



Jörg Tiedemann
@tiedeman.bsky.social
Professor of Language Technology at the University of Helsinki @helsinki.fi
Head of Helsinki-NLP @helsinki-nlp.bsky.social
Member of the Ellis unit Helsinki @ellisfinland.bsky.social
Head of Helsinki-NLP @helsinki-nlp.bsky.social
Member of the Ellis unit Helsinki @ellisfinland.bsky.social
Don't forget the deadline on Monday, January 12! Join us at @helsinki-nlp.bsky.social as a new ELLIS PI.
ELLIS Institute Finland is hiring Principal Investigators in AI + machine learning. World-class resources for research incl. LUMI supercomputer, generous starting package & professorship affiliation with a university in the world’s happiest country! Apply by Jan. 12 ellisinstitute.fi/PI-recruit-2026

January 10, 2026 at 8:56 AM
Don't forget the deadline on Monday, January 12! Join us at @helsinki-nlp.bsky.social as a new ELLIS PI.
Come and join us at @helsinki-nlp.bsky.social to work on robust, efficient and trustworthy AI across languages and domains. You will be part of the @ellisinstitute.fi as one of the prestigious PIs in their top-level research unit.
Application deadline is January 12: tinyurl.com/ye6ceywv
Application deadline is January 12: tinyurl.com/ye6ceywv
PI positions | ELLIS Institute Finland
ELLIS Institute Finland PI positions (second call, winter 2025–26)
www.ellisinstitute.fi
November 24, 2025 at 6:50 AM
Come and join us at @helsinki-nlp.bsky.social to work on robust, efficient and trustworthy AI across languages and domains. You will be part of the @ellisinstitute.fi as one of the prestigious PIs in their top-level research unit.
Application deadline is January 12: tinyurl.com/ye6ceywv
Application deadline is January 12: tinyurl.com/ye6ceywv
Reposted by Jörg Tiedemann

See you next week at EMNLP!
We will be presenting our work: Scaling Low-Resource MT via Synthetic Data Generation with LLMs
📍 Poster Session 13
📅 Fri, Nov 7, 10:30-12:00 - Hall C
📖 Check it out! arxiv.org/abs/2505.14423
@helsinki-nlp.bsky.social @cambridgenlp.bsky.social @emnlpmeeting.bsky.social
We will be presenting our work: Scaling Low-Resource MT via Synthetic Data Generation with LLMs
📍 Poster Session 13
📅 Fri, Nov 7, 10:30-12:00 - Hall C
📖 Check it out! arxiv.org/abs/2505.14423
@helsinki-nlp.bsky.social @cambridgenlp.bsky.social @emnlpmeeting.bsky.social

Scaling Low-Resource MT via Synthetic Data Generation with LLMs
We investigate the potential of LLM-generated synthetic data for improving low-resource Machine Translation (MT). Focusing on seven diverse target languages, we construct a document-level synthetic co...
arxiv.org
October 28, 2025 at 8:16 AM
See you next week at EMNLP!
We will be presenting our work: Scaling Low-Resource MT via Synthetic Data Generation with LLMs
📍 Poster Session 13
📅 Fri, Nov 7, 10:30-12:00 - Hall C
📖 Check it out! arxiv.org/abs/2505.14423
@helsinki-nlp.bsky.social @cambridgenlp.bsky.social @emnlpmeeting.bsky.social
We will be presenting our work: Scaling Low-Resource MT via Synthetic Data Generation with LLMs
📍 Poster Session 13
📅 Fri, Nov 7, 10:30-12:00 - Hall C
📖 Check it out! arxiv.org/abs/2505.14423
@helsinki-nlp.bsky.social @cambridgenlp.bsky.social @emnlpmeeting.bsky.social
Reposted by Jörg Tiedemann

Timeline:
- Paper submission: Dec 19
- Commitment for pre-reviewed papers: Jan 2
- Acceptance notifs: Jan 23
- Camera-ready: Feb 3
- Workshop: TBD (Mar 24-29)
Organizers:
Yves Scherrer, Noëmi Aepli, @tosaja.bsky.social, Nikola Ljubešić, Preslav Nakov, @tiedeman.bsky.social, Marcos Zampieri & me
- Paper submission: Dec 19
- Commitment for pre-reviewed papers: Jan 2
- Acceptance notifs: Jan 23
- Camera-ready: Feb 3
- Workshop: TBD (Mar 24-29)
Organizers:
Yves Scherrer, Noëmi Aepli, @tosaja.bsky.social, Nikola Ljubešić, Preslav Nakov, @tiedeman.bsky.social, Marcos Zampieri & me
October 21, 2025 at 10:36 AM
Timeline:
- Paper submission: Dec 19
- Commitment for pre-reviewed papers: Jan 2
- Acceptance notifs: Jan 23
- Camera-ready: Feb 3
- Workshop: TBD (Mar 24-29)
Organizers:
Yves Scherrer, Noëmi Aepli, @tosaja.bsky.social, Nikola Ljubešić, Preslav Nakov, @tiedeman.bsky.social, Marcos Zampieri & me
- Paper submission: Dec 19
- Commitment for pre-reviewed papers: Jan 2
- Acceptance notifs: Jan 23
- Camera-ready: Feb 3
- Workshop: TBD (Mar 24-29)
Organizers:
Yves Scherrer, Noëmi Aepli, @tosaja.bsky.social, Nikola Ljubešić, Preslav Nakov, @tiedeman.bsky.social, Marcos Zampieri & me
Reposted by Jörg Tiedemann

🧠 We explore how monolingual, bilingual, and code-augmented data shape multilingual continual pretraining across high- to low-resource languages.
Big thanks to my supervisor @tiedeman.bsky.social man.bsky.social, who will be presenting our poster — come say hi!
Big thanks to my supervisor @tiedeman.bsky.social man.bsky.social, who will be presenting our poster — come say hi!
October 7, 2025 at 12:51 PM
🧠 We explore how monolingual, bilingual, and code-augmented data shape multilingual continual pretraining across high- to low-resource languages.
Big thanks to my supervisor @tiedeman.bsky.social man.bsky.social, who will be presenting our poster — come say hi!
Big thanks to my supervisor @tiedeman.bsky.social man.bsky.social, who will be presenting our poster — come say hi!
It’s happening, the 18th MT Marathon (blogs.helsinki.fi/language-tec...) will start tomorrow with a great line-up in our program. Looking forward to see you all in Helsinki!
MT Marathon 2025 – Language Technology
blogs.helsinki.fi
August 24, 2025 at 1:17 PM
It’s happening, the 18th MT Marathon (blogs.helsinki.fi/language-tec...) will start tomorrow with a great line-up in our program. Looking forward to see you all in Helsinki!
Reposted by Jörg Tiedemann

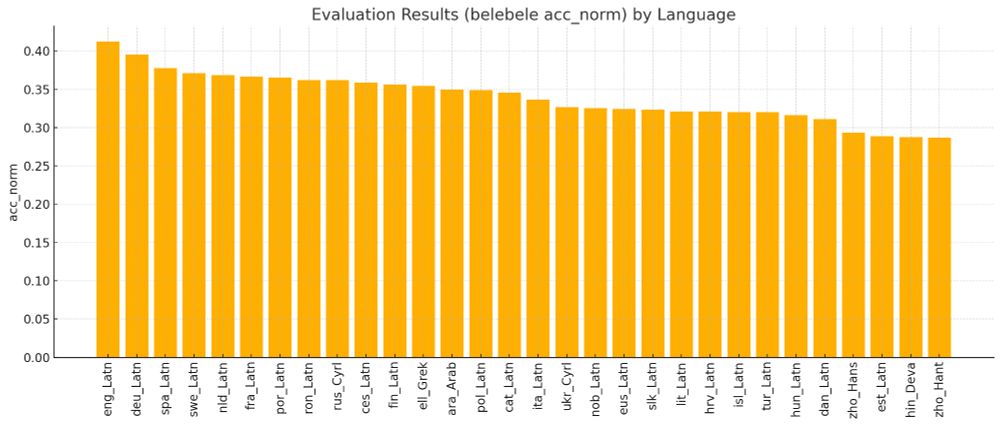
📢 First release: 38 monolingual reference LLMs (2.15B params) via #HPLT + #OpenEuroLLM
⚙️Trained on 100B tokens from HPLT v2 dataset
🌍 Cover EU langs + others
⚙️ Based on LLaMA, trained on #LUMI
📈 Useful for evaluation
Downloads + more info at openeurollm.eu/blog/hplt-oe...
⚙️Trained on 100B tokens from HPLT v2 dataset
🌍 Cover EU langs + others
⚙️ Based on LLaMA, trained on #LUMI
📈 Useful for evaluation
Downloads + more info at openeurollm.eu/blog/hplt-oe...
July 18, 2025 at 9:32 AM
📢 First release: 38 monolingual reference LLMs (2.15B params) via #HPLT + #OpenEuroLLM
⚙️Trained on 100B tokens from HPLT v2 dataset
🌍 Cover EU langs + others
⚙️ Based on LLaMA, trained on #LUMI
📈 Useful for evaluation
Downloads + more info at openeurollm.eu/blog/hplt-oe...
⚙️Trained on 100B tokens from HPLT v2 dataset
🌍 Cover EU langs + others
⚙️ Based on LLaMA, trained on #LUMI
📈 Useful for evaluation
Downloads + more info at openeurollm.eu/blog/hplt-oe...
Wanna read great demo papers at EMNLP 2025? You can, because remember: It's *YOUR* community too! So roll up your sleeves and join our program committee as a reviewer: docs.google.com/forms/d/e/1F...

EMNLP 2025 Demo: Reviewer self-nomination
This is an open call to reserchers from industry and academia to help us with peer-reviewing in the EMNLP 2025 Demo Track.
Requirements:
* Publication record in EMNLP/ACL/NAACL/EACL-affiliated venues...
docs.google.com
May 25, 2025 at 9:29 AM
Wanna read great demo papers at EMNLP 2025? You can, because remember: It's *YOUR* community too! So roll up your sleeves and join our program committee as a reviewer: docs.google.com/forms/d/e/1F...
Reposted by Jörg Tiedemann

📢 [**mala-opus-dedup-2410**](huggingface.co/datasets/MaL...) 🎉
Part of the [**MaLA Corpus**](huggingface.co/collections/...), deduplicated dataset from [OPUS](opus.nlpl.eu) (cutoff Oct 2024) features **16,829 language pairs** with deduplication, normalization, and noise filtering
Part of the [**MaLA Corpus**](huggingface.co/collections/...), deduplicated dataset from [OPUS](opus.nlpl.eu) (cutoff Oct 2024) features **16,829 language pairs** with deduplication, normalization, and noise filtering

MaLA-LM/mala-opus-dedup-2410 · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
May 18, 2025 at 11:00 AM
📢 [**mala-opus-dedup-2410**](huggingface.co/datasets/MaL...) 🎉
Part of the [**MaLA Corpus**](huggingface.co/collections/...), deduplicated dataset from [OPUS](opus.nlpl.eu) (cutoff Oct 2024) features **16,829 language pairs** with deduplication, normalization, and noise filtering
Part of the [**MaLA Corpus**](huggingface.co/collections/...), deduplicated dataset from [OPUS](opus.nlpl.eu) (cutoff Oct 2024) features **16,829 language pairs** with deduplication, normalization, and noise filtering
Reposted by Jörg Tiedemann
Join us on May 16 at 10:00 EEST (Helsinki time) for a session hosted by GreenNLP and the NVIDIA AI Technology Center (NVAITC) Finland on developments in NLP technologies using the NeMo framework. greennlp.github.io/news/2025/04...

May 14, 2025 at 8:45 PM
Join us on May 16 at 10:00 EEST (Helsinki time) for a session hosted by GreenNLP and the NVIDIA AI Technology Center (NVAITC) Finland on developments in NLP technologies using the NeMo framework. greennlp.github.io/news/2025/04...
Reposted by Jörg Tiedemann
Call for participation: We just opened the registration for this year's MT Marathon in August in Helsinki, Finland: blogs.helsinki.fi/language-tec..., featuring:
- Ayodele Awokoya
- Wilker Aziz
- Marta Costa-Jussa
- Barry Haddow
- Amit Moryosse
- Sara Papi
- Jörg Tiedemann
- Marco Turchi
- Ayodele Awokoya
- Wilker Aziz
- Marta Costa-Jussa
- Barry Haddow
- Amit Moryosse
- Sara Papi
- Jörg Tiedemann
- Marco Turchi
blogs.helsinki.fi
March 18, 2025 at 12:57 PM
Call for participation: We just opened the registration for this year's MT Marathon in August in Helsinki, Finland: blogs.helsinki.fi/language-tec..., featuring:
- Ayodele Awokoya
- Wilker Aziz
- Marta Costa-Jussa
- Barry Haddow
- Amit Moryosse
- Sara Papi
- Jörg Tiedemann
- Marco Turchi
- Ayodele Awokoya
- Wilker Aziz
- Marta Costa-Jussa
- Barry Haddow
- Amit Moryosse
- Sara Papi
- Jörg Tiedemann
- Marco Turchi
Reposted by Jörg Tiedemann

The NoDaLiDa x Baltic-HLT Proceedings are up!
See here: www.nodalida-bhlt2025.eu/proceedings
See you also soon in Tallinn!
#NLP #NLProc #nodalida #baltichlt
See here: www.nodalida-bhlt2025.eu/proceedings
See you also soon in Tallinn!
#NLP #NLProc #nodalida #baltichlt

NoDaLiDa/Baltic-HLT 2025 - Proceedings
The proceedings of NoDaLiDa/Baltic-HLT 2025, the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies, are published by the University of...
www.nodalida-bhlt2025.eu
February 28, 2025 at 10:51 AM
The NoDaLiDa x Baltic-HLT Proceedings are up!
See here: www.nodalida-bhlt2025.eu/proceedings
See you also soon in Tallinn!
#NLP #NLProc #nodalida #baltichlt
See here: www.nodalida-bhlt2025.eu/proceedings
See you also soon in Tallinn!
#NLP #NLProc #nodalida #baltichlt
Separating me from the @helsinki-nlp.bsky.social account is probably a good idea, is it?
February 11, 2025 at 7:20 PM
Separating me from the @helsinki-nlp.bsky.social account is probably a good idea, is it?
There is an open position for a postdoc in our lab in this call. The focus will be on scalable modular NLP with funding from the ERC PoC project MARMoT

Postdoc and PhD positions available in AI/ML. Deadline March 2 at 11:59PM Finnish time (UTC+ 2) More info in the 🔗https://www.hiit.fi/ict-community-researcher-positions/ #postdocjob #academicjobs #STEMjobs #PhDsky #postdocposition

Postdoctoral and Doctoral Researcher Positions in ICT
Apply now
Postdoctoral and Doctoral Researcher Positions in Artificial Intelligence/ Machine Learning (Helsinki, Finland)
Researchers from Aalto University and the University of Helsinki are looking ...
www.hiit.fi
February 7, 2025 at 2:12 PM
There is an open position for a postdoc in our lab in this call. The focus will be on scalable modular NLP with funding from the ERC PoC project MARMoT
Reposted by Jörg Tiedemann

I have big news: @ellis.eu has launched its 2nd major research center, @ellisfinland.bsky.social! I have agreed to start as founding director & the first call for PI positions is open. This is a major opportunity for outstanding researchers, join us! ellisinstitute.fi/PI-recruit

Principal Investigator positions at ELLIS Institute Finland | ELLIS Institute Finland
Now recruiting new PIs in artificial intelligence and machine learning
ellisinstitute.fi
February 4, 2025 at 2:40 PM
I have big news: @ellis.eu has launched its 2nd major research center, @ellisfinland.bsky.social! I have agreed to start as founding director & the first call for PI positions is open. This is a major opportunity for outstanding researchers, join us! ellisinstitute.fi/PI-recruit
Reposted by Jörg Tiedemann

ELLIS Institute Finland is hiring Principal Investigators in AI + machine learning. World-class resources for research incl. LUMI supercomputer, generous starting package & professorship affiliation with a university in the world’s happiest country! Apply by March 9: ellisinstitute.fi/PI-recruit

February 4, 2025 at 3:16 PM
ELLIS Institute Finland is hiring Principal Investigators in AI + machine learning. World-class resources for research incl. LUMI supercomputer, generous starting package & professorship affiliation with a university in the world’s happiest country! Apply by March 9: ellisinstitute.fi/PI-recruit
Reposted by Jörg Tiedemann
It's time for transparent AI in Europe. It's time for open LLMs as a robust foundation for developing future private and public AI services. It's time for:
OPEN = open-source
Euro = under EU regulations, representing EU values
LLM = LLMs
openeurollm.eu
OPEN = open-source
Euro = under EU regulations, representing EU values
LLM = LLMs
openeurollm.eu

February 3, 2025 at 4:06 PM
It's time for transparent AI in Europe. It's time for open LLMs as a robust foundation for developing future private and public AI services. It's time for:
OPEN = open-source
Euro = under EU regulations, representing EU values
LLM = LLMs
openeurollm.eu
OPEN = open-source
Euro = under EU regulations, representing EU values
LLM = LLMs
openeurollm.eu
Time for the first post on Bluesky: the ERC decided to give funding to our proof-of-concept project MARMoT blogs.helsinki.fi/language-tec...

January 24, 2025 at 11:45 AM
Time for the first post on Bluesky: the ERC decided to give funding to our proof-of-concept project MARMoT blogs.helsinki.fi/language-tec...