




Alix Chagué 🌈
@alix-tz.bsky.social
PhD candidate at @Inria and @UMontreal working on automatic transcription of manuscripts (HTR). Posts about DH stuff and #HTR_United. More on my research blog: alix-tz.github.io/phd
Already on my way back, but these past few days I was in Princeton at the IAS to talk about HTR and its future with a whole lot of interesting people I was happy to meet or see again!
The IAS campus is quite a unique place, I'm very happy I was given the opportunity to travel there! 🦌🌳
The IAS campus is quite a unique place, I'm very happy I was given the opportunity to travel there! 🦌🌳

June 14, 2025 at 2:36 PM
Already on my way back, but these past few days I was in Princeton at the IAS to talk about HTR and its future with a whole lot of interesting people I was happy to meet or see again!
The IAS campus is quite a unique place, I'm very happy I was given the opportunity to travel there! 🦌🌳
The IAS campus is quite a unique place, I'm very happy I was given the opportunity to travel there! 🦌🌳
If you are attending #CHR2023 and want to spread the good words about HTR-United (which we don't present at CHR), Thibault and I have lots of stickers in our pockets! Feel free to come talk to us to get some!

December 6, 2023 at 11:56 AM
If you are attending #CHR2023 and want to spread the good words about HTR-United (which we don't present at CHR), Thibault and I have lots of stickers in our pockets! Feel free to come talk to us to get some!
Very very honored and delighted to have been awarded the Prize for Open Science and Research Data (Prix Science Ouverte des données de la recherche) with @ponteineptique.bsky.social for our project #HTR_United! It is such an honor!


November 29, 2023 at 1:14 PM
Very very honored and delighted to have been awarded the Prize for Open Science and Research Data (Prix Science Ouverte des données de la recherche) with @ponteineptique.bsky.social for our project #HTR_United! It is such an honor!
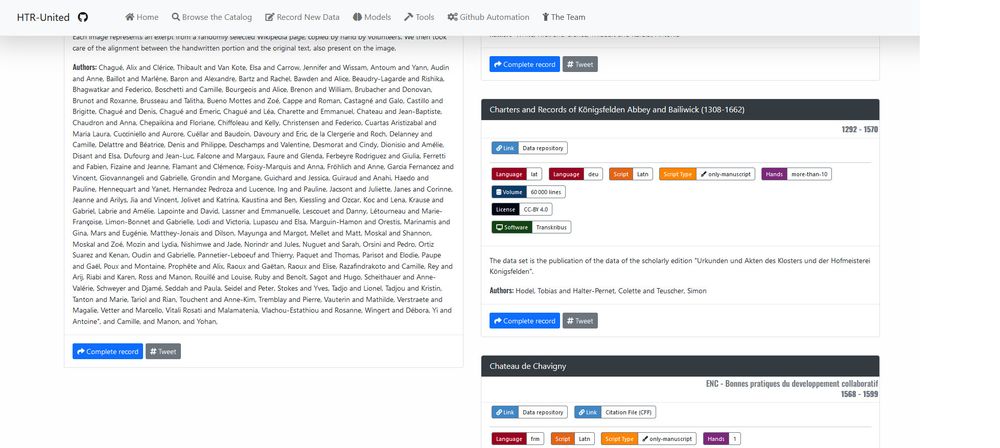
Each catalog entry appears as a card displaying all the information needed to get an overview of the dataset. Each card is given a URI, so you can permanently point to its description, and a Bibtex citation file is generated thanks to the provided metadata, inviting reusers to cite the data!

October 30, 2023 at 2:11 PM
Each catalog entry appears as a card displaying all the information needed to get an overview of the dataset. Each card is given a URI, so you can permanently point to its description, and a Bibtex citation file is generated thanks to the provided metadata, inviting reusers to cite the data!
... metadata generation (for volumes such as lines, characters, etc), and character set documentation and homogenization. It's possible to use them via Github actions so that they are automatically applied to your dataset when you update it (more: htr-united.github.io/actions.html)


October 30, 2023 at 1:54 PM
... metadata generation (for volumes such as lines, characters, etc), and character set documentation and homogenization. It's possible to use them via Github actions so that they are automatically applied to your dataset when you update it (more: htr-united.github.io/actions.html)
... and tools for quality control! This is a big aspect in the ecosystem revolving around HTR-United. Actually, you can find more information about it on our website (htr-united.github.io/tools.html). Tools are designed for: XML file validation, YAML file and catalog validation, ...


October 30, 2023 at 1:43 PM
... and tools for quality control! This is a big aspect in the ecosystem revolving around HTR-United. Actually, you can find more information about it on our website (htr-united.github.io/tools.html). Tools are designed for: XML file validation, YAML file and catalog validation, ...
We want a more stable and structured way to describe ground truth datasets. The goal is to make the descriptions more reliable so that users can faster identify the datasets best suited for their projects. In our opinion, it increases the chances of a dataset to be reused: it's a win-win situation!

October 30, 2023 at 12:09 PM
We want a more stable and structured way to describe ground truth datasets. The goal is to make the descriptions more reliable so that users can faster identify the datasets best suited for their projects. In our opinion, it increases the chances of a dataset to be reused: it's a win-win situation!
HTR-United actually relies on a single structured (YAML) text file gathering all the dataset descriptions. These descriptions are provided by the creators of the datasets, who take the time to write the description and submit it to us (more about that in a few skeets).

October 30, 2023 at 12:00 PM
HTR-United actually relies on a single structured (YAML) text file gathering all the dataset descriptions. These descriptions are provided by the creators of the datasets, who take the time to write the description and submit it to us (more about that in a few skeets).
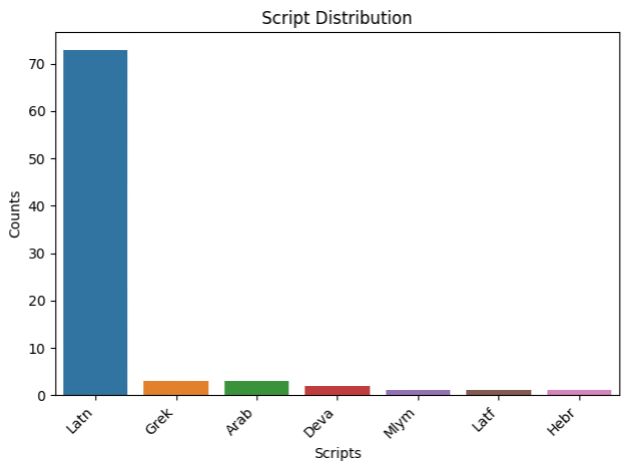
That's when HTR-United comes in! It is a catalog of descriptions redirecting to publicly available datasets of ground truth of different sizes, languages, writing systems, periods, etc.
We are based in France and work on French or Latin docs, it's visible in the current state of the catalog... 🤷
We are based in France and work on French or Latin docs, it's visible in the current state of the catalog... 🤷



October 30, 2023 at 11:50 AM
That's when HTR-United comes in! It is a catalog of descriptions redirecting to publicly available datasets of ground truth of different sizes, languages, writing systems, periods, etc.
We are based in France and work on French or Latin docs, it's visible in the current state of the catalog... 🤷
We are based in France and work on French or Latin docs, it's visible in the current state of the catalog... 🤷
Ground truth for text recognition model takes the form of matching pairs of images and transcription. As in the examples bellow, an image is paired with the expected transcription (cf. ALT text). It can take hundreds or thousands of such pairs to train a transcription model.

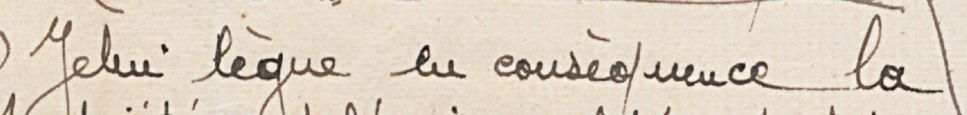
October 30, 2023 at 11:14 AM
Ground truth for text recognition model takes the form of matching pairs of images and transcription. As in the examples bellow, an image is paired with the expected transcription (cf. ALT text). It can take hundreds or thousands of such pairs to train a transcription model.