




Maria Valentini
@mvalentini.bsky.social
computer science/cognitive science PhD student @ CU Boulder • computational psycholinguistics, NLP for education, AI ethics
Reposted by Maria Valentini

This is the third story I've read in a month about how AI chatbots are leading people into psychological crises.
Gift link
Gift link

They Asked an A.I. Chatbot Questions. The Answers Sent Them Spiraling.
www.nytimes.com
June 14, 2025 at 2:45 AM
This is the third story I've read in a month about how AI chatbots are leading people into psychological crises.
Gift link
Gift link
Reposted by Maria Valentini

I don’t really have the energy for politics right now. So I will observe without comment:
Executive Order 14110 was revoked (Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence)
Executive Order 14110 was revoked (Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence)
January 21, 2025 at 12:34 AM
I don’t really have the energy for politics right now. So I will observe without comment:
Executive Order 14110 was revoked (Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence)
Executive Order 14110 was revoked (Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence)
Excited to be presenting my work with @teaywright.bsky.social at #COLING2025 next week in Abu Dhabi! Find us in poster session 6/E on Jan 22nd (11 AM in the atrium).
Paper: arxiv.org/abs/2412.17427
Paper: arxiv.org/abs/2412.17427

Measuring Contextual Informativeness in Child-Directed Text
To address an important gap in creating children's stories for vocabulary enrichment, we investigate the automatic evaluation of how well stories convey the semantics of target vocabulary words, a tas...
arxiv.org
January 16, 2025 at 11:16 PM
Excited to be presenting my work with @teaywright.bsky.social at #COLING2025 next week in Abu Dhabi! Find us in poster session 6/E on Jan 22nd (11 AM in the atrium).
Paper: arxiv.org/abs/2412.17427
Paper: arxiv.org/abs/2412.17427
Reposted by Maria Valentini

1. Can you stop companies from training generative AI using your data? No, not currently.
2. Is this dataset meant for training generative AI? 🤷♀️ but more likely for research and statistical analysis.
3. Is it ok to duplicate and distribute people’s data without agency to opt out? I’d argue no.
2. Is this dataset meant for training generative AI? 🤷♀️ but more likely for research and statistical analysis.
3. Is it ok to duplicate and distribute people’s data without agency to opt out? I’d argue no.

First dataset for the new @huggingface.bsky.social @bsky.app community organisation: one-million-bluesky-posts 🦋
📊 1M public posts from Bluesky's firehose API
🔍 Includes text, metadata, and language predictions
🔬 Perfect to experiment with using ML for Bluesky 🤗
huggingface.co/datasets/blu...
📊 1M public posts from Bluesky's firehose API
🔍 Includes text, metadata, and language predictions
🔬 Perfect to experiment with using ML for Bluesky 🤗
huggingface.co/datasets/blu...

bluesky-community/one-million-bluesky-posts · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 27, 2024 at 7:51 AM
1. Can you stop companies from training generative AI using your data? No, not currently.
2. Is this dataset meant for training generative AI? 🤷♀️ but more likely for research and statistical analysis.
3. Is it ok to duplicate and distribute people’s data without agency to opt out? I’d argue no.
2. Is this dataset meant for training generative AI? 🤷♀️ but more likely for research and statistical analysis.
3. Is it ok to duplicate and distribute people’s data without agency to opt out? I’d argue no.
Reposted by Maria Valentini
So many people, CS researchers included, think that you can explore how an LLM works by simply asking it to tell you what it is doing or "thinking".
Here @jennhu.bsky.social provides an excellent illustration of how that approach fails even at the most basic level.
Here @jennhu.bsky.social provides an excellent illustration of how that approach fails even at the most basic level.

To researchers doing LLM evaluation: prompting is *not a substitute* for direct probability measurements. Check out the camera-ready version of our work, to appear at EMNLP 2023! (w/ @rplevy.bsky.social)
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
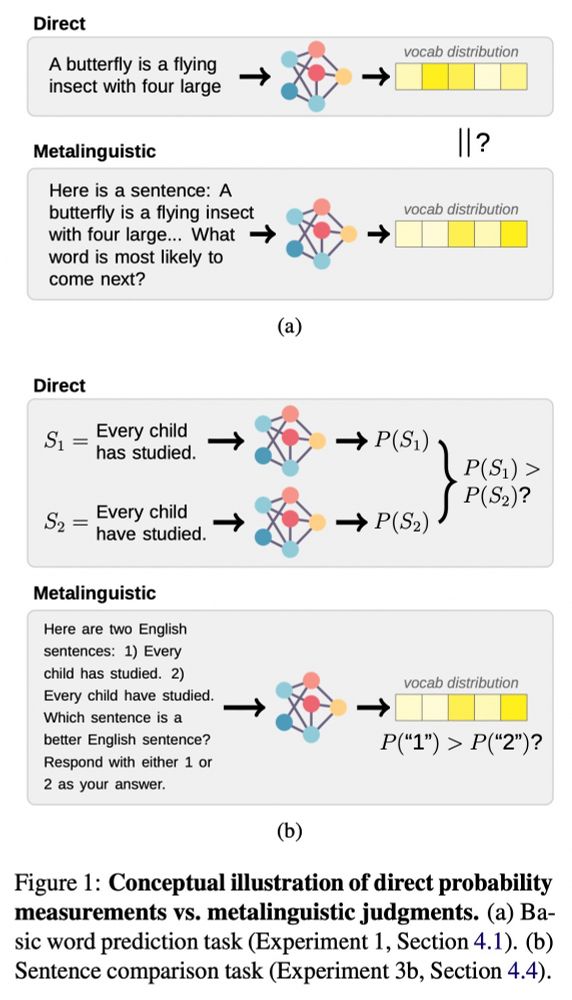
November 17, 2024 at 4:50 AM
So many people, CS researchers included, think that you can explore how an LLM works by simply asking it to tell you what it is doing or "thinking".
Here @jennhu.bsky.social provides an excellent illustration of how that approach fails even at the most basic level.
Here @jennhu.bsky.social provides an excellent illustration of how that approach fails even at the most basic level.