



Ilker Kesen
@ilkerkesen.bsky.social
Postdoctoral Scientist at University of Copenhagen. I am currently more focused on developing pixel language models. #nlproc #multilinguality #multimodality
I'm forcing GPT-5.1 to translate some English text to some target language that I don't know. It decides to use its thinking feature, and then reasons about switching to the target language for the entire output, including explanations and conversational parts. Sigh.
November 14, 2025 at 2:31 PM
I'm forcing GPT-5.1 to translate some English text to some target language that I don't know. It decides to use its thinking feature, and then reasons about switching to the target language for the entire output, including explanations and conversational parts. Sigh.
This week at #EMNLP2025, I'll present our research on pretraining a multilingual pixel language model. Join the multilinguality session on Friday at 10:30 in Room A301 to learn more about pixel models and their benefits in multilingual settings. (Unfortunately I’ll be on Zoom)

November 3, 2025 at 5:39 PM
This week at #EMNLP2025, I'll present our research on pretraining a multilingual pixel language model. Join the multilinguality session on Friday at 10:30 in Room A301 to learn more about pixel models and their benefits in multilingual settings. (Unfortunately I’ll be on Zoom)
Reposted by Ilker Kesen
When is a language hard to model? Previous research has suggested that morphological complexity both does and does not play a role, but it does so by relating the performance of language models to corpus statistics of words or subword tokens in isolation.

November 3, 2025 at 11:53 AM
When is a language hard to model? Previous research has suggested that morphological complexity both does and does not play a role, but it does so by relating the performance of language models to corpus statistics of words or subword tokens in isolation.
📢New preprint: We introduce 📏Cetvel, a unified benchmark for evaluating language understanding, generation, and cultural capacity of LLMs in Turkish🇹🇷 #AI #LLM #NLProc
Joint work with Abrek Er, @gozdegulsahin.bsky.social, @aykuterdem.bsky.social from KUIS AI Center.
Joint work with Abrek Er, @gozdegulsahin.bsky.social, @aykuterdem.bsky.social from KUIS AI Center.

September 5, 2025 at 1:40 PM
📢New preprint: We introduce 📏Cetvel, a unified benchmark for evaluating language understanding, generation, and cultural capacity of LLMs in Turkish🇹🇷 #AI #LLM #NLProc
Joint work with Abrek Er, @gozdegulsahin.bsky.social, @aykuterdem.bsky.social from KUIS AI Center.
Joint work with Abrek Er, @gozdegulsahin.bsky.social, @aykuterdem.bsky.social from KUIS AI Center.
Excited to share that our paper "Multilingual Pretraining for Pixel Language Models" has been accepted to the #EMNLP2025 main conference! Please see the thread below and the paper itself for more details.
Announcing our recent work “Multilingual Pretraining for Pixel Language Models”! We introduce PIXEL-M4, a pixel language model pretrained on four visually & linguistically diverse scripts: English, Hindi, Ukrainian & Simplified Chinese. #NLProc

August 21, 2025 at 12:42 PM
Excited to share that our paper "Multilingual Pretraining for Pixel Language Models" has been accepted to the #EMNLP2025 main conference! Please see the thread below and the paper itself for more details.
Announcing our recent work “Multilingual Pretraining for Pixel Language Models”! We introduce PIXEL-M4, a pixel language model pretrained on four visually & linguistically diverse scripts: English, Hindi, Ukrainian & Simplified Chinese. #NLProc
June 4, 2025 at 1:45 PM
Announcing our recent work “Multilingual Pretraining for Pixel Language Models”! We introduce PIXEL-M4, a pixel language model pretrained on four visually & linguistically diverse scripts: English, Hindi, Ukrainian & Simplified Chinese. #NLProc
Reposted by Ilker Kesen

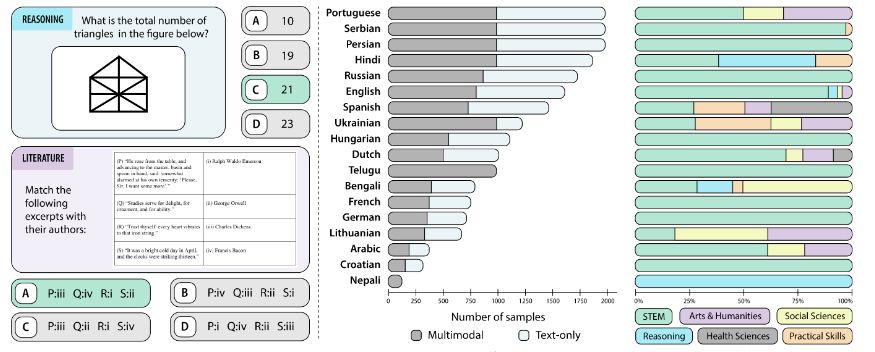
Today we are releasing Kaleidoscope 🎉
A comprehensive multimodal & multilingual benchmark for VLMs! It contains real questions from exams in different languages.
🌍 20,911 questions and 18 languages
📚 14 subjects (STEM → Humanities)
📸 55% multimodal questions
A comprehensive multimodal & multilingual benchmark for VLMs! It contains real questions from exams in different languages.
🌍 20,911 questions and 18 languages
📚 14 subjects (STEM → Humanities)
📸 55% multimodal questions
April 10, 2025 at 10:31 AM
Today we are releasing Kaleidoscope 🎉
A comprehensive multimodal & multilingual benchmark for VLMs! It contains real questions from exams in different languages.
🌍 20,911 questions and 18 languages
📚 14 subjects (STEM → Humanities)
📸 55% multimodal questions
A comprehensive multimodal & multilingual benchmark for VLMs! It contains real questions from exams in different languages.
🌍 20,911 questions and 18 languages
📚 14 subjects (STEM → Humanities)
📸 55% multimodal questions