



@pjain9.bsky.social
Excited that this model is out! It's an amazing model with strong coding capabilities. Try it out using aistudio!
🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
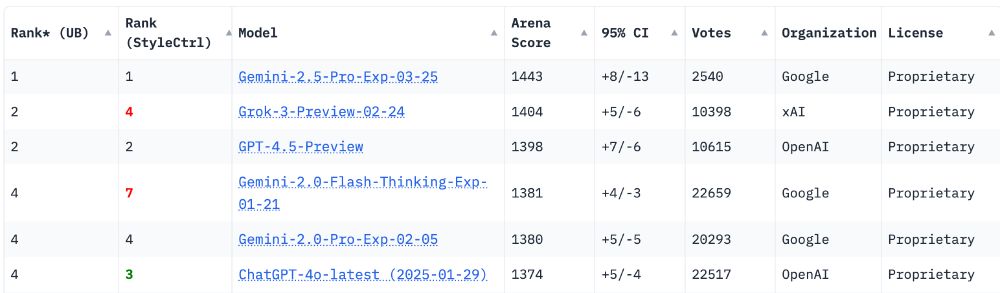
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇

March 25, 2025 at 6:01 PM
Excited that this model is out! It's an amazing model with strong coding capabilities. Try it out using aistudio!
Reposted

🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
March 25, 2025 at 5:25 PM
🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
First bsky post!
Super excited about the new MatQuant work! Allows training a quantized model where 2bit weights are nested within 4bits and so on. This enables "reading" off accurate models that can have 2bit quantization in the first layer, 4bit in the second layer etc. [1/n]
Super excited about the new MatQuant work! Allows training a quantized model where 2bit weights are nested within 4bits and so on. This enables "reading" off accurate models that can have 2bit quantization in the first layer, 4bit in the second layer etc. [1/n]
Delighted to be a minor co-author on this work, led by
Pranav Nair: Combining losses for different Matyroshka-nested groups of bits in each weight within a neural network leads to an accuracy improvement for models (esp. 2-bit reps).
Paper: "Matryoshka Quantization" at arxiv.org/abs/2502.06786
Pranav Nair: Combining losses for different Matyroshka-nested groups of bits in each weight within a neural network leads to an accuracy improvement for models (esp. 2-bit reps).
Paper: "Matryoshka Quantization" at arxiv.org/abs/2502.06786

February 12, 2025 at 11:36 AM
First bsky post!
Super excited about the new MatQuant work! Allows training a quantized model where 2bit weights are nested within 4bits and so on. This enables "reading" off accurate models that can have 2bit quantization in the first layer, 4bit in the second layer etc. [1/n]
Super excited about the new MatQuant work! Allows training a quantized model where 2bit weights are nested within 4bits and so on. This enables "reading" off accurate models that can have 2bit quantization in the first layer, 4bit in the second layer etc. [1/n]
Reposted
Delighted to be a minor co-author on this work, led by
Pranav Nair: Combining losses for different Matyroshka-nested groups of bits in each weight within a neural network leads to an accuracy improvement for models (esp. 2-bit reps).
Paper: "Matryoshka Quantization" at arxiv.org/abs/2502.06786
Pranav Nair: Combining losses for different Matyroshka-nested groups of bits in each weight within a neural network leads to an accuracy improvement for models (esp. 2-bit reps).
Paper: "Matryoshka Quantization" at arxiv.org/abs/2502.06786
February 11, 2025 at 5:41 PM
Delighted to be a minor co-author on this work, led by
Pranav Nair: Combining losses for different Matyroshka-nested groups of bits in each weight within a neural network leads to an accuracy improvement for models (esp. 2-bit reps).
Paper: "Matryoshka Quantization" at arxiv.org/abs/2502.06786
Pranav Nair: Combining losses for different Matyroshka-nested groups of bits in each weight within a neural network leads to an accuracy improvement for models (esp. 2-bit reps).
Paper: "Matryoshka Quantization" at arxiv.org/abs/2502.06786