




Amélie Viallet
@ameeelie.bsky.social
Working at HF
I love simple things and making them even simpler.
I create both digital and physical products.
I co-created Argilla, an Open-Source app for all who care about doing AI projects responsibly by caring about their data.
I love simple things and making them even simpler.
I create both digital and physical products.
I co-created Argilla, an Open-Source app for all who care about doing AI projects responsibly by caring about their data.
Introducing Hugging Face Sheets, where we explore how to create more accurate and reliable structured data with AI and web sources.
June 10, 2025 at 2:39 PM
Introducing Hugging Face Sheets, where we explore how to create more accurate and reliable structured data with AI and web sources.
Exciting news! I’m designing an open-source app that helps AI builders create high-quality datasets in minutes—whether they start with data or not.
🍆 Watch your dataset grow consistently column by column
🪁 Adjust data generation anytime
🦄 Stay in control while automation does the heavy lifting
🍆 Watch your dataset grow consistently column by column
🪁 Adjust data generation anytime
🦄 Stay in control while automation does the heavy lifting

March 17, 2025 at 2:25 PM
Exciting news! I’m designing an open-source app that helps AI builders create high-quality datasets in minutes—whether they start with data or not.
🍆 Watch your dataset grow consistently column by column
🪁 Adjust data generation anytime
🦄 Stay in control while automation does the heavy lifting
🍆 Watch your dataset grow consistently column by column
🪁 Adjust data generation anytime
🦄 Stay in control while automation does the heavy lifting
Cela calme la frénésie autour de l'IA qui pourrait s'emparer de tous les sujets, tous les domaines avec pertinence. Elle éclaire des réflexions sur le lien entre art et automatisation de certains “gestes”.
lnkd.in/dPgVApDA
lnkd.in/dPgVApDA

March 14, 2025 at 1:46 PM
Cela calme la frénésie autour de l'IA qui pourrait s'emparer de tous les sujets, tous les domaines avec pertinence. Elle éclaire des réflexions sur le lien entre art et automatisation de certains “gestes”.
lnkd.in/dPgVApDA
lnkd.in/dPgVApDA
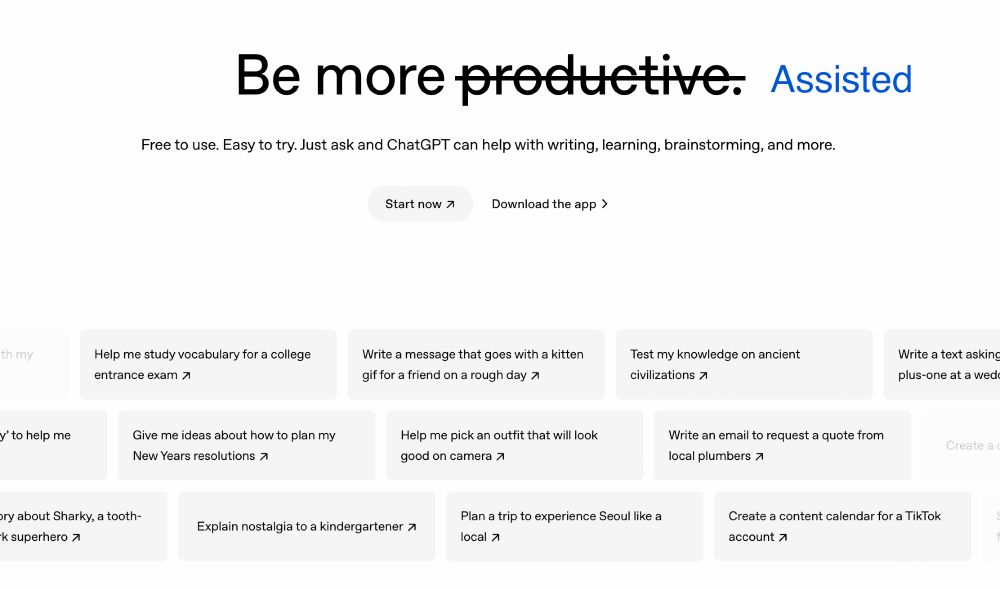
About the last ChatGPT home page:
“Be more assisted” would be a more accurate title, in my opinion.
“Be more assisted” would be a more accurate title, in my opinion.
February 20, 2025 at 1:01 PM
About the last ChatGPT home page:
“Be more assisted” would be a more accurate title, in my opinion.
“Be more assisted” would be a more accurate title, in my opinion.
Reposted by Amélie Viallet

Of course L'Express was obliged to use a photo of Sam Altman to best illustrate a conversation with me.
Of course neither a) taking a new picture of me during the interview, nor b) asking me to provide a picture of myself were impossible.
Of course.
Of course neither a) taking a new picture of me during the interview, nor b) asking me to provide a picture of myself were impossible.
Of course.

February 11, 2025 at 4:18 PM
Of course L'Express was obliged to use a photo of Sam Altman to best illustrate a conversation with me.
Of course neither a) taking a new picture of me during the interview, nor b) asking me to provide a picture of myself were impossible.
Of course.
Of course neither a) taking a new picture of me during the interview, nor b) asking me to provide a picture of myself were impossible.
Of course.
Reposted by Amélie Viallet

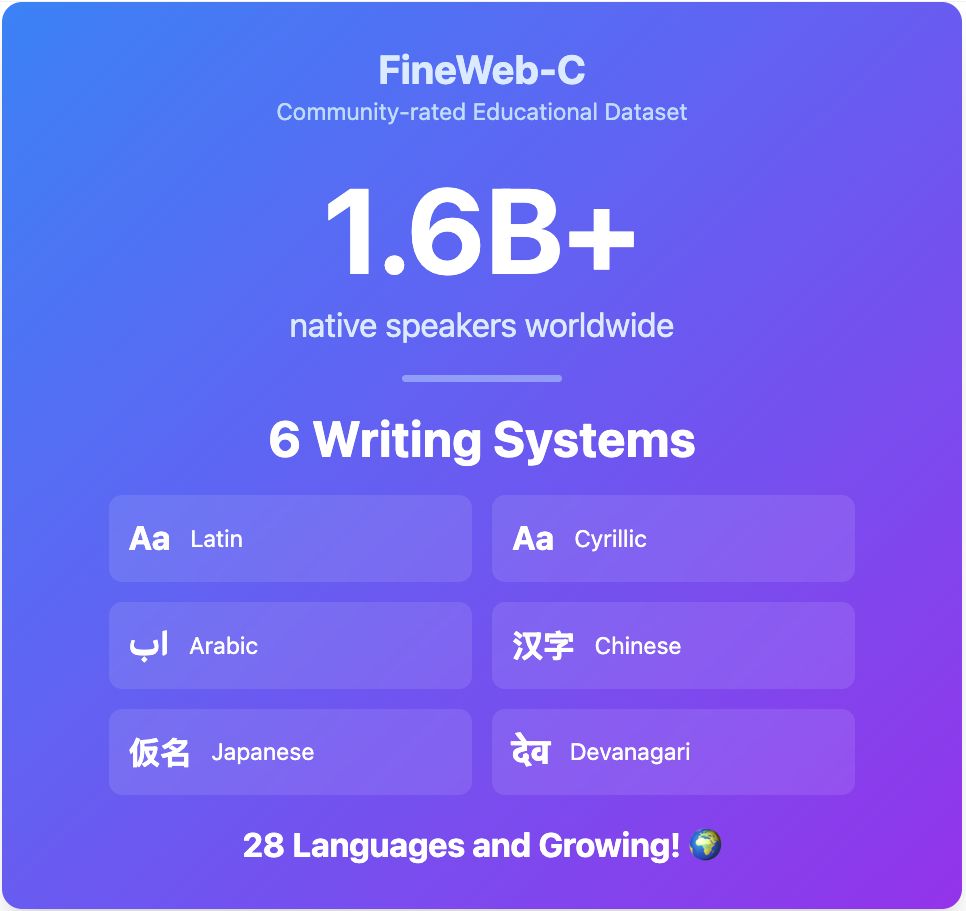
🌍 Big step for multilingual AI data!
The @hf.co community has rated educational content in languages spoken by 1.6 billion people! New additions:
• Japanese
• Italian
• Old High German
These ratings can help enhance training data for major world languages.
The @hf.co community has rated educational content in languages spoken by 1.6 billion people! New additions:
• Japanese
• Italian
• Old High German
These ratings can help enhance training data for major world languages.
January 27, 2025 at 12:30 PM
🌍 Big step for multilingual AI data!
The @hf.co community has rated educational content in languages spoken by 1.6 billion people! New additions:
• Japanese
• Italian
• Old High German
These ratings can help enhance training data for major world languages.
The @hf.co community has rated educational content in languages spoken by 1.6 billion people! New additions:
• Japanese
• Italian
• Old High German
These ratings can help enhance training data for major world languages.
Reposted by Amélie Viallet
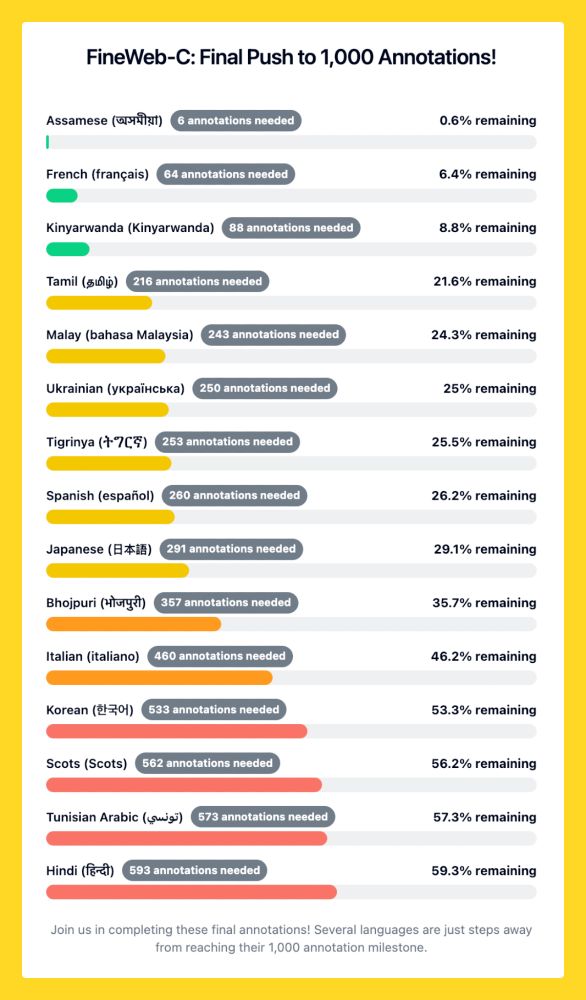
The finish line is near! We're building FineWeb-Edu for many languages and need your help 🤗
Many FineWeb-C languages are close to 1,000 annotations!
Assamese is 99.4% done, French needs 64 more annotations, Tamil: 216.
Please help us reach the goal: huggingface.co/spaces/data-...
Many FineWeb-C languages are close to 1,000 annotations!
Assamese is 99.4% done, French needs 64 more annotations, Tamil: 216.
Please help us reach the goal: huggingface.co/spaces/data-...
January 6, 2025 at 2:32 PM
The finish line is near! We're building FineWeb-Edu for many languages and need your help 🤗
Many FineWeb-C languages are close to 1,000 annotations!
Assamese is 99.4% done, French needs 64 more annotations, Tamil: 216.
Please help us reach the goal: huggingface.co/spaces/data-...
Many FineWeb-C languages are close to 1,000 annotations!
Assamese is 99.4% done, French needs 64 more annotations, Tamil: 216.
Please help us reach the goal: huggingface.co/spaces/data-...
Reposted by Amélie Viallet

Imagine creating custom datasets and training AI models WITHOUT writing a single line of code. We did and made it a reality.
@hf.co Synthetic Data Generator
Blog: huggingface.co/blog
Space: huggingface.co/spaces/argil...
GitHub: github.com/argilla-io/s...
@hf.co Synthetic Data Generator
Blog: huggingface.co/blog
Space: huggingface.co/spaces/argil...
GitHub: github.com/argilla-io/s...

December 16, 2024 at 3:37 PM
Imagine creating custom datasets and training AI models WITHOUT writing a single line of code. We did and made it a reality.
@hf.co Synthetic Data Generator
Blog: huggingface.co/blog
Space: huggingface.co/spaces/argil...
GitHub: github.com/argilla-io/s...
@hf.co Synthetic Data Generator
Blog: huggingface.co/blog
Space: huggingface.co/spaces/argil...
GitHub: github.com/argilla-io/s...
I've just contributed 20 examples to FineWeb 2 in French! Join me; we are already a couple of annotators there!
data-is-better-together-fineweb-c.hf.space/share-your-p...
data-is-better-together-fineweb-c.hf.space/share-your-p...

fra - français - French
Join and contribute to the dataset fra - français - French
data-is-better-together-fineweb-c.hf.space
December 10, 2024 at 3:58 PM
I've just contributed 20 examples to FineWeb 2 in French! Join me; we are already a couple of annotators there!
data-is-better-together-fineweb-c.hf.space/share-your-p...
data-is-better-together-fineweb-c.hf.space/share-your-p...
In a couple of minutes, we’ll officially make the FineWeb 2 Annotation Sprint.
🎶 Go with your rhythms, and do what you can.
🤏 There is no minimum.
👐 Each contribution is welcomed.
The more we are, the better the result will be.
🎶 Go with your rhythms, and do what you can.
🤏 There is no minimum.
👐 Each contribution is welcomed.
The more we are, the better the result will be.

December 10, 2024 at 11:52 AM
In a couple of minutes, we’ll officially make the FineWeb 2 Annotation Sprint.
🎶 Go with your rhythms, and do what you can.
🤏 There is no minimum.
👐 Each contribution is welcomed.
The more we are, the better the result will be.
🎶 Go with your rhythms, and do what you can.
🤏 There is no minimum.
👐 Each contribution is welcomed.
The more we are, the better the result will be.
Reposted by Amélie Viallet

Vanakkam makkalae , glad that I’ll be leading the FineWeb 2 collaborative annotation sprint for Tamil! 🤗
I’ll be helping to build an open dataset to improve language models for our language. Do join the process of improving models !
huggingface.co/spaces/Huggi...
huggingface.co/spaces/data-...
I’ll be helping to build an open dataset to improve language models for our language. Do join the process of improving models !
huggingface.co/spaces/Huggi...
huggingface.co/spaces/data-...


December 10, 2024 at 11:05 AM
Vanakkam makkalae , glad that I’ll be leading the FineWeb 2 collaborative annotation sprint for Tamil! 🤗
I’ll be helping to build an open dataset to improve language models for our language. Do join the process of improving models !
huggingface.co/spaces/Huggi...
huggingface.co/spaces/data-...
I’ll be helping to build an open dataset to improve language models for our language. Do join the process of improving models !
huggingface.co/spaces/Huggi...
huggingface.co/spaces/data-...
I am thrilled to see Argilla increasingly used to enable impactful collaborative work around datasets.
Next week, we’ll announce a massive multi-language open annotation sprint to ensure all languages advance equally in AI.
Next week, we’ll announce a massive multi-language open annotation sprint to ensure all languages advance equally in AI.

December 6, 2024 at 11:38 AM
I am thrilled to see Argilla increasingly used to enable impactful collaborative work around datasets.
Next week, we’ll announce a massive multi-language open annotation sprint to ensure all languages advance equally in AI.
Next week, we’ll announce a massive multi-language open annotation sprint to ensure all languages advance equally in AI.
[UX-UI update]
The latest update on the Argilla homepage provides a clear overview of your annotation projects, enhances project monitoring, and highlights the importance of collaboration in data curation.
November 29, 2024 at 2:07 PM
[UX-UI update]
The latest update on the Argilla homepage provides a clear overview of your annotation projects, enhances project monitoring, and highlights the importance of collaboration in data curation.
👀 Who said the Argilla tool was only for text? I am proud of my brilliant teammates for setting up this significant initiative 🤗 @benburtenshaw.bsky.social @davidberenstein.bsky.social @danielvanstrien.bsky.social @dvilasuero.hf.co
Let’s make a generation of amazing open source image generation models from high quality data.
The best image generation models train on human preferences. Unfortunately, many of these datasets are closed. Let’s change that!
🧵 we're building a community dataset and we need help reviewing!
The best image generation models train on human preferences. Unfortunately, many of these datasets are closed. Let’s change that!
🧵 we're building a community dataset and we need help reviewing!

November 26, 2024 at 1:08 PM
👀 Who said the Argilla tool was only for text? I am proud of my brilliant teammates for setting up this significant initiative 🤗 @benburtenshaw.bsky.social @davidberenstein.bsky.social @danielvanstrien.bsky.social @dvilasuero.hf.co
Reposted by Amélie Viallet

Let’s make a generation of amazing open source image generation models from high quality data.
The best image generation models train on human preferences. Unfortunately, many of these datasets are closed. Let’s change that!
🧵 we're building a community dataset and we need help reviewing!
The best image generation models train on human preferences. Unfortunately, many of these datasets are closed. Let’s change that!
🧵 we're building a community dataset and we need help reviewing!
November 26, 2024 at 12:00 PM
Let’s make a generation of amazing open source image generation models from high quality data.
The best image generation models train on human preferences. Unfortunately, many of these datasets are closed. Let’s change that!
🧵 we're building a community dataset and we need help reviewing!
The best image generation models train on human preferences. Unfortunately, many of these datasets are closed. Let’s change that!
🧵 we're building a community dataset and we need help reviewing!
This is great, one of the responses could be "more effort on open datasets"

There are significant ethical considerations related to AI hype which have not been properly considered even as organizations and public bodies purport to advance safe, responsible, trustworthy, and ethical AI. Tania Duarte, founder of We and AI, digs in: www.techpolicy.press/as-the-ai-bu...

As the AI Bubble Deflates, the Ethics of Hype Are in the Spotlight | TechPolicy.Press
Tania Duarte is founder of We and AI, a UK non-profit focusing on better AI literacy for social inclusion.
www.techpolicy.press
November 26, 2024 at 8:41 AM
This is great, one of the responses could be "more effort on open datasets"
Soon: Another sprint to label all together a big dataset for many languages! Nominate yourself to lead your language community!

Let's make AI more inclusive.
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
November 26, 2024 at 7:21 AM
Soon: Another sprint to label all together a big dataset for many languages! Nominate yourself to lead your language community!
Reposted by Amélie Viallet
"Naftali was assigned to train AI to recognize and weed out pornography, hate speech and excessive violence, which meant sifting through the worst of the worst content online for hours on end."
So much of AI is based on exploiting workers in precarious conditions 😔
www.cbsnews.com/news/labeler...
So much of AI is based on exploiting workers in precarious conditions 😔
www.cbsnews.com/news/labeler...

Labelers training AI say they're overworked, underpaid and exploited by big American tech companies
Digital workers in Kenya had to sift through horrific online content to train AI, but say they were underpaid, overworked, and got inadequate mental health support. So they're fighting back.
www.cbsnews.com
November 25, 2024 at 3:16 PM
"Naftali was assigned to train AI to recognize and weed out pornography, hate speech and excessive violence, which meant sifting through the worst of the worst content online for hours on end."
So much of AI is based on exploiting workers in precarious conditions 😔
www.cbsnews.com/news/labeler...
So much of AI is based on exploiting workers in precarious conditions 😔
www.cbsnews.com/news/labeler...
What about building a high-quality dataset together and making the result available to the whole Open-Source community?
You are all welcome with or without code skills, with or without a background in AI.
It's about democratizing access to AI projects and making how they work transparent.
You are all welcome with or without code skills, with or without a background in AI.
It's about democratizing access to AI projects and making how they work transparent.

November 25, 2024 at 3:33 PM
What about building a high-quality dataset together and making the result available to the whole Open-Source community?
You are all welcome with or without code skills, with or without a background in AI.
It's about democratizing access to AI projects and making how they work transparent.
You are all welcome with or without code skills, with or without a background in AI.
It's about democratizing access to AI projects and making how they work transparent.
⚫️⚪️ If you think transparency is key to building the image generation models of tomorrow, consider contributing to a massive open dataset.
Follow huggingface.co/data-is-bett... not to miss the announcement!
Follow huggingface.co/data-is-bett... not to miss the announcement!

November 22, 2024 at 3:05 PM
⚫️⚪️ If you think transparency is key to building the image generation models of tomorrow, consider contributing to a massive open dataset.
Follow huggingface.co/data-is-bett... not to miss the announcement!
Follow huggingface.co/data-is-bett... not to miss the announcement!
🏺🎞️ Beautiful collection of graphic materials to create better images with AI. www.are.na/aixdesign/ai...

🧧 AIoAI / Curated Images + Sub-Collections | Are.na
This curated collection of images, cut-outs, and scrap materials is here to insp…rce or explore the context of any image, we recommend using Google Image Search.
www.are.na
November 22, 2024 at 10:46 AM
🏺🎞️ Beautiful collection of graphic materials to create better images with AI. www.are.na/aixdesign/ai...
Reposted by Amélie Viallet

I'm making it easier and easier to watermark generated AI content with @huggingface.bsky.social and @gradio-hf.bsky.social. Definitely recommend using this when generating. Please let me know if you have additional feature requests, super happy to assist.
huggingface.co/spaces/meg/w...
huggingface.co/spaces/meg/w...

Watermark Demo - a Hugging Face Space by meg
Demo of watermarking with gradio
huggingface.co
November 21, 2024 at 7:49 PM
I'm making it easier and easier to watermark generated AI content with @huggingface.bsky.social and @gradio-hf.bsky.social. Definitely recommend using this when generating. Please let me know if you have additional feature requests, super happy to assist.
huggingface.co/spaces/meg/w...
huggingface.co/spaces/meg/w...
I'm currently discovering some brilliant ideas in [Feminist UX of AI] feminist-ux-of-ai.super.site/ux-of-ai-lib...
Supportive Shadow Prompting
The models we use today are ridden with bias and stereotypes. What if they could inform the users about their known biases, and offer to adapt our prompts to counteract those biases?
feminist-ux-of-ai.super.site
November 22, 2024 at 8:12 AM
I'm currently discovering some brilliant ideas in [Feminist UX of AI] feminist-ux-of-ai.super.site/ux-of-ai-lib...
Reposted by Amélie Viallet

Eh this test making the rounds online is not a good evaluation for expressiveness in my opinion. So much of art is the creator’s documentation of lived experiences and a reflection of conscious choices made because of those experiences. What lived experience does a model averaging to the mean have?

This AI art Turing Test shows that AI images are appealing. It doesn't prove AI is creative or that humans really prefer AI art. Part of what we get out of art comes from the sense of connection to a human artist who wanted to share a vision.
www.astralcodexten.com/p/how-did-yo...
www.astralcodexten.com/p/how-did-yo...

How Did You Do On The AI Art Turing Test?
...
www.astralcodexten.com
November 21, 2024 at 3:32 AM
Eh this test making the rounds online is not a good evaluation for expressiveness in my opinion. So much of art is the creator’s documentation of lived experiences and a reflection of conscious choices made because of those experiences. What lived experience does a model averaging to the mean have?