



Ryan Z Friedman, PhD
@rfriedman22.bsky.social
Gene regulation, machine learning, data viz | Postdoc with Cole Trapnell, comp bio PhD with Barak Cohen and Mike A White
🏳️🌈✡️ he/him
https://ryanzfriedman.com/
🏳️🌈✡️ he/him
https://ryanzfriedman.com/
I decided to try out blogging! My first post is a reflection of my time on science Twitter and why I decided to start blogging. I'm going to give Bluesky a second chance, but It's nice to have a space for casual long-form writing
ryanzfriedman.com/2025/09/06/s...
ryanzfriedman.com/2025/09/06/s...
Reflections of an ex-Twitter user
I’ve had this website for almost 5 years. In that time, it’s been pretty bare-bones, primarily serving as a landing page for me to share my general scientific interests with the world. I built a blog ...
ryanzfriedman.com
September 8, 2025 at 4:13 PM
I decided to try out blogging! My first post is a reflection of my time on science Twitter and why I decided to start blogging. I'm going to give Bluesky a second chance, but It's nice to have a space for casual long-form writing
ryanzfriedman.com/2025/09/06/s...
ryanzfriedman.com/2025/09/06/s...
Thanks so much Tim!
January 9, 2025 at 6:40 AM
Thanks so much Tim!
Thanks so much Jacob!
January 8, 2025 at 4:08 PM
Thanks so much Jacob!
Thank you Alex!!
January 8, 2025 at 5:33 AM
Thank you Alex!!
I first had this idea 6.5 years ago, early on in grad school. This journey has been a long one. I couldn't have done it without the support and guidance from @genologos.bsky.social and Barak Cohen, our collaboration with @corbolab.bsky.social, or help with the modeling and analysis from my coauthors
January 8, 2025 at 12:18 AM
I first had this idea 6.5 years ago, early on in grad school. This journey has been a long one. I couldn't have done it without the support and guidance from @genologos.bsky.social and Barak Cohen, our collaboration with @corbolab.bsky.social, or help with the modeling and analysis from my coauthors
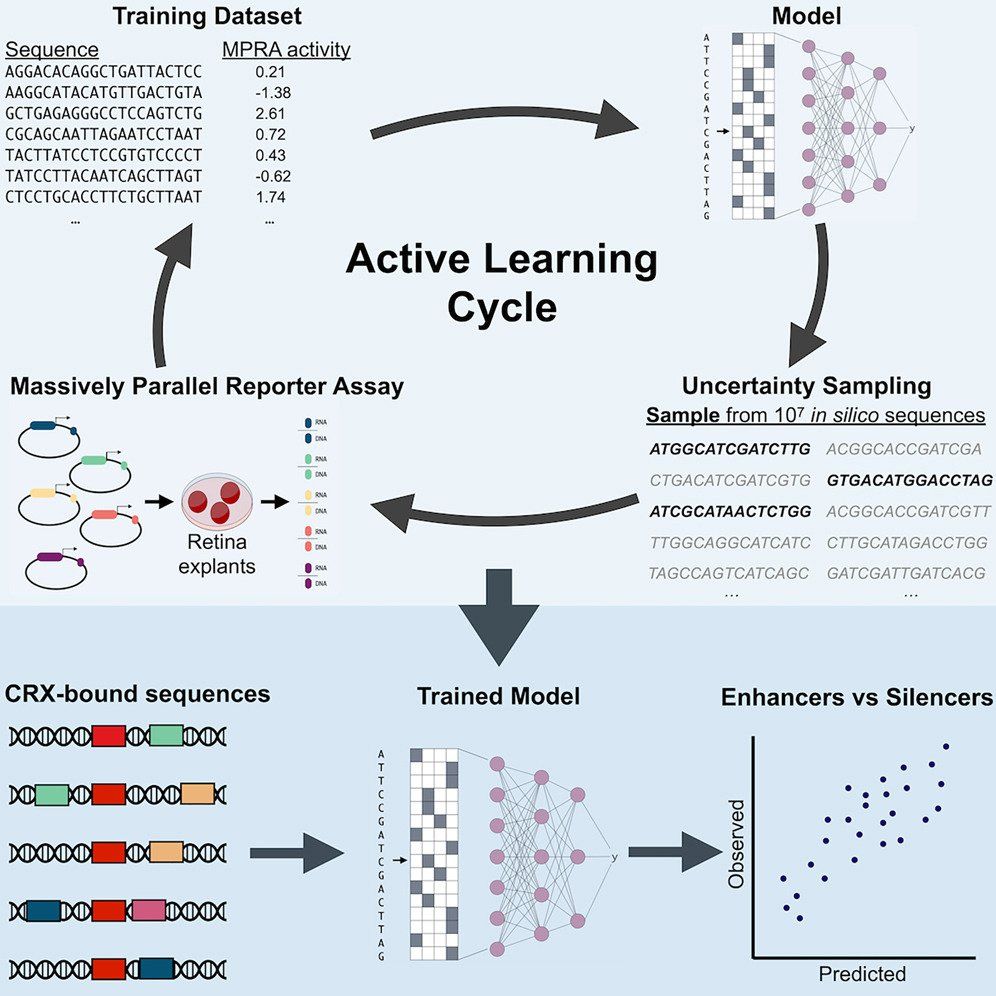
Our solution is to let your model guide you. By focusing on uncertain sequences and testing them functional genomic assays, you can *iteratively* train a model. We applied this to understand why the same DNA sequence motif has radically different effects in different contexts.
January 8, 2025 at 12:18 AM
Our solution is to let your model guide you. By focusing on uncertain sequences and testing them functional genomic assays, you can *iteratively* train a model. We applied this to understand why the same DNA sequence motif has radically different effects in different contexts.
My thesis work on active machine learning to model regulatory DNA is now out in Cell Systems!
We answer the question: When you can synthesize any DNA sequence you want, how do you decide which ones are worth testing?
www.sciencedirect.com/science/arti...
We answer the question: When you can synthesize any DNA sequence you want, how do you decide which ones are worth testing?
www.sciencedirect.com/science/arti...
January 8, 2025 at 12:18 AM
My thesis work on active machine learning to model regulatory DNA is now out in Cell Systems!
We answer the question: When you can synthesize any DNA sequence you want, how do you decide which ones are worth testing?
www.sciencedirect.com/science/arti...
We answer the question: When you can synthesize any DNA sequence you want, how do you decide which ones are worth testing?
www.sciencedirect.com/science/arti...
Reposted by Ryan Z Friedman, PhD

I posted an editorial yesterday on the need for neurodiversity in science where I also disclosed my own diagnosis as autistic. I also wrote a substack on my journey to the disclosure also in this thread. #actuallyautistic www.science.org/doi/10.1126/...

Science needs neurodiversity
All brains work differently. Individuals process information and engage with the world in ways that are influenced by a multitude of biological, cultural, and social factors. In the world of science, ...
www.science.org
April 26, 2024 at 3:01 PM
I posted an editorial yesterday on the need for neurodiversity in science where I also disclosed my own diagnosis as autistic. I also wrote a substack on my journey to the disclosure also in this thread. #actuallyautistic www.science.org/doi/10.1126/...
Many thanks to Yawei Wu, Lloyd Tripp, and Daniel Lyon for their help with these analyses!
The manuscript itself is also restructured. Figs 2 and 4 are swapped, there's a 5th fig for the K562 analysis, and we reworked the Discussion.
Apologies if threading isn't the way to go on Bsky. 🧬🔄
8/8
The manuscript itself is also restructured. Figs 2 and 4 are swapped, there's a 5th fig for the K562 analysis, and we reworked the Discussion.
Apologies if threading isn't the way to go on Bsky. 🧬🔄
8/8
February 20, 2024 at 7:00 PM
Many thanks to Yawei Wu, Lloyd Tripp, and Daniel Lyon for their help with these analyses!
The manuscript itself is also restructured. Figs 2 and 4 are swapped, there's a 5th fig for the K562 analysis, and we reworked the Discussion.
Apologies if threading isn't the way to go on Bsky. 🧬🔄
8/8
The manuscript itself is also restructured. Figs 2 and 4 are swapped, there's a 5th fig for the K562 analysis, and we reworked the Discussion.
Apologies if threading isn't the way to go on Bsky. 🧬🔄
8/8
We analyzed a second pair of sequences with similar motif content. The model correctly predicts that the RORB motif must be 3' of the CRX motif.
These results show our model learns the context that distinguishes functionally non-equivalent motifs.
7/
These results show our model learns the context that distinguishes functionally non-equivalent motifs.
7/

February 20, 2024 at 6:59 PM
We analyzed a second pair of sequences with similar motif content. The model correctly predicts that the RORB motif must be 3' of the CRX motif.
These results show our model learns the context that distinguishes functionally non-equivalent motifs.
7/
These results show our model learns the context that distinguishes functionally non-equivalent motifs.
7/
RORB motifs have a wide range of effects when mutated. Our model predicts this correctly & these effects are correlated with motif affinity.
Along with our other results, this shows active learning generates the data needed to learn regulatory grammars.
6/
Along with our other results, this shows active learning generates the data needed to learn regulatory grammars.
6/

February 20, 2024 at 6:58 PM
RORB motifs have a wide range of effects when mutated. Our model predicts this correctly & these effects are correlated with motif affinity.
Along with our other results, this shows active learning generates the data needed to learn regulatory grammars.
6/
Along with our other results, this shows active learning generates the data needed to learn regulatory grammars.
6/
We have a new result showing that our model accurately predicts when CRX motifs increase vs. decrease expression. This is crucial because nc variants can change activity in unexpected directions, so it's important to have data that can tell when a motif has a positive vs negative effect.
5/
5/

February 20, 2024 at 6:58 PM
We have a new result showing that our model accurately predicts when CRX motifs increase vs. decrease expression. This is crucial because nc variants can change activity in unexpected directions, so it's important to have data that can tell when a motif has a positive vs negative effect.
5/
5/
Our experiments suggest that inactive sequences are low-information training examples. This is important because large libraries derived from random DNA are mostly inactive seqs. We think iteratively training models on smaller but more informative training data is more effective
4/
4/
February 20, 2024 at 6:57 PM
Our experiments suggest that inactive sequences are low-information training examples. This is important because large libraries derived from random DNA are mostly inactive seqs. We think iteratively training models on smaller but more informative training data is more effective
4/
4/
When we did many rounds, active learning was more efficient, approached the upper bound with less data, and enriched for positive examples!
This demonstrates that active learning is broadly effective and illustrate that enriching for active sequences is more informative
3/
This demonstrates that active learning is broadly effective and illustrate that enriching for active sequences is more informative
3/


February 20, 2024 at 6:57 PM
When we did many rounds, active learning was more efficient, approached the upper bound with less data, and enriched for positive examples!
This demonstrates that active learning is broadly effective and illustrate that enriching for active sequences is more informative
3/
This demonstrates that active learning is broadly effective and illustrate that enriching for active sequences is more informative
3/
We tested active learning in a second system using Nadav Ahituv and @jshendure.bsky.social's genome-wide MPRA in K562s. We downsampled the data, trained a CNN, then sampled from the remaining data. Active learning consistently outperformed random sampling across many starting conditions.
2/
2/


February 20, 2024 at 6:57 PM
We tested active learning in a second system using Nadav Ahituv and @jshendure.bsky.social's genome-wide MPRA in K562s. We downsampled the data, trained a CNN, then sampled from the remaining data. Active learning consistently outperformed random sampling across many starting conditions.
2/
2/
We substantially revised our active learning manuscript. A brief summary of what's new.
TLDR: several new analyses, benchmarking w a 2nd MPRA dataset, and a refocused argument on active learning to leverage the capacity of MPRAs to generate large datasets.
www.biorxiv.org/content/10.1...
1/8
🧬🔄
TLDR: several new analyses, benchmarking w a 2nd MPRA dataset, and a refocused argument on active learning to leverage the capacity of MPRAs to generate large datasets.
www.biorxiv.org/content/10.1...
1/8
🧬🔄
February 20, 2024 at 6:55 PM
We substantially revised our active learning manuscript. A brief summary of what's new.
TLDR: several new analyses, benchmarking w a 2nd MPRA dataset, and a refocused argument on active learning to leverage the capacity of MPRAs to generate large datasets.
www.biorxiv.org/content/10.1...
1/8
🧬🔄
TLDR: several new analyses, benchmarking w a 2nd MPRA dataset, and a refocused argument on active learning to leverage the capacity of MPRAs to generate large datasets.
www.biorxiv.org/content/10.1...
1/8
🧬🔄
A project I contributed to during grad school is now up at PLoS Comp Bio! We used the MAVE-NN package by @jbkinney.bsky.social's group to learn about the behavior of synthetic regulatory elements 🧬🔄 Keep an eye on @genologos.bsky.social's Twitter for more details.
journals.plos.org/ploscompbiol...
journals.plos.org/ploscompbiol...
January 17, 2024 at 1:02 AM
A project I contributed to during grad school is now up at PLoS Comp Bio! We used the MAVE-NN package by @jbkinney.bsky.social's group to learn about the behavior of synthetic regulatory elements 🧬🔄 Keep an eye on @genologos.bsky.social's Twitter for more details.
journals.plos.org/ploscompbiol...
journals.plos.org/ploscompbiol...
I should note that I set up my folders somewhere around my third year of grad school and haven't meaningfully reorganized it since then, so I'm open to a complete overhaul.
January 17, 2024 at 12:55 AM
I should note that I set up my folders somewhere around my third year of grad school and haven't meaningfully reorganized it since then, so I'm open to a complete overhaul.
I want to reorganize my @paperpile.bsky.social. I have folders covering broad topics with very few subfolders. Tags are for different manuscripts.
Is there anyone in genomics 🖥️🧬 who wants to share how they organize their reference managers? I'm looking for more meaningful and detailed categories.
Is there anyone in genomics 🖥️🧬 who wants to share how they organize their reference managers? I'm looking for more meaningful and detailed categories.
January 17, 2024 at 12:55 AM
I want to reorganize my @paperpile.bsky.social. I have folders covering broad topics with very few subfolders. Tags are for different manuscripts.
Is there anyone in genomics 🖥️🧬 who wants to share how they organize their reference managers? I'm looking for more meaningful and detailed categories.
Is there anyone in genomics 🖥️🧬 who wants to share how they organize their reference managers? I'm looking for more meaningful and detailed categories.
Next time I meet a techie asking how to move into compbio I’ll connect them with you!
December 5, 2023 at 4:30 PM
Next time I meet a techie asking how to move into compbio I’ll connect them with you!
Yeah, I struggle with finding a polite way to say “go learn a bunch of biology or take a huge pay cut to be an entry level bioinformatician for a few years” but there is definitely a mode of thought among some techies that they can watch 20 hours of YouTube videos and call it good
December 5, 2023 at 4:07 PM
Yeah, I struggle with finding a polite way to say “go learn a bunch of biology or take a huge pay cut to be an entry level bioinformatician for a few years” but there is definitely a mode of thought among some techies that they can watch 20 hours of YouTube videos and call it good
Reposted by Ryan Z Friedman, PhD


I've had several software engineers ask me recently about transitioning into genomics/comp bio from tech. I never know what to say -- everyone I know in the field in industry went to school for biology/comp bio. Anyone have any suggestions, either of what to say or concrete resources to provide? 🧬🖥️
December 4, 2023 at 10:21 PM
I've had several software engineers ask me recently about transitioning into genomics/comp bio from tech. I never know what to say -- everyone I know in the field in industry went to school for biology/comp bio. Anyone have any suggestions, either of what to say or concrete resources to provide? 🧬🖥️
Agreed that there is strong cell to cell variability. But changes in e.g. the ZRS enhancer of Shh can cause loss of limbs or gain of extra digits. Some of that is due to changes in Shh in space/time, but some is also due to how *much* Shh is produced
October 11, 2023 at 9:21 PM
Agreed that there is strong cell to cell variability. But changes in e.g. the ZRS enhancer of Shh can cause loss of limbs or gain of extra digits. Some of that is due to changes in Shh in space/time, but some is also due to how *much* Shh is produced
hmm...A difference in 2 vs 3 fold change can definitely matter! Over/underactive CREs can cause developmental defects and disease. Agreed that cell culture won't tell you space+time, but they can tell you information about how sequence features encode activity.
October 11, 2023 at 9:13 PM
hmm...A difference in 2 vs 3 fold change can definitely matter! Over/underactive CREs can cause developmental defects and disease. Agreed that cell culture won't tell you space+time, but they can tell you information about how sequence features encode activity.