




Alessandro Bologna
@alessandronyc.bsky.social
Principal Architect | Polyglot Programming disciple | Hands-on development believer | Cloud Native and Serverless evangelist. Opinions are my own.
Fascinating, thank you Marc. From my little experimentation last night (inspired by your blog post) it seems that AgentCore Runtime can actually be used as a stateful-ish serverless general purpose compute service. Meaning it’s not just to run agents… Am I off?
September 24, 2025 at 1:26 PM
Fascinating, thank you Marc. From my little experimentation last night (inspired by your blog post) it seems that AgentCore Runtime can actually be used as a stateful-ish serverless general purpose compute service. Meaning it’s not just to run agents… Am I off?
Yes I remember that, but if recall correctly your findings, not having it will make it even more likely that we would end up in the suppressed init scenario (with the throttled cpu) more often, because it won’t have enough cpu to stay in the 10s the first time no?
April 30, 2025 at 7:04 PM
Yes I remember that, but if recall correctly your findings, not having it will make it even more likely that we would end up in the suppressed init scenario (with the throttled cpu) more often, because it won’t have enough cpu to stay in the 10s the first time no?
I wonder what will happen of the other “freebie”, the unthrottled cpu during init, if that is not valid anymore we will see longer cold starts I am afraid.
April 30, 2025 at 5:45 AM
I wonder what will happen of the other “freebie”, the unthrottled cpu during init, if that is not valid anymore we will see longer cold starts I am afraid.
Looks like the account that has opened the issue (probably taken over in the same way) has been busy opening just a few of them…
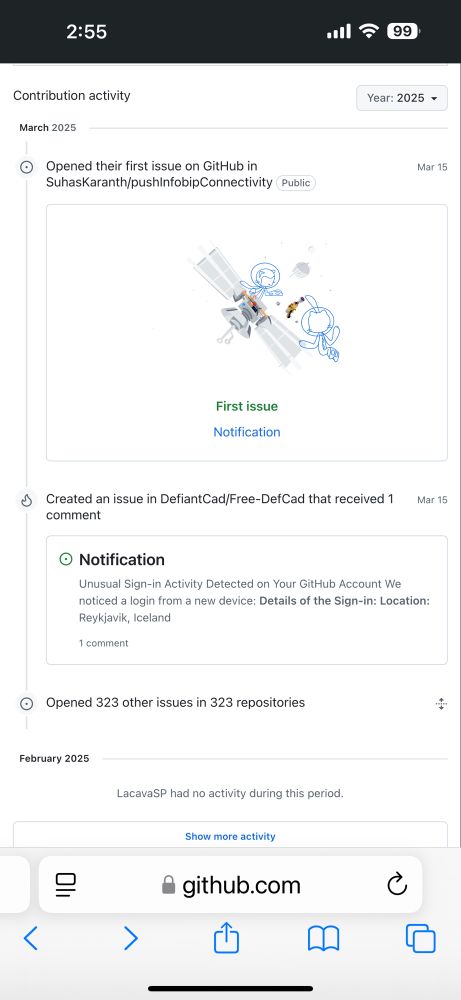
March 15, 2025 at 6:57 PM
Looks like the account that has opened the issue (probably taken over in the same way) has been busy opening just a few of them…
A better way to handle stacks composition than what CF offers (nested stacks, modules, macros, includes etc), even if client side a la CDK would be great. Just an idea… 🙂
March 3, 2025 at 2:34 AM
A better way to handle stacks composition than what CF offers (nested stacks, modules, macros, includes etc), even if client side a la CDK would be great. Just an idea… 🙂
Italiano 🇮🇹:
Impara a creare interazioni affascinanti e tocchi deliziosi usando la magia di CSS, JavaScript, SVG e Canvas
Impara a creare interazioni affascinanti e tocchi deliziosi usando la magia di CSS, JavaScript, SVG e Canvas
February 7, 2025 at 4:19 PM
Italiano 🇮🇹:
Impara a creare interazioni affascinanti e tocchi deliziosi usando la magia di CSS, JavaScript, SVG e Canvas
Impara a creare interazioni affascinanti e tocchi deliziosi usando la magia di CSS, JavaScript, SVG e Canvas
Reposted by Alessandro Bologna

So yeah "otel is hard" but mostly when what you're looking for is a drop in replacement for prometheus or an expensive vendor solution.
Like with anything new, workout how you can leverage it and how it helps you. Don't throw it out because you don't understand it.
Like with anything new, workout how you can leverage it and how it helps you. Don't throw it out because you don't understand it.
January 12, 2025 at 1:39 AM
So yeah "otel is hard" but mostly when what you're looking for is a drop in replacement for prometheus or an expensive vendor solution.
Like with anything new, workout how you can leverage it and how it helps you. Don't throw it out because you don't understand it.
Like with anything new, workout how you can leverage it and how it helps you. Don't throw it out because you don't understand it.
It may be controversial, but I have a rule: “If you can’t do math on it, it’s a string”. Helps with things like phone numbers, ZIP codes, and IDs… and spares you the horror of bugs where leading zeros mysteriously vanish. 🙂
December 30, 2024 at 1:22 PM
It may be controversial, but I have a rule: “If you can’t do math on it, it’s a string”. Helps with things like phone numbers, ZIP codes, and IDs… and spares you the horror of bugs where leading zeros mysteriously vanish. 🙂
Yes, I think I am very much aligned on this thinking, and it’s true that often are the other costs (clouwatch logs I am looking at you…) that bite more. I know about what vercel has done, but I didn’t know about Binaris? What is it?
December 28, 2024 at 6:23 PM
Yes, I think I am very much aligned on this thinking, and it’s true that often are the other costs (clouwatch logs I am looking at you…) that bite more. I know about what vercel has done, but I didn’t know about Binaris? What is it?
right, and I was wondering how much this overhead really costs anymore, with firecracker and all the other things that have been built in the last 10 years of lambda.
December 28, 2024 at 5:00 PM
right, and I was wondering how much this overhead really costs anymore, with firecracker and all the other things that have been built in the last 10 years of lambda.
When I read “oh well that’s expensive to run on lambda, so I will use a bunch of ec2 (or containers) at 30% utilization” I wonder for who it’s better to allocate those resources inefficiently. It seems it is for the customer, because of how pricing is structured, but does it need to be this way?
December 28, 2024 at 4:57 PM
When I read “oh well that’s expensive to run on lambda, so I will use a bunch of ec2 (or containers) at 30% utilization” I wonder for who it’s better to allocate those resources inefficiently. It seems it is for the customer, because of how pricing is structured, but does it need to be this way?
Absolutely, and I 100% agree. I absolutely love it. But what I was questioning wasn’t if it’s better for me (it is), what I was wondering was: if it is better for the cloud provider as well (and I suspect it is), why not incentivizing its use more, by reducing its cost?
December 28, 2024 at 4:57 PM
Absolutely, and I 100% agree. I absolutely love it. But what I was questioning wasn’t if it’s better for me (it is), what I was wondering was: if it is better for the cloud provider as well (and I suspect it is), why not incentivizing its use more, by reducing its cost?
Which does beg the question of why does lambda compute have to cost more per unit of work, however you define it. I may be wrong, but I would think that, from a cloud provider point of view, it is actually more efficient at resources and energy utilization, so is it just because of the convenience?
December 28, 2024 at 4:02 PM
Which does beg the question of why does lambda compute have to cost more per unit of work, however you define it. I may be wrong, but I would think that, from a cloud provider point of view, it is actually more efficient at resources and energy utilization, so is it just because of the convenience?
Also, this made me smile, I was wondering throughout it “how did they build it?”

December 24, 2024 at 4:28 AM
Also, this made me smile, I was wondering throughout it “how did they build it?”
Yes, tail based sampling seems to be the answer to the volume/cost problem. It also seems (didn’t try it yet myself) to be non trivial to self manage within your own infrastructure, but hey. Gotta try to tell for sure.
December 2, 2024 at 12:28 PM
Yes, tail based sampling seems to be the answer to the volume/cost problem. It also seems (didn’t try it yet myself) to be non trivial to self manage within your own infrastructure, but hey. Gotta try to tell for sure.
Good to know! Btw I meant *semconv above, got autocorrected in transit...
So, in a greenfield scenario, say a new app using otel, could one just add tracing (and forgo logs and metrics) and pick a platform that knows how to slice and dice, extract and aggregate, and query and visualize everything?
So, in a greenfield scenario, say a new app using otel, could one just add tracing (and forgo logs and metrics) and pick a platform that knows how to slice and dice, extract and aggregate, and query and visualize everything?
December 2, 2024 at 12:02 PM
Good to know! Btw I meant *semconv above, got autocorrected in transit...
So, in a greenfield scenario, say a new app using otel, could one just add tracing (and forgo logs and metrics) and pick a platform that knows how to slice and dice, extract and aggregate, and query and visualize everything?
So, in a greenfield scenario, say a new app using otel, could one just add tracing (and forgo logs and metrics) and pick a platform that knows how to slice and dice, extract and aggregate, and query and visualize everything?
Absolutely true. Retention/storage is never the main concern. 100GB of standard logs is $50 for ingestion, $0.45/month for storage. You would need the keep those logs for 9 years to pay the same for storage. 🤷🏻
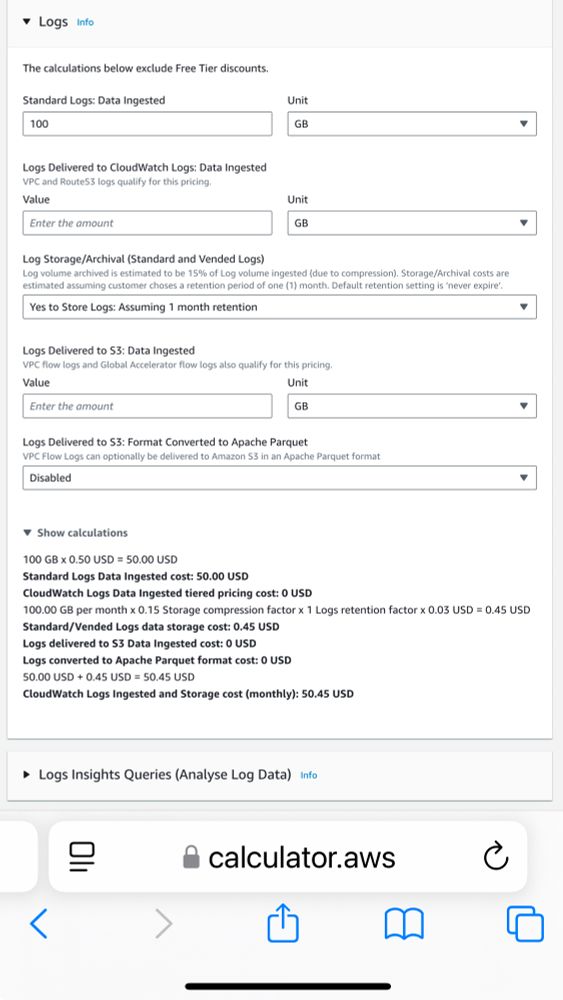
December 2, 2024 at 2:00 AM
Absolutely true. Retention/storage is never the main concern. 100GB of standard logs is $50 for ingestion, $0.45/month for storage. You would need the keep those logs for 9 years to pay the same for storage. 🤷🏻
It may have to do with historical reasons, and backward compatibility: the fanout ESM came much later and likely implemented that from the get go. I can see how that could possibly break things otherwise.
November 26, 2024 at 6:44 AM
It may have to do with historical reasons, and backward compatibility: the fanout ESM came much later and likely implemented that from the get go. I can see how that could possibly break things otherwise.
I didn’t even know that enhanced fanout would do that, I assumed you had to do the de-aggregation yourself as usual. So it does it do it for event filters and also invokes the lambda with the records already de-aggregated?
November 26, 2024 at 4:44 AM
I didn’t even know that enhanced fanout would do that, I assumed you had to do the de-aggregation yourself as usual. So it does it do it for event filters and also invokes the lambda with the records already de-aggregated?
No, I love cargo lambda, but it's to build and deploy the code, it's not a client runtime for your code, as far i know. When you create a function with `cargo lambda new` it will build a boilerplate that depends on lambda_runtime: github.com/cargo-lambda...
GitHub - cargo-lambda/new-functions-template
Contribute to cargo-lambda/new-functions-template development by creating an account on GitHub.
github.com
November 25, 2024 at 4:18 PM
No, I love cargo lambda, but it's to build and deploy the code, it's not a client runtime for your code, as far i know. When you create a function with `cargo lambda new` it will build a boilerplate that depends on lambda_runtime: github.com/cargo-lambda...
I agree, but it makes it a little harder in corporate enterprise-y environments to say “we should go with rust for lambda”. You need to advocate a lot more.
November 25, 2024 at 12:13 AM
I agree, but it makes it a little harder in corporate enterprise-y environments to say “we should go with rust for lambda”. You need to advocate a lot more.
Awesome, I hope that it means that AWS is investing more on supporting the rust lambda runtime client, maybe making it non “experimental”. github.com/awslabs/aws-...
GitHub - awslabs/aws-lambda-rust-runtime: A Rust runtime for AWS Lambda
A Rust runtime for AWS Lambda. Contribute to awslabs/aws-lambda-rust-runtime development by creating an account on GitHub.
github.com
November 24, 2024 at 11:45 PM
Awesome, I hope that it means that AWS is investing more on supporting the rust lambda runtime client, maybe making it non “experimental”. github.com/awslabs/aws-...