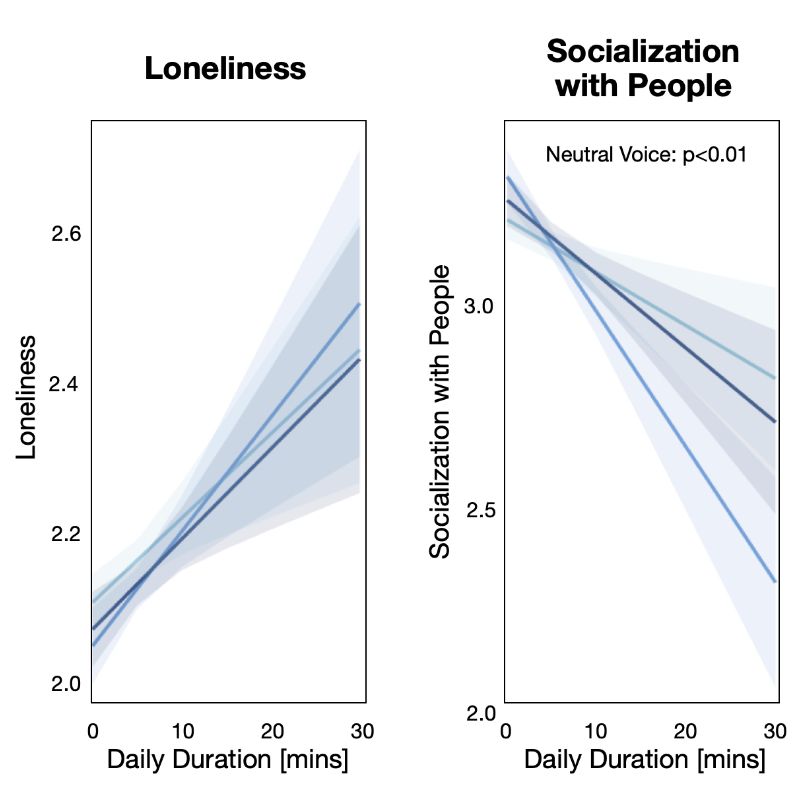
What was more interesting to me is the correlation between use time and loneliness. Higher use time was positively associated with loneliness. This is very likely driven by the fact that lonelier people are just more likely to spend more time with the chat.
March 24, 2025 at 1:29 AM
What was more interesting to me is the correlation between use time and loneliness. Higher use time was positively associated with loneliness. This is very likely driven by the fact that lonelier people are just more likely to spend more time with the chat.
My lab and I are looking to take an applied class on Graph Machine Learning, similar to this Stanford class: web.stanford.edu/class/cs224w/.
Any suggestions?
Any suggestions?
January 9, 2025 at 4:00 AM
My lab and I are looking to take an applied class on Graph Machine Learning, similar to this Stanford class: web.stanford.edu/class/cs224w/.
Any suggestions?
Any suggestions?
When asked to describe street food in the US and why it's so bad compared to other countries, I like to point out that I live in a place where Goldfish crackers are considered a legitimate salad topping.

December 12, 2024 at 7:50 PM
When asked to describe street food in the US and why it's so bad compared to other countries, I like to point out that I live in a place where Goldfish crackers are considered a legitimate salad topping.
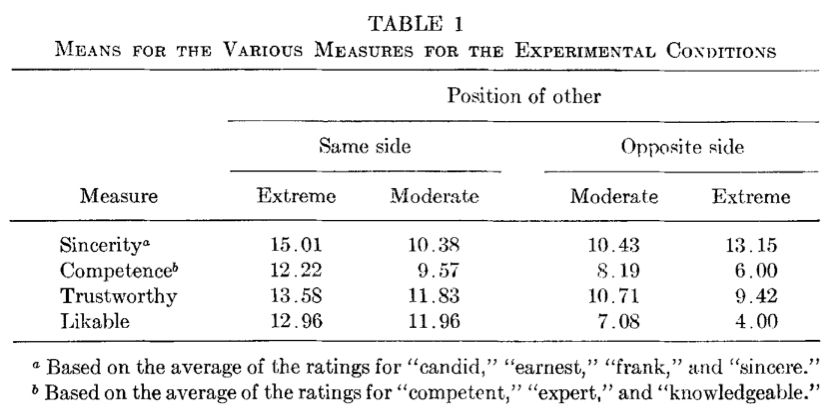
When we present our work on attraction to extremity, people often ask whether this is a new phenomenon. We found this great paper from 1968 showing that people assign more sincerity, competence, trustworthiness, and likability to extremes on their own side.
www.sciencedirect.com/science/arti...
www.sciencedirect.com/science/arti...
December 5, 2024 at 3:37 PM
When we present our work on attraction to extremity, people often ask whether this is a new phenomenon. We found this great paper from 1968 showing that people assign more sincerity, competence, trustworthiness, and likability to extremes on their own side.
www.sciencedirect.com/science/arti...
www.sciencedirect.com/science/arti...
Here's the kicker: GPT's reappraisal quality was higher when it was semantically closer to the vignette. For humans it was the opposite—they were rated higher when they were able to generalize away from the vignette!! This reveals an important difference between GPT and humans.⬇️

April 21, 2024 at 4:03 PM
Here's the kicker: GPT's reappraisal quality was higher when it was semantically closer to the vignette. For humans it was the opposite—they were rated higher when they were able to generalize away from the vignette!! This reveals an important difference between GPT and humans.⬇️
Using sentence embedding, we compared the distance between the reappraisals and vignettes. Human reappraisals (green) tended to be much more similar to the vignettes than those of GPT-4 (orange), which tended to be more general. ⬇️

April 21, 2024 at 4:03 PM
Using sentence embedding, we compared the distance between the reappraisals and vignettes. Human reappraisals (green) tended to be much more similar to the vignettes than those of GPT-4 (orange), which tended to be more general. ⬇️
We were wondering whether the difference was driven by effort or skill, so we incentivized humans to write better reappraisals (up to 150% of their base pay if ranked in the top 25% of reappraisers). This led to an increase in time spent (15-22 seconds) but no change in quality. ⬇️

April 21, 2024 at 4:03 PM
We were wondering whether the difference was driven by effort or skill, so we incentivized humans to write better reappraisals (up to 150% of their base pay if ranked in the top 25% of reappraisers). This led to an increase in time spent (15-22 seconds) but no change in quality. ⬇️
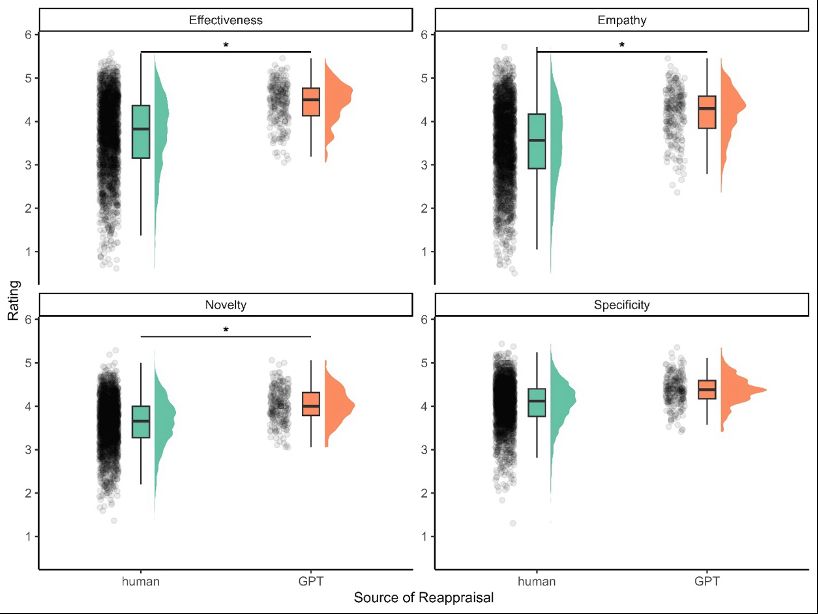
Human raters evaluated reappraisals on four dimensions: effectiveness, empathy, novelty, and specificity. GPT-4 outperformed humans on all dimensions except for specificity ("This rethinking is specific to the following scenario"). GPT-4 ranked in the 85th percentile in quality. ⬇️
April 21, 2024 at 4:02 PM
Human raters evaluated reappraisals on four dimensions: effectiveness, empathy, novelty, and specificity. GPT-4 outperformed humans on all dimensions except for specificity ("This rethinking is specific to the following scenario"). GPT-4 ranked in the 85th percentile in quality. ⬇️
I am pausing my war Twitter hiatus to remind affective scientists that our the deadline for submitting abstracts to the #emotion preconference at @spspnews.bsky.social is tomorrow! We have an amazing day planned and I am looking forward to seeing you there.

October 24, 2023 at 1:29 PM
I am pausing my war Twitter hiatus to remind affective scientists that our the deadline for submitting abstracts to the #emotion preconference at @spspnews.bsky.social is tomorrow! We have an amazing day planned and I am looking forward to seeing you there.
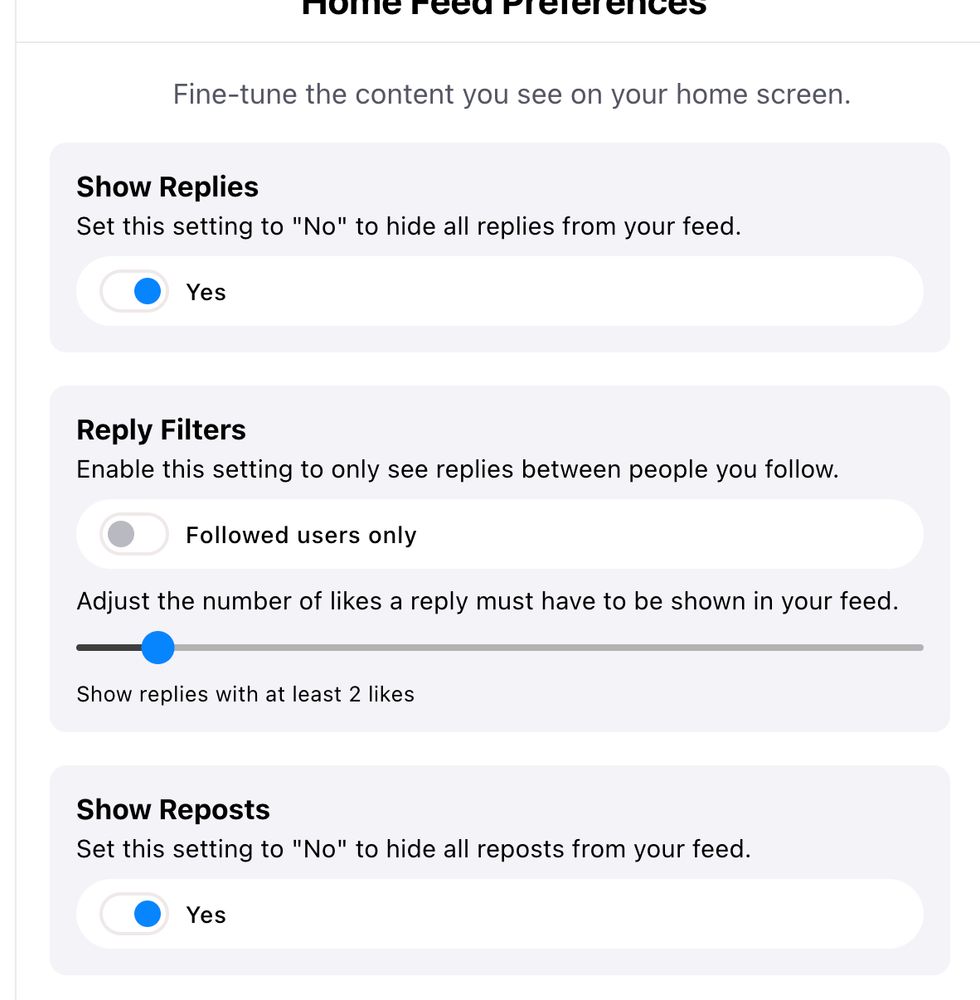
Blue Sky is allowing users to choose whether they want to see reposts. This is a very interesting move. When it comes to emotions, people are more likely to share negative emotions than to produce them, so reducing reposts increase exposure to positive emotions.
September 28, 2023 at 9:57 PM
Blue Sky is allowing users to choose whether they want to see reposts. This is a very interesting move. When it comes to emotions, people are more likely to share negative emotions than to produce them, so reducing reposts increase exposure to positive emotions.