



AlgoPerf
@algoperf.bsky.social
AlgoPerf benchmark for faster neural network training via better training algorithms
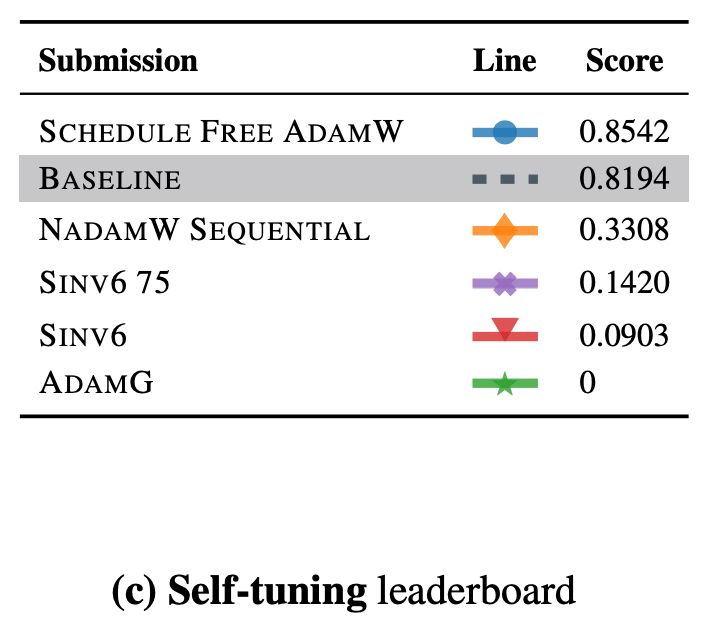
And the winner in the self-tuning ruleset, based on Schedule Free AdamW, demonstrated a new level of effectiveness for completely hyperparameter-free neural network training. Roughly ~10% faster training, compared to a NadamW baseline with well-tuned default hyperparameters.
March 14, 2025 at 8:57 PM
And the winner in the self-tuning ruleset, based on Schedule Free AdamW, demonstrated a new level of effectiveness for completely hyperparameter-free neural network training. Roughly ~10% faster training, compared to a NadamW baseline with well-tuned default hyperparameters.
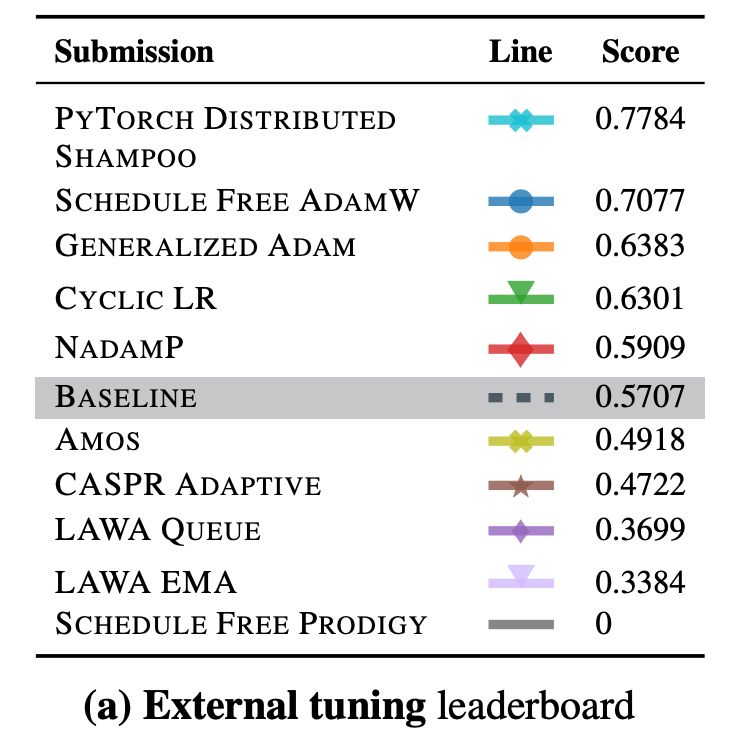
Then, we asked the community to submit training algorithms. The results? The winner of the external tuning ruleset, using Distributed Shampoo, reduced training time by ~30% over our well-tuned baseline—showing that non-diagonal methods can beat Adam, even in wall-clock time!
March 14, 2025 at 8:57 PM
Then, we asked the community to submit training algorithms. The results? The winner of the external tuning ruleset, using Distributed Shampoo, reduced training time by ~30% over our well-tuned baseline—showing that non-diagonal methods can beat Adam, even in wall-clock time!
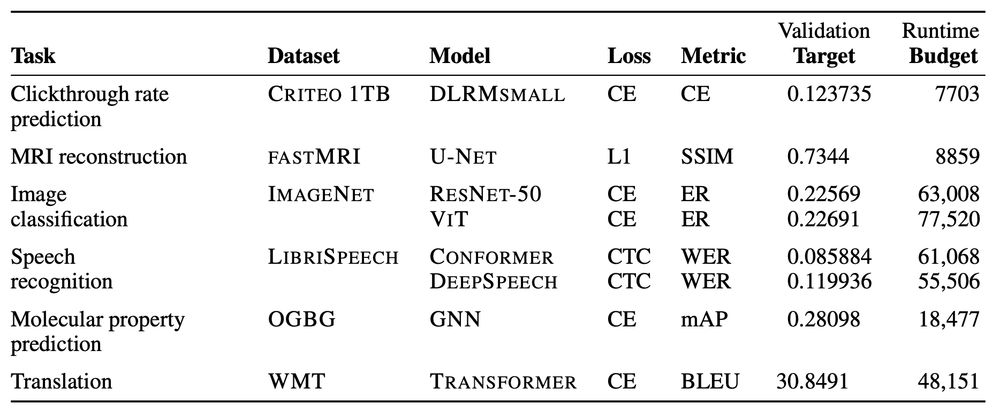
(3) Training algorithms must perform across 8 realistic deep learning workloads (ResNet-50, Conformer, ViT, etc.). (4) Submissions compete on the runtime to reach a given performance threshold. (5) Hyperparameter tuning is explicitly accounted for with our tuning rulesets.
March 14, 2025 at 8:57 PM
(3) Training algorithms must perform across 8 realistic deep learning workloads (ResNet-50, Conformer, ViT, etc.). (4) Submissions compete on the runtime to reach a given performance threshold. (5) Hyperparameter tuning is explicitly accounted for with our tuning rulesets.
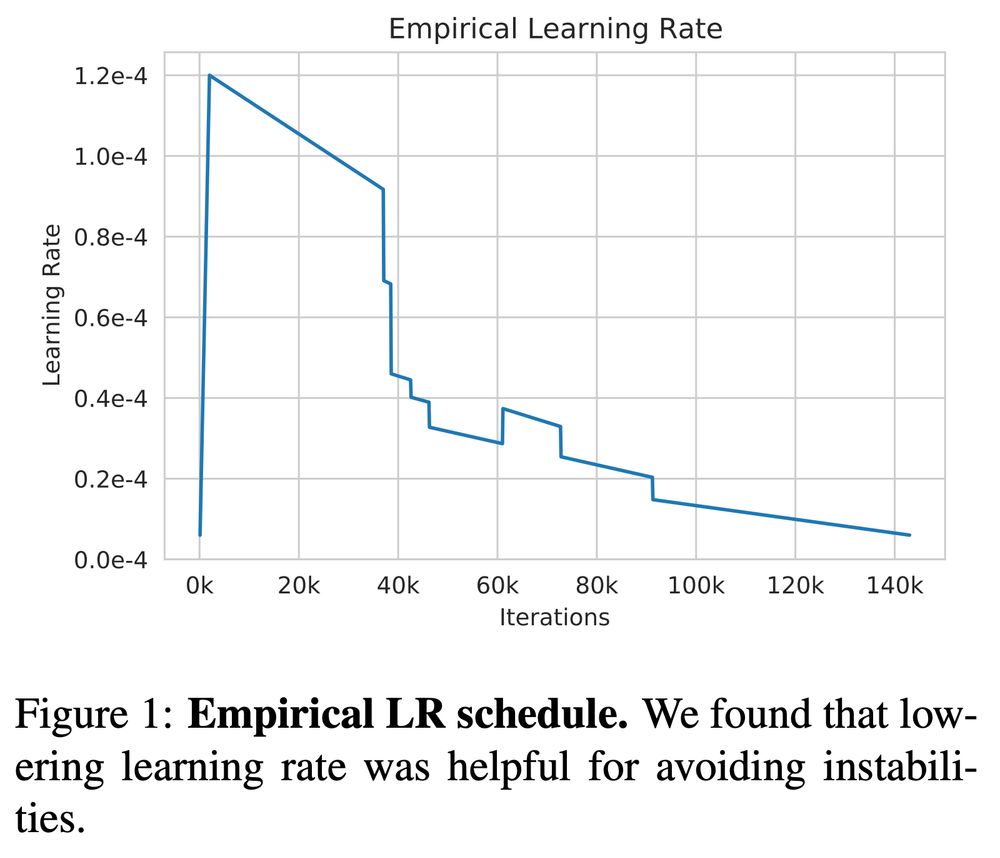
These choices are often critical, but reliable empirical guidance is scarce. Instead, we rely on expert intuition, anecdotal evidence, and babysitting. Check out this learning rate schedule from the OPT paper, which was manually determined. There has to be a better way!
March 14, 2025 at 8:57 PM
These choices are often critical, but reliable empirical guidance is scarce. Instead, we rely on expert intuition, anecdotal evidence, and babysitting. Check out this learning rate schedule from the OPT paper, which was manually determined. There has to be a better way!
Currently, training neural nets is a complicated & fragile process with many important choices: How should I set/tune the learning rate? Using what schedule? Should I use SGD or Adam (or maybe Nadam/Amos/Shampoo/SOAP/Muon/... the list is virtually endless)?
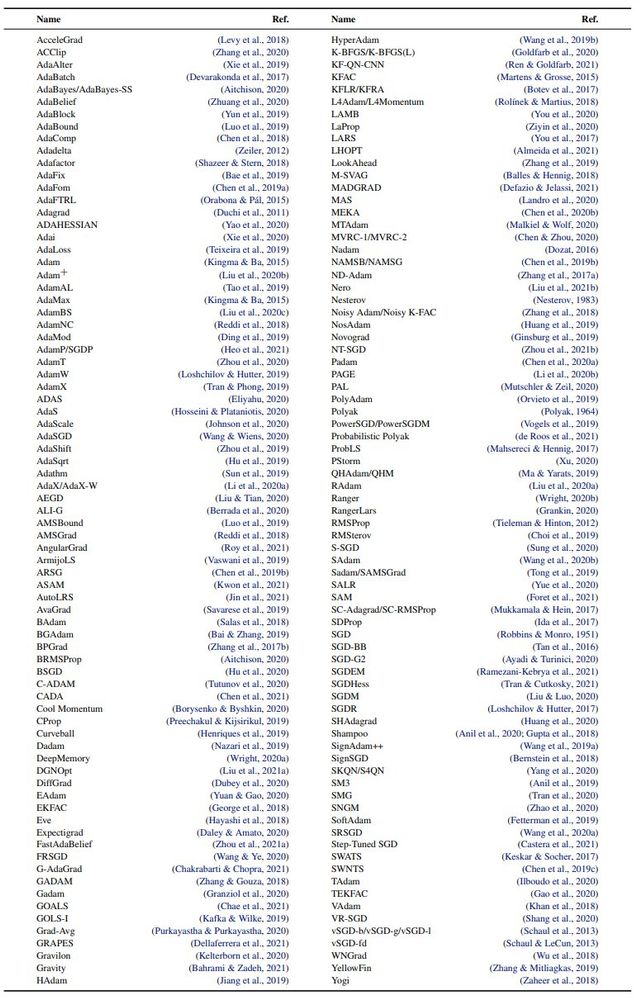
March 14, 2025 at 8:57 PM
Currently, training neural nets is a complicated & fragile process with many important choices: How should I set/tune the learning rate? Using what schedule? Should I use SGD or Adam (or maybe Nadam/Amos/Shampoo/SOAP/Muon/... the list is virtually endless)?