



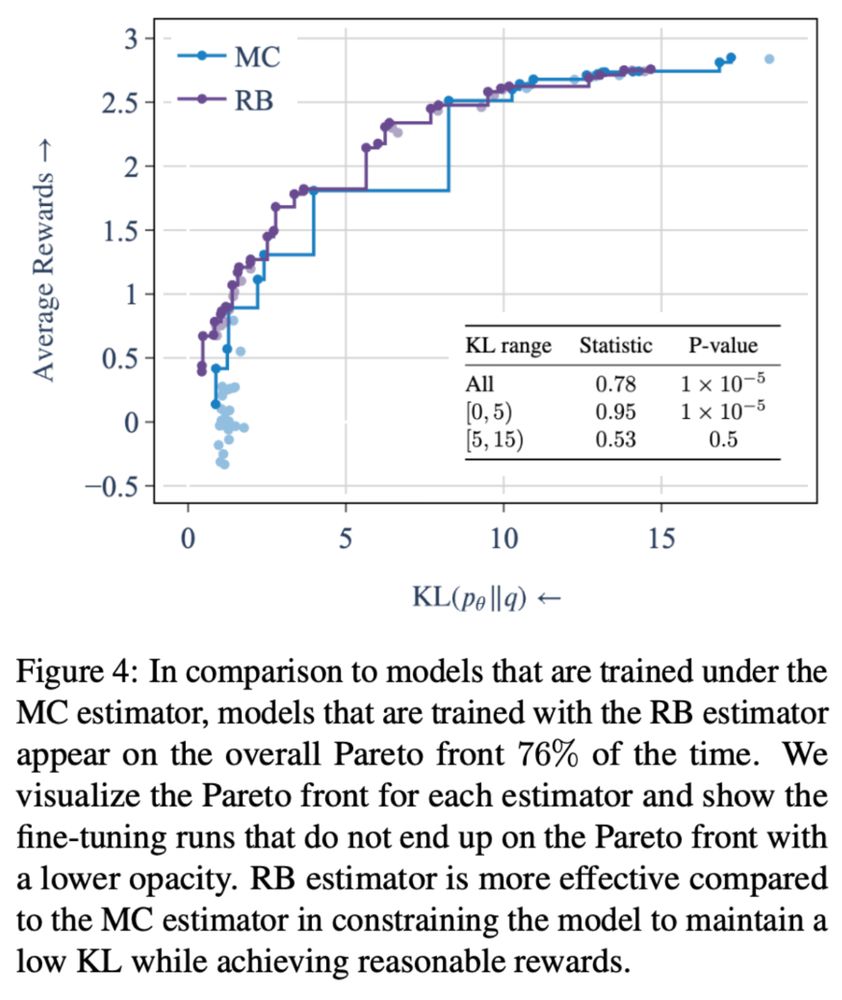
Finally, we plot the reward–KL Pareto frontier across various KL regularization settings. We find that the RB estimator more effectively constrains the KL divergence, and models trained with it appear significantly more often on the Pareto front:
May 6, 2025 at 2:59 PM
Finally, we plot the reward–KL Pareto frontier across various KL regularization settings. We find that the RB estimator more effectively constrains the KL divergence, and models trained with it appear significantly more often on the Pareto front:
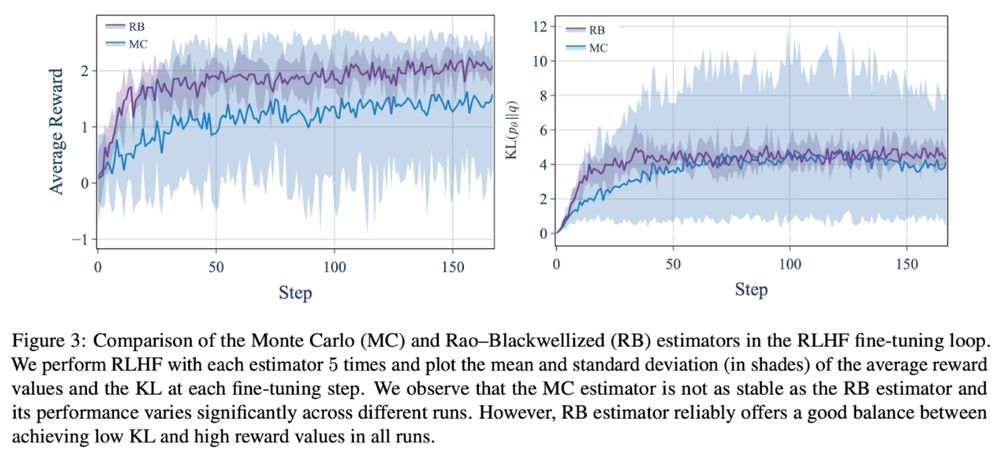
In RLHF training, using our RB estimator yields more stable runs compared to the MC estimator. It achieves high rewards while reliably preventing the KL divergence from increasing beyond an acceptable range:
May 6, 2025 at 2:59 PM
In RLHF training, using our RB estimator yields more stable runs compared to the MC estimator. It achieves high rewards while reliably preventing the KL divergence from increasing beyond an acceptable range:
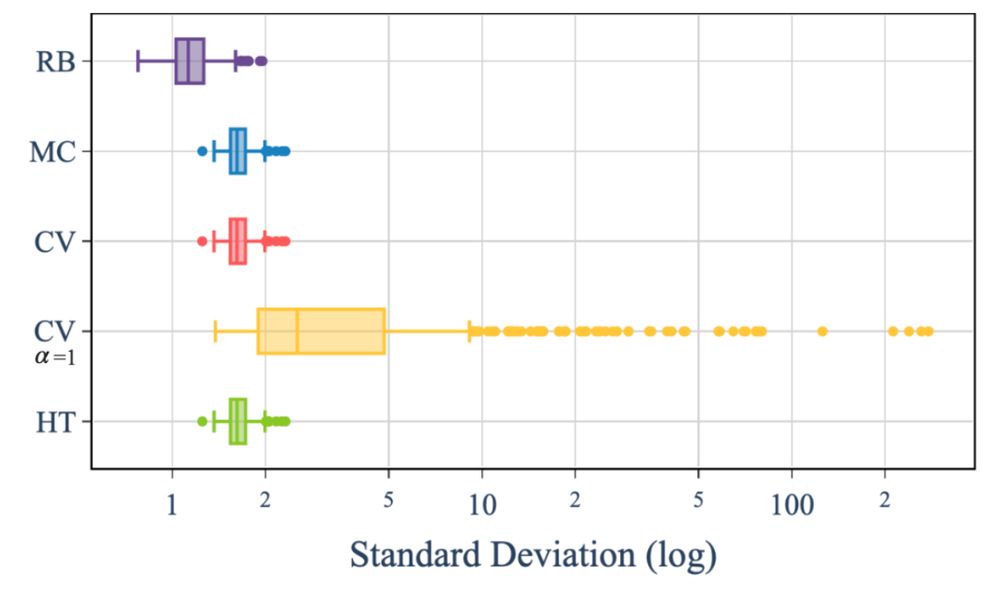
When evaluating the KL divergence between the language model before and after preference alignment, our estimator (RB) consistently yields lower standard deviation across all prompts compared to every other estimator available in public RLHF libraries:
May 6, 2025 at 2:59 PM
When evaluating the KL divergence between the language model before and after preference alignment, our estimator (RB) consistently yields lower standard deviation across all prompts compared to every other estimator available in public RLHF libraries:
All it took was applying Rao–Blackwellization—a classic variance reduction trick—to the Monte Carlo (MC) estimator, and carefully adapting it for LMs. The result is simple: condition on prefixes and replace the MC estimate with its conditional expectation:
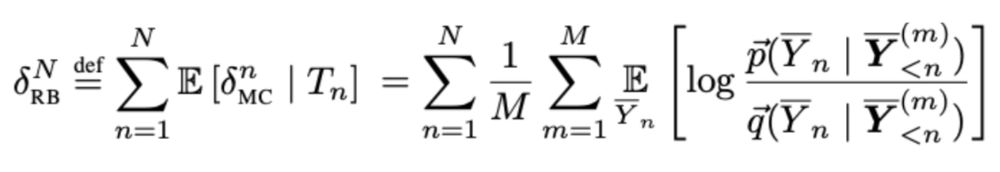
May 6, 2025 at 2:59 PM
All it took was applying Rao–Blackwellization—a classic variance reduction trick—to the Monte Carlo (MC) estimator, and carefully adapting it for LMs. The result is simple: condition on prefixes and replace the MC estimate with its conditional expectation:
Current KL estimation practices in RLHF can generate high variance and even negative values! We propose a provably better estimator that only takes a few lines of code to implement.🧵👇
w/ @xtimv.bsky.social and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb
w/ @xtimv.bsky.social and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb

May 6, 2025 at 2:59 PM
Current KL estimation practices in RLHF can generate high variance and even negative values! We propose a provably better estimator that only takes a few lines of code to implement.🧵👇
w/ @xtimv.bsky.social and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb
w/ @xtimv.bsky.social and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb