
Alex McFarland
@aidisruptor.ai
Creator of aidisruptor.ai - my community of 4,000+ everyday people learning how to use AI tools through practical guides.
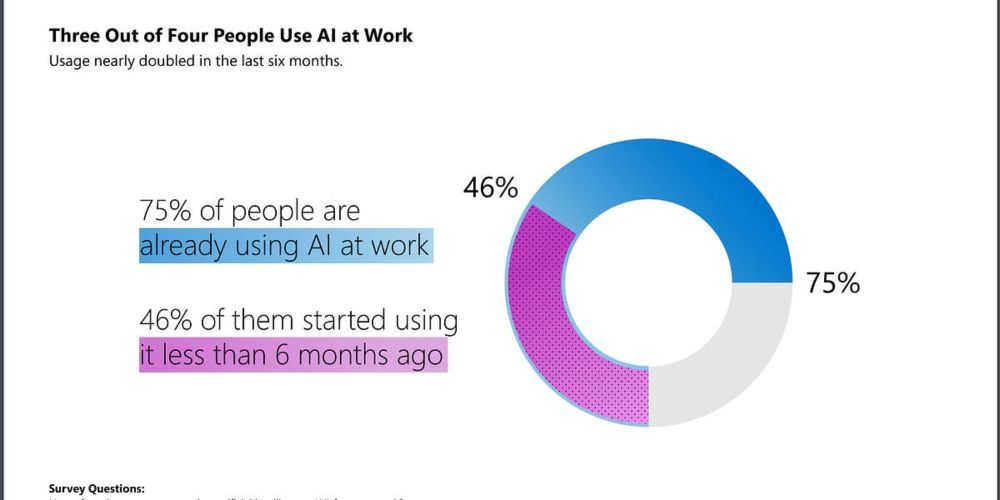
This framework is a shift toward practical AI-human collaboration in research, prioritizing efficiency while maintaining human expertise in the research process.
January 14, 2025 at 8:49 PM
This framework is a shift toward practical AI-human collaboration in research, prioritizing efficiency while maintaining human expertise in the research process.
⚠️ Key limitations
- Generated papers score 1.45 points below average NeurIPS submissions
- AI reviewers consistently rate papers 2.3 points higher than human reviewers
- Requires active human oversight for optimal results
- Generated papers score 1.45 points below average NeurIPS submissions
- AI reviewers consistently rate papers 2.3 points higher than human reviewers
- Requires active human oversight for optimal results
January 14, 2025 at 8:49 PM
⚠️ Key limitations
- Generated papers score 1.45 points below average NeurIPS submissions
- AI reviewers consistently rate papers 2.3 points higher than human reviewers
- Requires active human oversight for optimal results
- Generated papers score 1.45 points below average NeurIPS submissions
- AI reviewers consistently rate papers 2.3 points higher than human reviewers
- Requires active human oversight for optimal results
🏆 Model performance
- o1-preview: Highest scores in usefulness and clarity
- o1-mini: Best experimental quality scores
- GPT-4o: Most cost-efficient, fastest processing
- o1-preview: Highest scores in usefulness and clarity
- o1-mini: Best experimental quality scores
- GPT-4o: Most cost-efficient, fastest processing
January 14, 2025 at 8:49 PM
🏆 Model performance
- o1-preview: Highest scores in usefulness and clarity
- o1-mini: Best experimental quality scores
- GPT-4o: Most cost-efficient, fastest processing
- o1-preview: Highest scores in usefulness and clarity
- o1-mini: Best experimental quality scores
- GPT-4o: Most cost-efficient, fastest processing
📊 Performance metrics
- Speed: Complete workflow in 1,165.4 seconds using GPT-4o
- Cost: $2.33 per paper (84% reduction from traditional methods)
- Quality: Papers score 4.38/10 with human collaboration
- Speed: Complete workflow in 1,165.4 seconds using GPT-4o
- Cost: $2.33 per paper (84% reduction from traditional methods)
- Quality: Papers score 4.38/10 with human collaboration
January 14, 2025 at 8:49 PM
📊 Performance metrics
- Speed: Complete workflow in 1,165.4 seconds using GPT-4o
- Cost: $2.33 per paper (84% reduction from traditional methods)
- Quality: Papers score 4.38/10 with human collaboration
- Speed: Complete workflow in 1,165.4 seconds using GPT-4o
- Cost: $2.33 per paper (84% reduction from traditional methods)
- Quality: Papers score 4.38/10 with human collaboration
👥 A virtual research team
- PhD Agent: Handles literature reviews and research planning
- Postdoc Agents: Refine experimental approaches
- ML Engineer Agents: Manage technical implementation
- Professor Agents: Evaluate research outputs
- PhD Agent: Handles literature reviews and research planning
- Postdoc Agents: Refine experimental approaches
- ML Engineer Agents: Manage technical implementation
- Professor Agents: Evaluate research outputs
January 14, 2025 at 8:49 PM
👥 A virtual research team
- PhD Agent: Handles literature reviews and research planning
- Postdoc Agents: Refine experimental approaches
- ML Engineer Agents: Manage technical implementation
- Professor Agents: Evaluate research outputs
- PhD Agent: Handles literature reviews and research planning
- Postdoc Agents: Refine experimental approaches
- ML Engineer Agents: Manage technical implementation
- Professor Agents: Evaluate research outputs
🎯 What makes it different
- Creates a virtual research team with specialized AI agents
- Focuses on enhancing (not replacing) human researchers
- Enables flexible compute allocation based on resources and needs
- Creates a virtual research team with specialized AI agents
- Focuses on enhancing (not replacing) human researchers
- Enables flexible compute allocation based on resources and needs
January 14, 2025 at 8:49 PM
🎯 What makes it different
- Creates a virtual research team with specialized AI agents
- Focuses on enhancing (not replacing) human researchers
- Enables flexible compute allocation based on resources and needs
- Creates a virtual research team with specialized AI agents
- Focuses on enhancing (not replacing) human researchers
- Enables flexible compute allocation based on resources and needs
Pro tip: Start small.
Pick a recent announcement you care about and try the process. You might be surprised by what you discover when you combine these different sources.
Pick a recent announcement you care about and try the process. You might be surprised by what you discover when you combine these different sources.
January 9, 2025 at 9:51 PM
Pro tip: Start small.
Pick a recent announcement you care about and try the process. You might be surprised by what you discover when you combine these different sources.
Pick a recent announcement you care about and try the process. You might be surprised by what you discover when you combine these different sources.
3️⃣ The community insight: Collective wisdom
By feeding in structured community discussions (I'll show you exactly how in the video), you tap into the collective expertise of developers, industry insiders, and power users who spot implications that journalists miss.
By feeding in structured community discussions (I'll show you exactly how in the video), you tap into the collective expertise of developers, industry insiders, and power users who spot implications that journalists miss.
January 9, 2025 at 9:51 PM
3️⃣ The community insight: Collective wisdom
By feeding in structured community discussions (I'll show you exactly how in the video), you tap into the collective expertise of developers, industry insiders, and power users who spot implications that journalists miss.
By feeding in structured community discussions (I'll show you exactly how in the video), you tap into the collective expertise of developers, industry insiders, and power users who spot implications that journalists miss.
2️⃣ The analyst perspective: Critical context
I specifically look for articles with unique angles - not basic summaries.
This second layer helps you understand market implications and read between the lines.
I specifically look for articles with unique angles - not basic summaries.
This second layer helps you understand market implications and read between the lines.
January 9, 2025 at 9:51 PM
2️⃣ The analyst perspective: Critical context
I specifically look for articles with unique angles - not basic summaries.
This second layer helps you understand market implications and read between the lines.
I specifically look for articles with unique angles - not basic summaries.
This second layer helps you understand market implications and read between the lines.
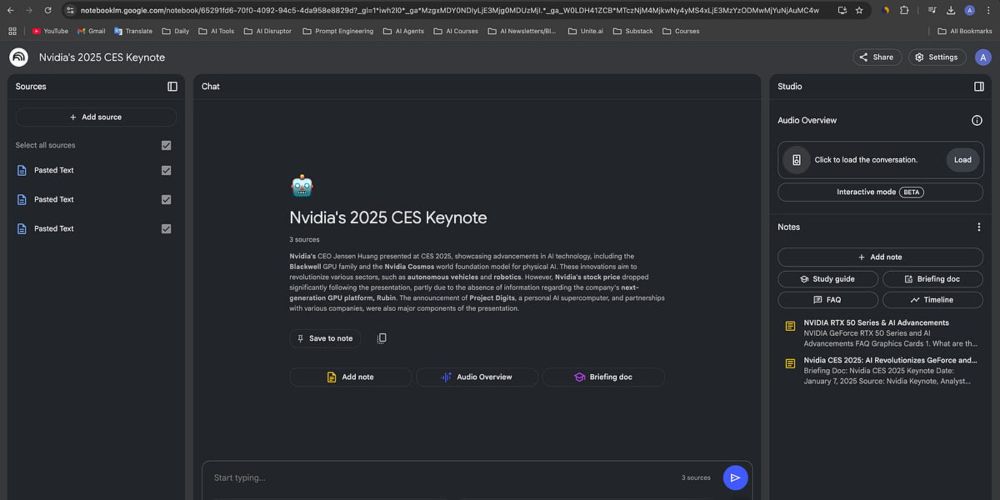
1️⃣ The raw source: Your foundation
When you feed a keynote transcript into NotebookLM, you're creating a base layer of knowledge that lets you verify claims, spot patterns, and catch details.
This becomes your ground truth - especially important when everyone's racing to interpret what was said.
When you feed a keynote transcript into NotebookLM, you're creating a base layer of knowledge that lets you verify claims, spot patterns, and catch details.
This becomes your ground truth - especially important when everyone's racing to interpret what was said.
January 9, 2025 at 9:51 PM
1️⃣ The raw source: Your foundation
When you feed a keynote transcript into NotebookLM, you're creating a base layer of knowledge that lets you verify claims, spot patterns, and catch details.
This becomes your ground truth - especially important when everyone's racing to interpret what was said.
When you feed a keynote transcript into NotebookLM, you're creating a base layer of knowledge that lets you verify claims, spot patterns, and catch details.
This becomes your ground truth - especially important when everyone's racing to interpret what was said.
Our Discord: sidestack.io/aidisruptor
Sign in - AI Disruptor | Alex McFarland | Substack
sidestack.io
January 7, 2025 at 2:26 PM
Our Discord: sidestack.io/aidisruptor