




Alberto Parola
@alpar.bsky.social
Assistant Professor at Centre for Language Technology, Copenhagen Uni. @MSCActions Fellow | Pragmatics, social cognition & mental disorders, NLP, speech analysis, multimodal communication, Bayesian stats |
8/8 🛠️ How can we improve generalization?
•Larger, open datasets capturing linguistic, clinical, and demogr. variability in SCZ to test generalization and modern ML architectures, e.g., LLMs, multimodal models.
•Focusing on fine-grained clinically relevant features to enhance clinical applicability.
•Larger, open datasets capturing linguistic, clinical, and demogr. variability in SCZ to test generalization and modern ML architectures, e.g., LLMs, multimodal models.
•Focusing on fine-grained clinically relevant features to enhance clinical applicability.
December 3, 2024 at 4:21 PM
8/8 🛠️ How can we improve generalization?
•Larger, open datasets capturing linguistic, clinical, and demogr. variability in SCZ to test generalization and modern ML architectures, e.g., LLMs, multimodal models.
•Focusing on fine-grained clinically relevant features to enhance clinical applicability.
•Larger, open datasets capturing linguistic, clinical, and demogr. variability in SCZ to test generalization and modern ML architectures, e.g., LLMs, multimodal models.
•Focusing on fine-grained clinically relevant features to enhance clinical applicability.
7/8 🌍 Why does generalization fail?
• Linguistic differences affect how SCZ symptoms relate to acoustic features
• Clinical heterogeneity limits robustness of ML models trained on small, homogenous samples
• Models biased toward general features, not capturing diagnosis- or symptom-specific markers
• Linguistic differences affect how SCZ symptoms relate to acoustic features
• Clinical heterogeneity limits robustness of ML models trained on small, homogenous samples
• Models biased toward general features, not capturing diagnosis- or symptom-specific markers
December 3, 2024 at 4:17 PM
7/8 🌍 Why does generalization fail?
• Linguistic differences affect how SCZ symptoms relate to acoustic features
• Clinical heterogeneity limits robustness of ML models trained on small, homogenous samples
• Models biased toward general features, not capturing diagnosis- or symptom-specific markers
• Linguistic differences affect how SCZ symptoms relate to acoustic features
• Clinical heterogeneity limits robustness of ML models trained on small, homogenous samples
• Models biased toward general features, not capturing diagnosis- or symptom-specific markers
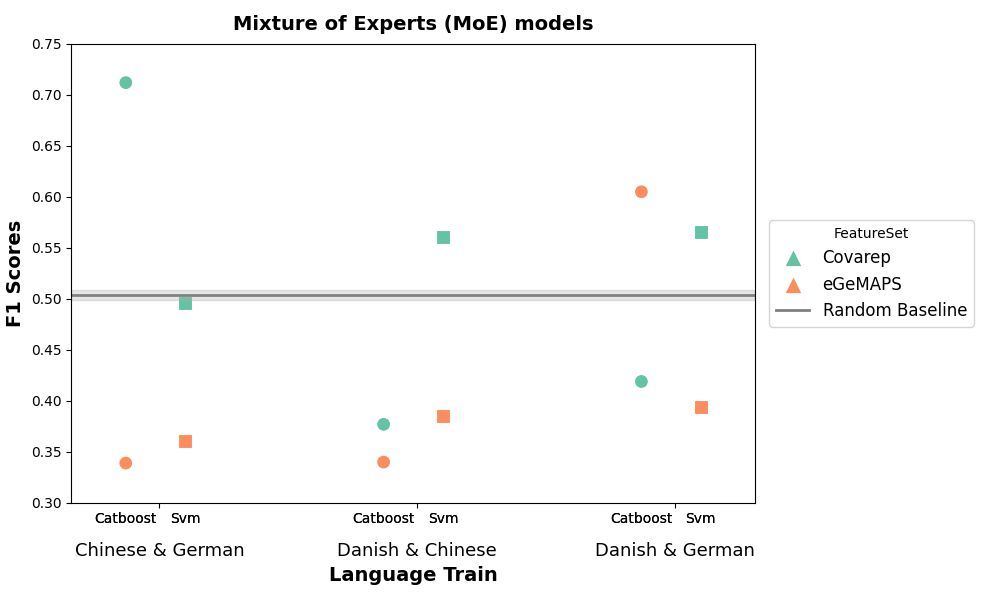
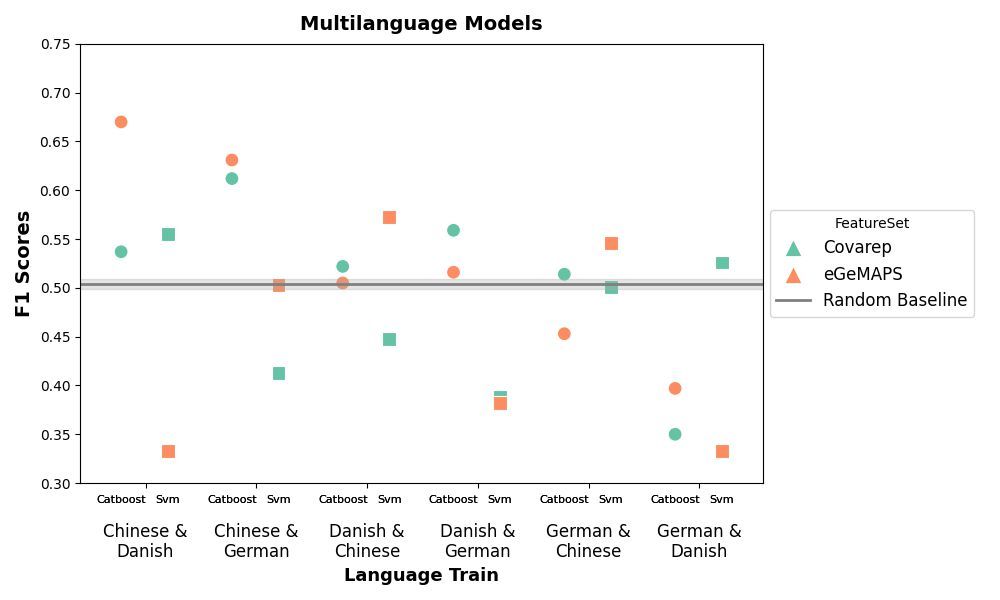
6/8 📢 Key Finding #3:
We tested two alternative approach:
1️) Mixture of Experts models (combining predictions from models trained on different languages, Plot 3).
2) Multi-language training set (combin. training data from multiple languages, Plot 4).
❌ Results: Still near chance level (F1 ~ 0.50).
We tested two alternative approach:
1️) Mixture of Experts models (combining predictions from models trained on different languages, Plot 3).
2) Multi-language training set (combin. training data from multiple languages, Plot 4).
❌ Results: Still near chance level (F1 ~ 0.50).
December 3, 2024 at 4:10 PM
6/8 📢 Key Finding #3:
We tested two alternative approach:
1️) Mixture of Experts models (combining predictions from models trained on different languages, Plot 3).
2) Multi-language training set (combin. training data from multiple languages, Plot 4).
❌ Results: Still near chance level (F1 ~ 0.50).
We tested two alternative approach:
1️) Mixture of Experts models (combining predictions from models trained on different languages, Plot 3).
2) Multi-language training set (combin. training data from multiple languages, Plot 4).
❌ Results: Still near chance level (F1 ~ 0.50).
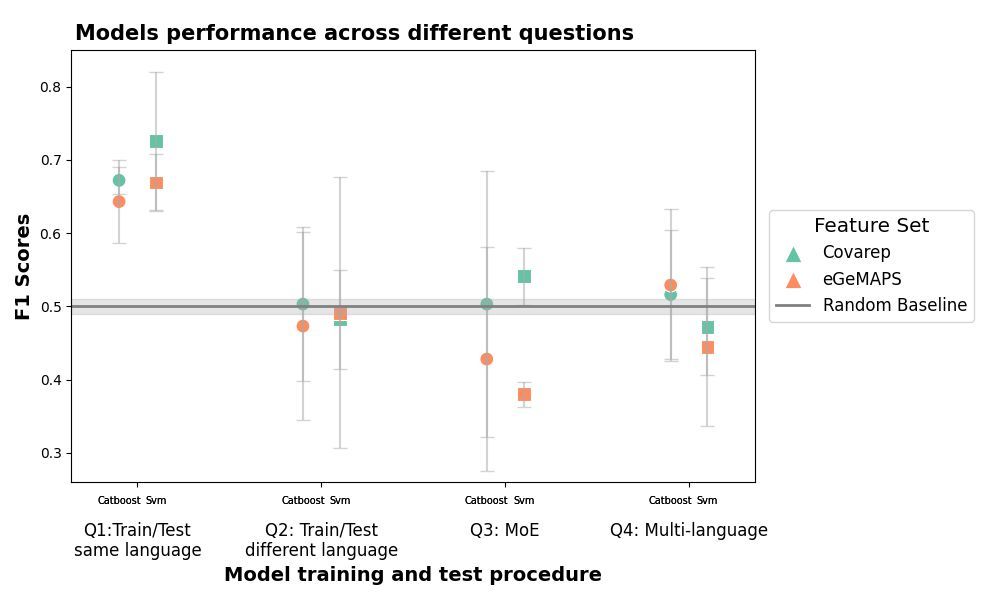
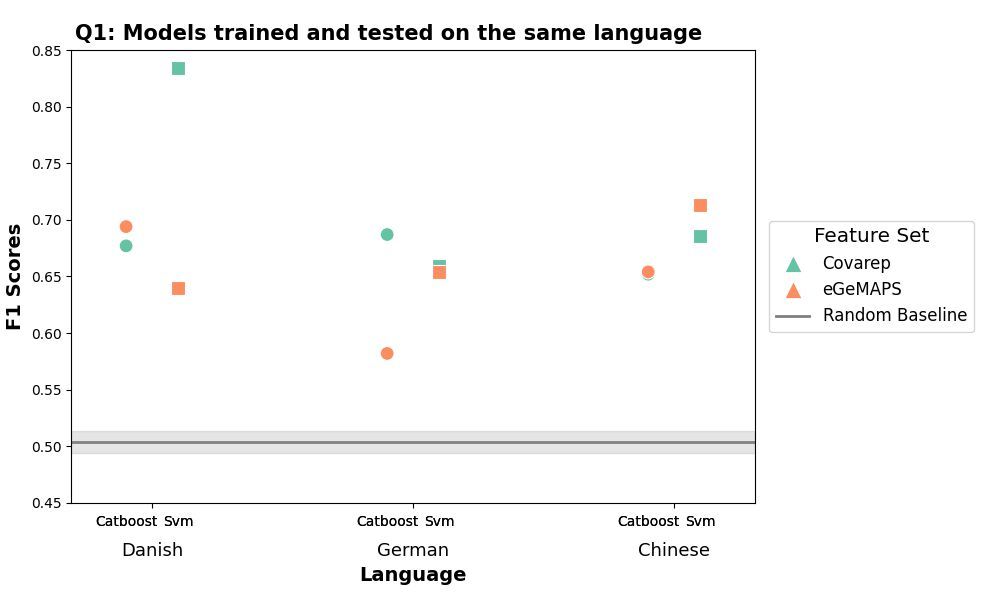
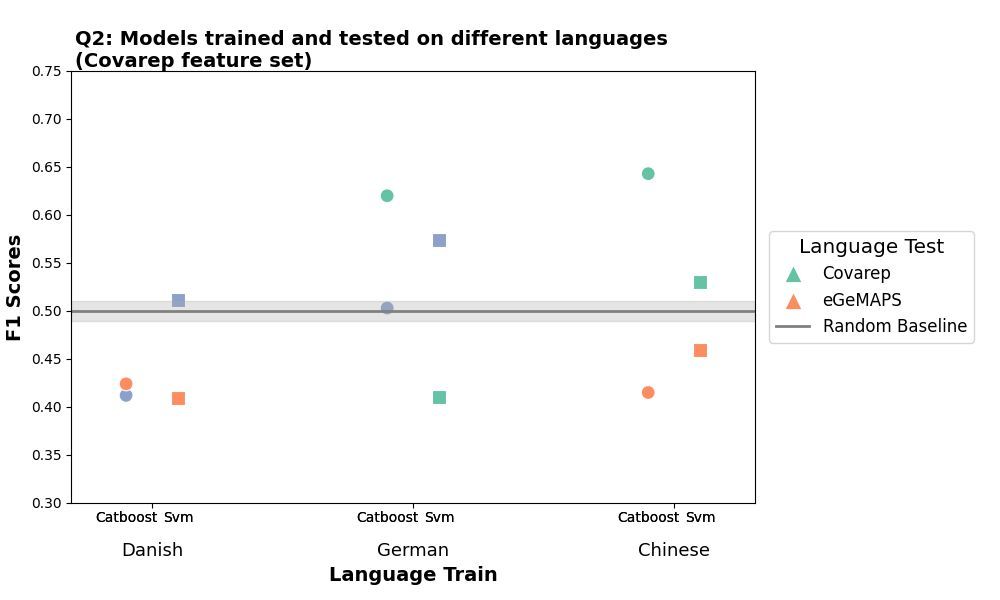
5/8 🚨 Key Finding
✔️#1: ML models perform when trained/tested on the same language (F1 ~ 0.75) (Plot1)
❌#2: But when trained/tested on different languages (e.g., Danish → Chinese), performance drops significantly (F1 ~ 0.50) (Plot 2).
Cross-linguistic generalizability remains a key challenge!
✔️#1: ML models perform when trained/tested on the same language (F1 ~ 0.75) (Plot1)
❌#2: But when trained/tested on different languages (e.g., Danish → Chinese), performance drops significantly (F1 ~ 0.50) (Plot 2).
Cross-linguistic generalizability remains a key challenge!
December 3, 2024 at 4:06 PM
5/8 🚨 Key Finding
✔️#1: ML models perform when trained/tested on the same language (F1 ~ 0.75) (Plot1)
❌#2: But when trained/tested on different languages (e.g., Danish → Chinese), performance drops significantly (F1 ~ 0.50) (Plot 2).
Cross-linguistic generalizability remains a key challenge!
✔️#1: ML models perform when trained/tested on the same language (F1 ~ 0.75) (Plot1)
❌#2: But when trained/tested on different languages (e.g., Danish → Chinese), performance drops significantly (F1 ~ 0.50) (Plot 2).
Cross-linguistic generalizability remains a key challenge!
4/8💡What’s the goal?
In this study we build a large cross-linguistic speech corpus (Danish, German, Chinese) of patients with schizophrenia and controls to systematically test whether voice-based ML models predicting schizophrenia generalize across different languages, samples and context: 🧵
In this study we build a large cross-linguistic speech corpus (Danish, German, Chinese) of patients with schizophrenia and controls to systematically test whether voice-based ML models predicting schizophrenia generalize across different languages, samples and context: 🧵
December 3, 2024 at 3:59 PM
4/8💡What’s the goal?
In this study we build a large cross-linguistic speech corpus (Danish, German, Chinese) of patients with schizophrenia and controls to systematically test whether voice-based ML models predicting schizophrenia generalize across different languages, samples and context: 🧵
In this study we build a large cross-linguistic speech corpus (Danish, German, Chinese) of patients with schizophrenia and controls to systematically test whether voice-based ML models predicting schizophrenia generalize across different languages, samples and context: 🧵
3/8 In prior meta-analysis and experim. work (below), we showed that speech marker generalizability might be challenging. The assumption that SCZ speech markers manifest uniformly across heterogeneous samples and contexts must be systematically tested: doi.org/10.1093/schb... doi.org/10.1016/j.sc...
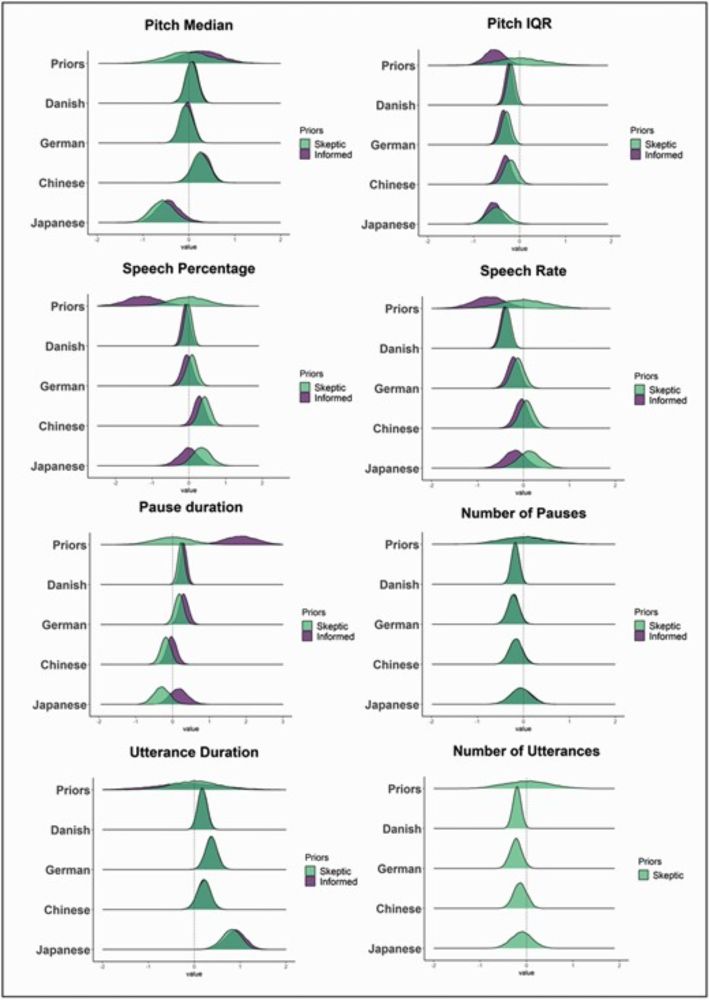
Voice Patterns as Markers of Schizophrenia: Building a Cumulative Generalizable Approach Via a Cross-Linguistic and Meta-analysis Based Investigation
AbstractBackground and Hypothesis. Voice atypicalities are potential markers of clinical features of schizophrenia (eg, negative symptoms). A recent meta-a
doi.org
December 3, 2024 at 3:58 PM
3/8 In prior meta-analysis and experim. work (below), we showed that speech marker generalizability might be challenging. The assumption that SCZ speech markers manifest uniformly across heterogeneous samples and contexts must be systematically tested: doi.org/10.1093/schb... doi.org/10.1016/j.sc...
2/8💡Key question ❓
But how well do voice-based machine-learning models generalize across languages and cultural contexts? How well do they generalize across samples with heterogenous clinical features? Are they robust enough to biases for clinical applicability?
But how well do voice-based machine-learning models generalize across languages and cultural contexts? How well do they generalize across samples with heterogenous clinical features? Are they robust enough to biases for clinical applicability?
December 3, 2024 at 3:45 PM
2/8💡Key question ❓
But how well do voice-based machine-learning models generalize across languages and cultural contexts? How well do they generalize across samples with heterogenous clinical features? Are they robust enough to biases for clinical applicability?
But how well do voice-based machine-learning models generalize across languages and cultural contexts? How well do they generalize across samples with heterogenous clinical features? Are they robust enough to biases for clinical applicability?
1/8 Schizophrenia and machine-learning-based speech markers
🎙️ Schizophrenia is associated with atypical voice patterns, making voice a promising candidate biomarker. Voice-based ML models can indeed predict diagnosis, symptoms and track socio-cognitive and motor features of SCZ with high accuracy.
🎙️ Schizophrenia is associated with atypical voice patterns, making voice a promising candidate biomarker. Voice-based ML models can indeed predict diagnosis, symptoms and track socio-cognitive and motor features of SCZ with high accuracy.
December 3, 2024 at 3:44 PM
1/8 Schizophrenia and machine-learning-based speech markers
🎙️ Schizophrenia is associated with atypical voice patterns, making voice a promising candidate biomarker. Voice-based ML models can indeed predict diagnosis, symptoms and track socio-cognitive and motor features of SCZ with high accuracy.
🎙️ Schizophrenia is associated with atypical voice patterns, making voice a promising candidate biomarker. Voice-based ML models can indeed predict diagnosis, symptoms and track socio-cognitive and motor features of SCZ with high accuracy.