



ammar i marvi
@aimarvi.bsky.social
vision lab @ harvard
[i am] unbearably naive
[i am] unbearably naive
i'll be presenting this as a poster on thursday @ iclr! please come by & chat if any of this sounds interesting to you :)
thanks for reading. link to the paper again: openreview.net/forum?id=IqH...
13/13
thanks for reading. link to the paper again: openreview.net/forum?id=IqH...
13/13

Sparse components distinguish visual pathways & their alignment to...
The ventral, dorsal, and lateral streams in high-level human visual cortex are implicated in distinct functional processes. Yet, deep neural networks (DNNs) trained on a single task model the...
openreview.net
April 22, 2025 at 8:35 PM
i'll be presenting this as a poster on thursday @ iclr! please come by & chat if any of this sounds interesting to you :)
thanks for reading. link to the paper again: openreview.net/forum?id=IqH...
13/13
thanks for reading. link to the paper again: openreview.net/forum?id=IqH...
13/13
in sum, we used dominant components of the neural response to get an **axis-sensitive** measure of similarity.
this work fits into a broader look at (R)epresentational alignment (cf. work by @taliakonkle.bsky.social, @itsneuronal.bsky.social, @sucholutsky.bsky.social, & others)
12/n
this work fits into a broader look at (R)epresentational alignment (cf. work by @taliakonkle.bsky.social, @itsneuronal.bsky.social, @sucholutsky.bsky.social, & others)
12/n
April 22, 2025 at 8:35 PM
in sum, we used dominant components of the neural response to get an **axis-sensitive** measure of similarity.
this work fits into a broader look at (R)epresentational alignment (cf. work by @taliakonkle.bsky.social, @itsneuronal.bsky.social, @sucholutsky.bsky.social, & others)
12/n
this work fits into a broader look at (R)epresentational alignment (cf. work by @taliakonkle.bsky.social, @itsneuronal.bsky.social, @sucholutsky.bsky.social, & others)
12/n
we also used connectivity matrices to capture behaviorally-relevant information. a lot like rsa! but with a sparse coding structure
11/n
11/n

April 22, 2025 at 8:35 PM
we also used connectivity matrices to capture behaviorally-relevant information. a lot like rsa! but with a sparse coding structure
11/n
11/n
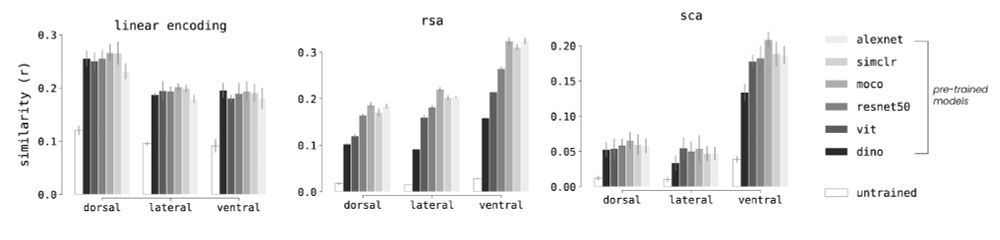
using sca and a few different pre-trained models, we found markedly higher alignment to the ventral stream.
rotationally invariant methods were less sensitive to this finding, providing an answer to question 2: DNNs are more similar to the ventral stream along a native axis of neural tuning
10/n
rotationally invariant methods were less sensitive to this finding, providing an answer to question 2: DNNs are more similar to the ventral stream along a native axis of neural tuning
10/n
April 22, 2025 at 8:35 PM
using sca and a few different pre-trained models, we found markedly higher alignment to the ventral stream.
rotationally invariant methods were less sensitive to this finding, providing an answer to question 2: DNNs are more similar to the ventral stream along a native axis of neural tuning
10/n
rotationally invariant methods were less sensitive to this finding, providing an answer to question 2: DNNs are more similar to the ventral stream along a native axis of neural tuning
10/n
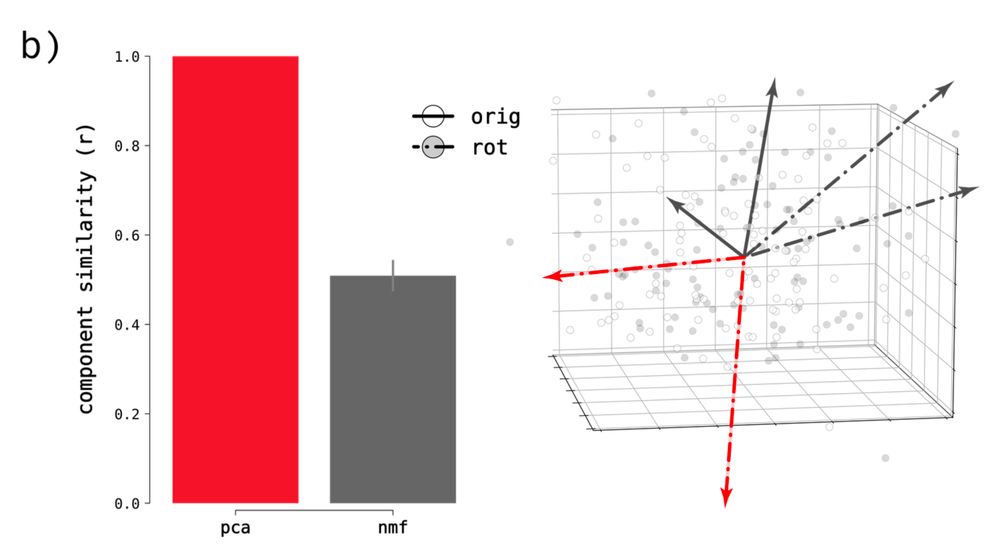
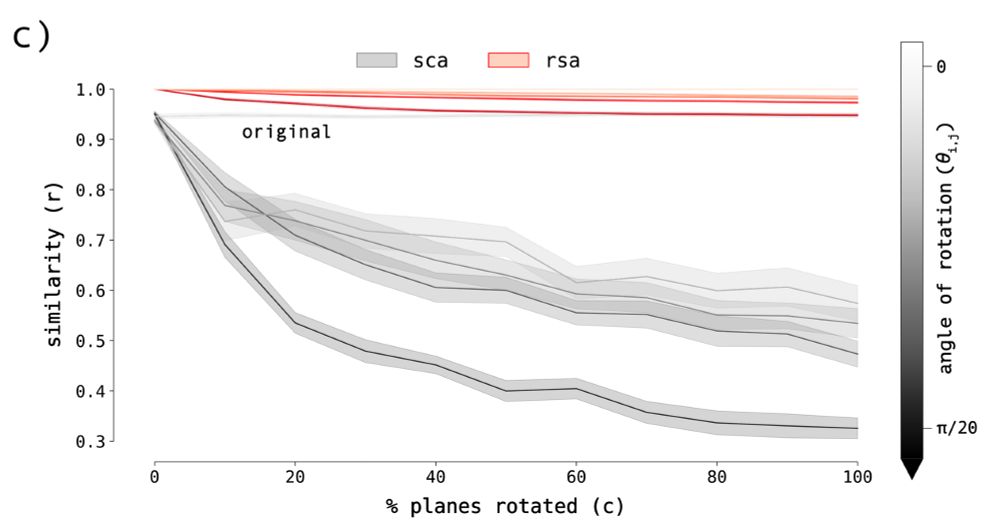
the resulting matrices represent the activity of sparse sub-populations of neurons/units and, unlike some methods, are quite sensitive to rotations in neural space
you can thus interpret sca as measuring similarity along a specific set of tuning axes
9/n
you can thus interpret sca as measuring similarity along a specific set of tuning axes
9/n
April 22, 2025 at 8:35 PM
the resulting matrices represent the activity of sparse sub-populations of neurons/units and, unlike some methods, are quite sensitive to rotations in neural space
you can thus interpret sca as measuring similarity along a specific set of tuning axes
9/n
you can thus interpret sca as measuring similarity along a specific set of tuning axes
9/n
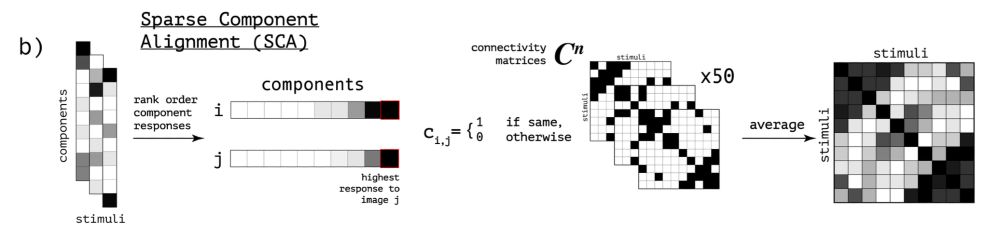
we applied the same decomposition to DNN activations and used them in a method we call **sparse component alignment** (sca). sca compares representations at the population level using image x image connectivity matrices.
(see the paper for complete derivation)
8/n
(see the paper for complete derivation)
8/n
April 22, 2025 at 8:35 PM
we applied the same decomposition to DNN activations and used them in a method we call **sparse component alignment** (sca). sca compares representations at the population level using image x image connectivity matrices.
(see the paper for complete derivation)
8/n
(see the paper for complete derivation)
8/n
these response profiles gave an answer to question 1: there are interpretable and functionally-distinct representations across the brain's three visual pathways.
nice to see! but also heightens the mystery of question 2: why aren't these differences picked up by standard similarity metrics
7/n
nice to see! but also heightens the mystery of question 2: why aren't these differences picked up by standard similarity metrics
7/n
April 22, 2025 at 8:35 PM
these response profiles gave an answer to question 1: there are interpretable and functionally-distinct representations across the brain's three visual pathways.
nice to see! but also heightens the mystery of question 2: why aren't these differences picked up by standard similarity metrics
7/n
nice to see! but also heightens the mystery of question 2: why aren't these differences picked up by standard similarity metrics
7/n
we reproduced well-known category selectivity in the ventral stream (for faces, scenes, bodies, etc).
new in this paper we also found components in the lateral stream (groups of people, implied motion, hand actions, scenes, & reachspaces) and dorsal stream (implied motion & scenes)
6/n
new in this paper we also found components in the lateral stream (groups of people, implied motion, hand actions, scenes, & reachspaces) and dorsal stream (implied motion & scenes)
6/n
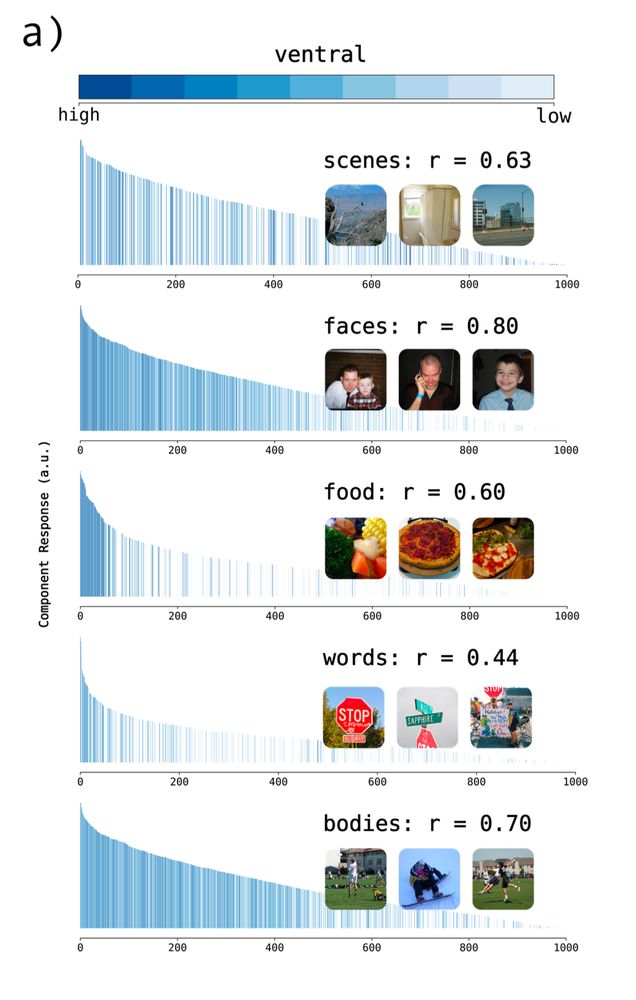
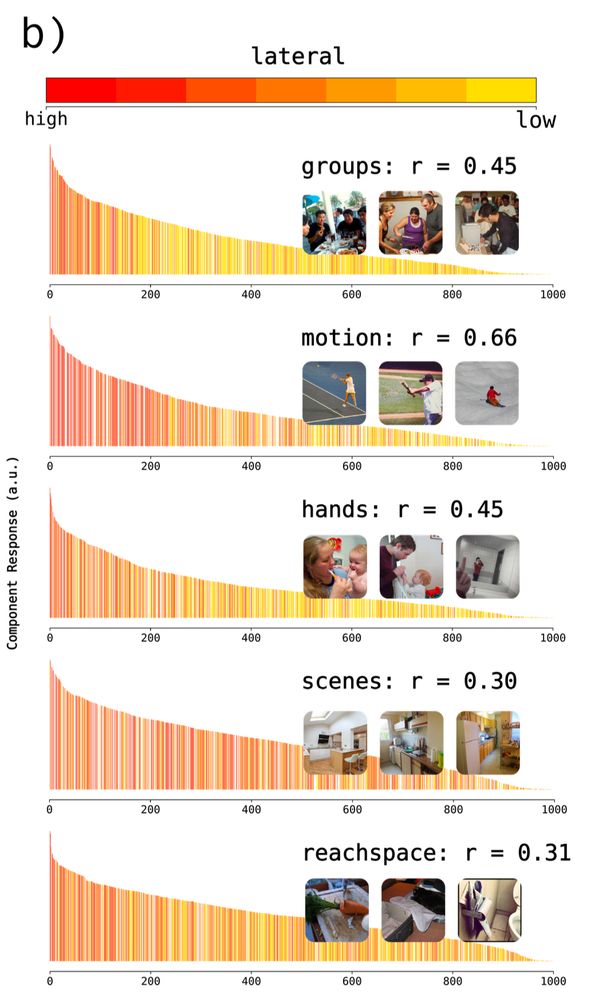
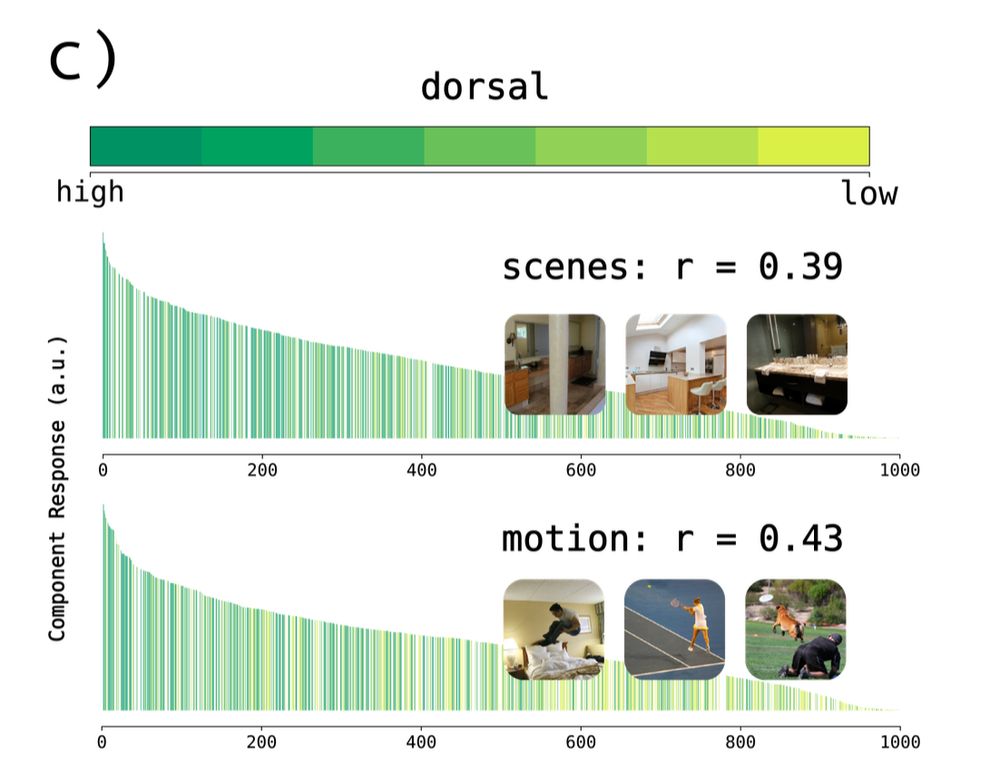
April 22, 2025 at 8:35 PM
we reproduced well-known category selectivity in the ventral stream (for faces, scenes, bodies, etc).
new in this paper we also found components in the lateral stream (groups of people, implied motion, hand actions, scenes, & reachspaces) and dorsal stream (implied motion & scenes)
6/n
new in this paper we also found components in the lateral stream (groups of people, implied motion, hand actions, scenes, & reachspaces) and dorsal stream (implied motion & scenes)
6/n
to find out, we used a data-driven method to identify dominant components of the neural response to natural images.
some of the most consistent components had pretty clear selectivities, which we cross-validated with behavioral saliency ratings
5/n
some of the most consistent components had pretty clear selectivities, which we cross-validated with behavioral saliency ratings
5/n
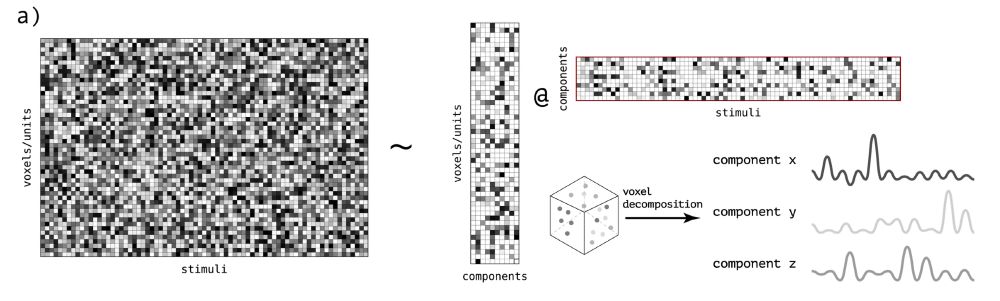
April 22, 2025 at 8:35 PM
to find out, we used a data-driven method to identify dominant components of the neural response to natural images.
some of the most consistent components had pretty clear selectivities, which we cross-validated with behavioral saliency ratings
5/n
some of the most consistent components had pretty clear selectivities, which we cross-validated with behavioral saliency ratings
5/n
this left us with two big questions:
1. what distinguishes visual representations in the dorsal, ventral, & lateral streams?
2. why does alignment to DNNs often fail to reflect these differences?
4/n
1. what distinguishes visual representations in the dorsal, ventral, & lateral streams?
2. why does alignment to DNNs often fail to reflect these differences?
4/n
April 22, 2025 at 8:35 PM
this left us with two big questions:
1. what distinguishes visual representations in the dorsal, ventral, & lateral streams?
2. why does alignment to DNNs often fail to reflect these differences?
4/n
1. what distinguishes visual representations in the dorsal, ventral, & lateral streams?
2. why does alignment to DNNs often fail to reflect these differences?
4/n
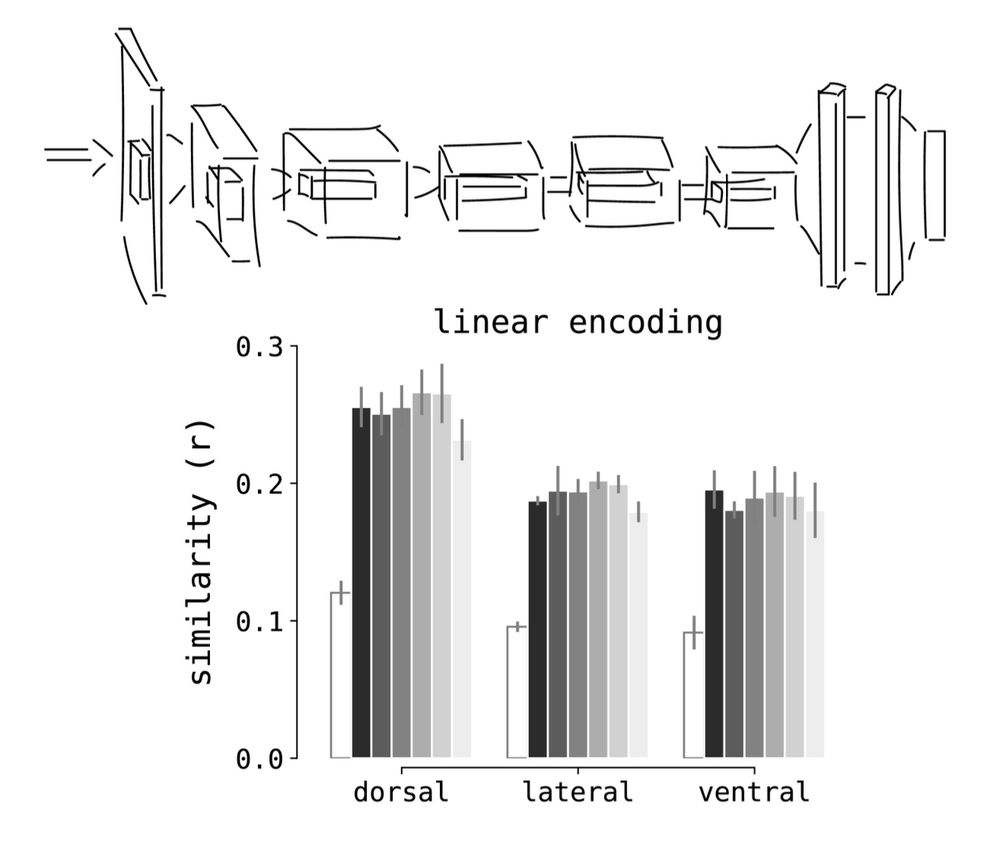
yet neural networks trained to perform a single task seem to model all three pathways pretty well. so perhaps the representations in these streams are not so different after all?
3/n
3/n
April 22, 2025 at 8:35 PM
yet neural networks trained to perform a single task seem to model all three pathways pretty well. so perhaps the representations in these streams are not so different after all?
3/n
3/n
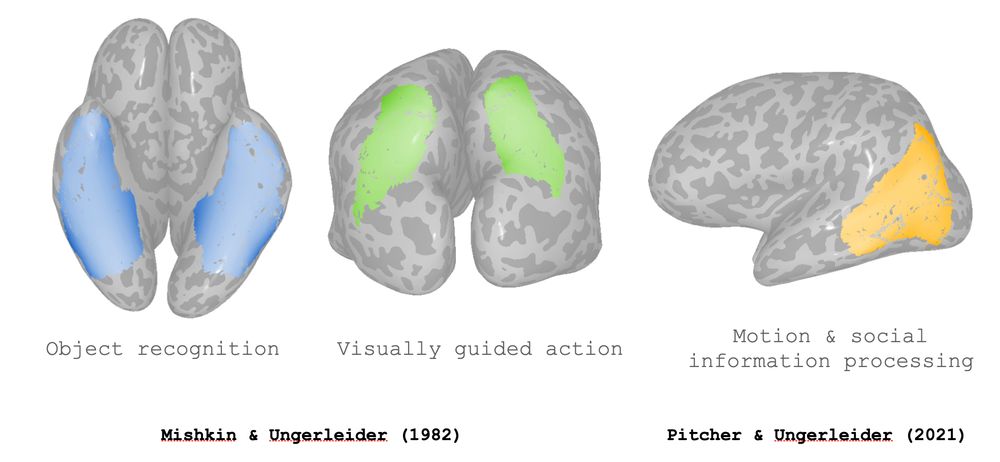
it's commonly thought that the brain processes distinct visual information along separate functional pathways (the dorsal, ventral, & lateral streams)
2/n
2/n
April 22, 2025 at 8:35 PM
it's commonly thought that the brain processes distinct visual information along separate functional pathways (the dorsal, ventral, & lateral streams)
2/n
2/n