



Raphael Bednarsky
@rbednarsky.bsky.social
Predoctoral Fellow Computational Biomedical Science | Christoph Bock Lab | CeMM | Center for Artificial Intelligence of the Medical University of Vienna
Interesting thoughts from A. Karpathy's interview at the Dwarkesh podcast:
LLMs are collapsed. Their output itself is good, but the distribution of their outputs is always the same. Thus, no training on own output
LLMs memorise too much. Humans cannot, so we have to find patterns and understand.
LLMs are collapsed. Their output itself is good, but the distribution of their outputs is always the same. Thus, no training on own output
LLMs memorise too much. Humans cannot, so we have to find patterns and understand.
October 27, 2025 at 10:58 AM
Interesting thoughts from A. Karpathy's interview at the Dwarkesh podcast:
LLMs are collapsed. Their output itself is good, but the distribution of their outputs is always the same. Thus, no training on own output
LLMs memorise too much. Humans cannot, so we have to find patterns and understand.
LLMs are collapsed. Their output itself is good, but the distribution of their outputs is always the same. Thus, no training on own output
LLMs memorise too much. Humans cannot, so we have to find patterns and understand.
Reposted by Raphael Bednarsky

🧬 CAR T cells demonstrate the power of engineered cells as therapeutics. But they fail for most patients. Can CRISPR help here? Our new paper in Nature (www.nature.com/articles/s41...) presents a screening platform to optimize immunotherapies & discover boosters of CAR T cell function. (1/13)

September 24, 2025 at 6:42 PM
🧬 CAR T cells demonstrate the power of engineered cells as therapeutics. But they fail for most patients. Can CRISPR help here? Our new paper in Nature (www.nature.com/articles/s41...) presents a screening platform to optimize immunotherapies & discover boosters of CAR T cell function. (1/13)
Reposted by Raphael Bednarsky
🛡️How do macrophages tailor their defenses to different pathogens? Our new paper in @cp-cellsystems.bsky.social combines dense multi-omics time series with high‐content CRISPR screens (CROP-seq) to map the regulatory landscape underlying macrophage immune responses: www.cell.com/cell-systems... (1/9)

August 12, 2025 at 4:46 PM
🛡️How do macrophages tailor their defenses to different pathogens? Our new paper in @cp-cellsystems.bsky.social combines dense multi-omics time series with high‐content CRISPR screens (CROP-seq) to map the regulatory landscape underlying macrophage immune responses: www.cell.com/cell-systems... (1/9)
Reposted by Raphael Bednarsky

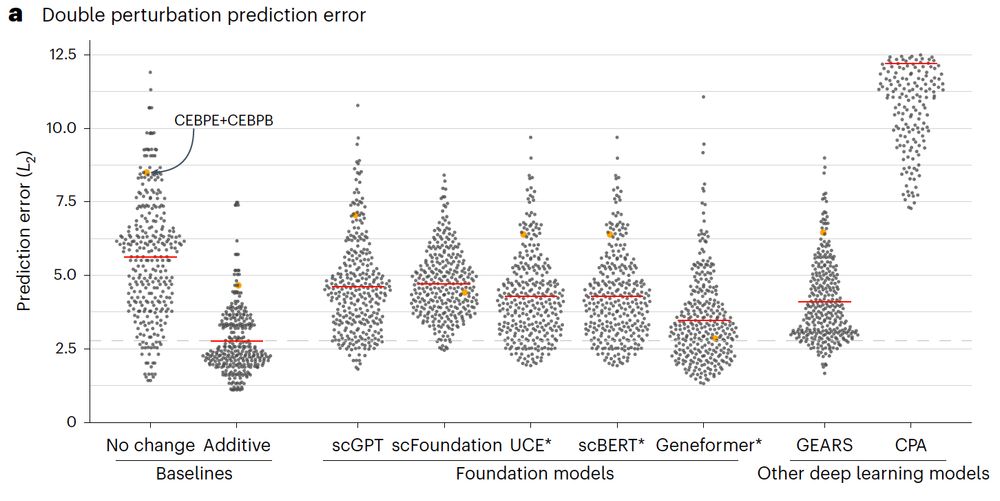
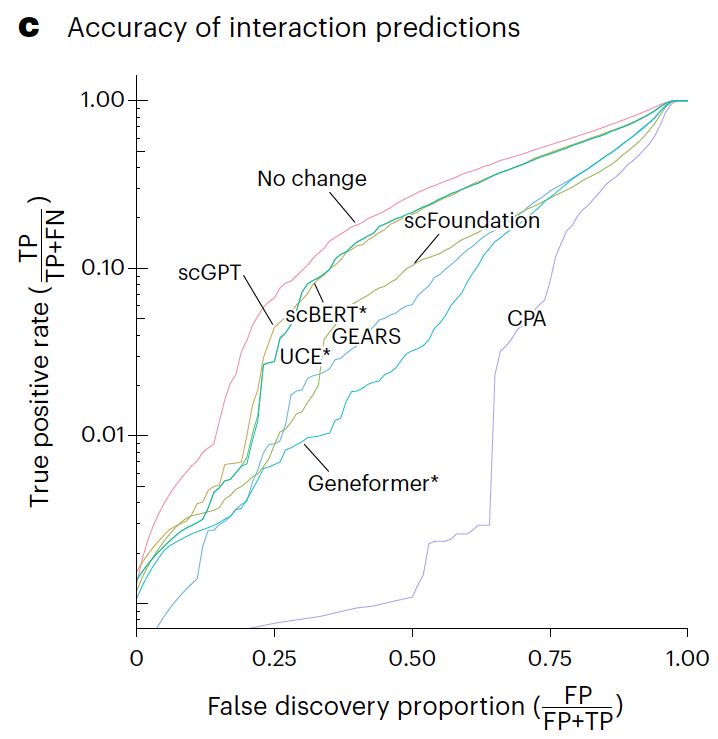
Our paper benchmarking foundation models for perturbation effect prediction is finally published 🎉🥳🎉
www.nature.com/articles/s41...
We show that none of the available* models outperform simple linear baselines. Since the original preprint, we added more methods, metrics, and prettier figures!
🧵
www.nature.com/articles/s41...
We show that none of the available* models outperform simple linear baselines. Since the original preprint, we added more methods, metrics, and prettier figures!
🧵
August 4, 2025 at 1:52 PM
Our paper benchmarking foundation models for perturbation effect prediction is finally published 🎉🥳🎉
www.nature.com/articles/s41...
We show that none of the available* models outperform simple linear baselines. Since the original preprint, we added more methods, metrics, and prettier figures!
🧵
www.nature.com/articles/s41...
We show that none of the available* models outperform simple linear baselines. Since the original preprint, we added more methods, metrics, and prettier figures!
🧵
Reposted by Raphael Bednarsky
AI in medicine ready for takeoff 🤖🚁 We flew a drone through the Institute of Artificial Intelligence @MedUniWien. Join us for the trip and watch our team at "work". #AI #biomedicine #innovation #makingof (1/2)
May 6, 2025 at 12:08 PM
AI in medicine ready for takeoff 🤖🚁 We flew a drone through the Institute of Artificial Intelligence @MedUniWien. Join us for the trip and watch our team at "work". #AI #biomedicine #innovation #makingof (1/2)
Really recognize myself here. During analysis, we make many such decisions a day, small and large. A hundred times, I have looked at my own code some time later and the decisions I took made no sense. Perhaps I should force myself to go back over old code with reminders some time after writing it.

The background reading for this session:
genomebiology.biomedcentral.com/articles/10....
genomebiology.biomedcentral.com/articles/10....

Novel predictions arise from contradictions - Genome Biology
genomebiology.biomedcentral.com
April 17, 2025 at 5:53 PM
Really recognize myself here. During analysis, we make many such decisions a day, small and large. A hundred times, I have looked at my own code some time later and the decisions I took made no sense. Perhaps I should force myself to go back over old code with reminders some time after writing it.
Reposted by Raphael Bednarsky

In my view, one major complication we have in "AI" is to focus on large language models, whereas actually I think the key technology steps are thing like attention networks - now a foundational part of large language models (LLMs).
April 12, 2025 at 6:49 AM
In my view, one major complication we have in "AI" is to focus on large language models, whereas actually I think the key technology steps are thing like attention networks - now a foundational part of large language models (LLMs).
Reposted by Raphael Bednarsky

𝗛𝗲𝘆 𝗕𝗹𝘂𝗲𝘀𝗸𝘆, 𝘄𝗲’𝗿𝗲 𝗼𝗳𝗳𝗶𝗰𝗶𝗮𝗹𝗹𝘆 𝗵𝗲𝗿𝗲! 🌌✨
At #CeMM, we’re thrilled to join the growing #BlueskyScience community.
Follow us to hear more about:
🔬 Breakthroughs from our labs
📚 Fresh publications
🎤 Events & symposiums
🌟 Stories from our vibrant scientific community
Let’s explore science together!🧬
At #CeMM, we’re thrilled to join the growing #BlueskyScience community.
Follow us to hear more about:
🔬 Breakthroughs from our labs
📚 Fresh publications
🎤 Events & symposiums
🌟 Stories from our vibrant scientific community
Let’s explore science together!🧬

April 9, 2025 at 6:52 AM
𝗛𝗲𝘆 𝗕𝗹𝘂𝗲𝘀𝗸𝘆, 𝘄𝗲’𝗿𝗲 𝗼𝗳𝗳𝗶𝗰𝗶𝗮𝗹𝗹𝘆 𝗵𝗲𝗿𝗲! 🌌✨
At #CeMM, we’re thrilled to join the growing #BlueskyScience community.
Follow us to hear more about:
🔬 Breakthroughs from our labs
📚 Fresh publications
🎤 Events & symposiums
🌟 Stories from our vibrant scientific community
Let’s explore science together!🧬
At #CeMM, we’re thrilled to join the growing #BlueskyScience community.
Follow us to hear more about:
🔬 Breakthroughs from our labs
📚 Fresh publications
🎤 Events & symposiums
🌟 Stories from our vibrant scientific community
Let’s explore science together!🧬
Reposted by Raphael Bednarsky

Many standards matter (e.g. robustness analysis of computational results, which is sadly many journals / authors / reviewers skip. I think we need to make more effort to figure out what is needed for robust and sound and what is high-bar "gate-keeping", aka "this depth of mechanistic claim.

In my experience, most standards in the field are not a matter of rigor but rather gatekeeping in the form of make-work. Think I'm wrong? Ask any expert in the field *why* such-and-such standard is in place and the evidence to support its importance, and watch them squirm. (Yes, exceptions exist.)
January 6, 2025 at 12:20 AM
Many standards matter (e.g. robustness analysis of computational results, which is sadly many journals / authors / reviewers skip. I think we need to make more effort to figure out what is needed for robust and sound and what is high-bar "gate-keeping", aka "this depth of mechanistic claim.
Always found it a pity to just drop the heterogeneity in sc data via pseudobulking. Looks promising, but let’s see if it stands the test of time

How to do differential expression with scRNAseq data? State of the art is "pseudo-bulk" analysis with RNA-seq methods like edgeR or DESeq2, where "cell type" is encoded as discrete categories. Biologically, discrete categories are not always the most appropriate concept.(1/3)
doi.org/10.1038/s415...
doi.org/10.1038/s415...
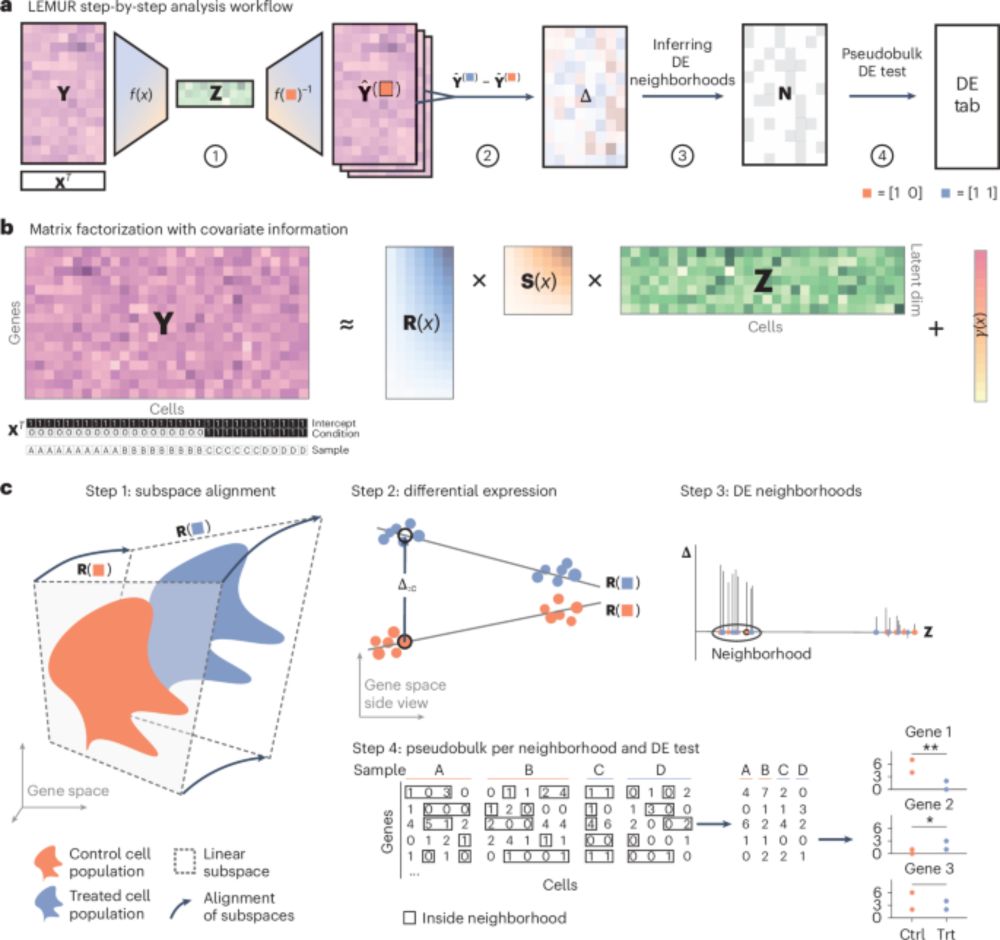
Analysis of multi-condition single-cell data with latent embedding multivariate regression - Nature Genetics
Latent embedding multivariate regression models multi-condition single-cell RNA-seq using a continuous latent space, enabling data integration, per-cell gene expression prediction and clustering-free ...
doi.org
January 3, 2025 at 11:08 PM
Always found it a pity to just drop the heterogeneity in sc data via pseudobulking. Looks promising, but let’s see if it stands the test of time