




Alex Luedtke
@alexluedtke.bsky.social
statistician at harvard med school • causal inference, machine learning, nonparametrics
alexluedtke.com
alexluedtke.com
I'm excited to dig into this new work on numerically approximating efficient influence functions. The main idea seems to be to use a Fourier-type approximation, rather than the kernel-smoother approximation used in earlier approaches.
openreview.net/pdf/cfeab45d...
openreview.net/pdf/cfeab45d...
openreview.net
November 7, 2025 at 3:32 PM
I'm excited to dig into this new work on numerically approximating efficient influence functions. The main idea seems to be to use a Fourier-type approximation, rather than the kernel-smoother approximation used in earlier approaches.
openreview.net/pdf/cfeab45d...
openreview.net/pdf/cfeab45d...
📢 Postdoc opening in stats @harvardmed.bsky.social! Build variable-importance methods so patients know why a treatment is/isn't expected to work for them. Funding from PCORI (non-federal).
Application review starts Dec 1. Details here:
academicpositions.harvard.edu/postings/15365
Application review starts Dec 1. Details here:
academicpositions.harvard.edu/postings/15365
HMS - Postdoctoral Fellow in Health Care Policy - Statistical Methods
The Department of Health Care Policy at Harvard Medical School seeks a highly motivated postdoctoral fellow to join a PCORI-funded project developing new methods to improve the transparency of individ...
academicpositions.harvard.edu
October 22, 2025 at 8:57 PM
📢 Postdoc opening in stats @harvardmed.bsky.social! Build variable-importance methods so patients know why a treatment is/isn't expected to work for them. Funding from PCORI (non-federal).
Application review starts Dec 1. Details here:
academicpositions.harvard.edu/postings/15365
Application review starts Dec 1. Details here:
academicpositions.harvard.edu/postings/15365
New paper on generative modeling of counterfactual distributions! We give a way to answer "what if" questions with generative models.
For example: what would faces look like if they were all smiling?
arxiv.org/abs/2509.16842
For example: what would faces look like if they were all smiling?
arxiv.org/abs/2509.16842



September 24, 2025 at 8:42 PM
New paper on generative modeling of counterfactual distributions! We give a way to answer "what if" questions with generative models.
For example: what would faces look like if they were all smiling?
arxiv.org/abs/2509.16842
For example: what would faces look like if they were all smiling?
arxiv.org/abs/2509.16842
Reposted by Alex Luedtke

Carlos Cinelli, Avi Feller, Guido Imbens, Edward Kennedy, Sara Magliacane, Jose Zubizarreta
Challenges in Statistics: A Dozen Challenges in Causality and Causal Inference
https://arxiv.org/abs/2508.17099
Challenges in Statistics: A Dozen Challenges in Causality and Causal Inference
https://arxiv.org/abs/2508.17099
August 26, 2025 at 5:56 AM
Carlos Cinelli, Avi Feller, Guido Imbens, Edward Kennedy, Sara Magliacane, Jose Zubizarreta
Challenges in Statistics: A Dozen Challenges in Causality and Causal Inference
https://arxiv.org/abs/2508.17099
Challenges in Statistics: A Dozen Challenges in Causality and Causal Inference
https://arxiv.org/abs/2508.17099
Reposted by Alex Luedtke

I want to advertise some relatively recent work which I really like, and have been fortunate to play a small role in.
The paper is titled "A New Proof of Sub-Gaussian Norm Concentration Inequality" (arxiv.org/abs/2503.14347), led by Zishun Liu and Yongxin Chen at Georgia Tech.
The paper is titled "A New Proof of Sub-Gaussian Norm Concentration Inequality" (arxiv.org/abs/2503.14347), led by Zishun Liu and Yongxin Chen at Georgia Tech.

August 19, 2025 at 8:28 AM
I want to advertise some relatively recent work which I really like, and have been fortunate to play a small role in.
The paper is titled "A New Proof of Sub-Gaussian Norm Concentration Inequality" (arxiv.org/abs/2503.14347), led by Zishun Liu and Yongxin Chen at Georgia Tech.
The paper is titled "A New Proof of Sub-Gaussian Norm Concentration Inequality" (arxiv.org/abs/2503.14347), led by Zishun Liu and Yongxin Chen at Georgia Tech.
Neat AI product for improving technical writing.
Tried it on a 50 page draft of a causal ML paper. Of its top 10 comments, 4 concerned minor technical issues I'd missed (notation error, misapplication of definition, etc.). In my experience, vanilla chatbots wouldn't have caught these.
Tried it on a 50 page draft of a causal ML paper. Of its top 10 comments, 4 concerned minor technical issues I'd missed (notation error, misapplication of definition, etc.). In my experience, vanilla chatbots wouldn't have caught these.

I've been working on a new tool, Refine, to make scholars more productive. If you're interested in being among the very first to try the beta, please read on.
Refine leverages the best current AI models to draw your attention to potential errors and clarity issues in research paper drafts.
1/
Refine leverages the best current AI models to draw your attention to potential errors and clarity issues in research paper drafts.
1/
July 24, 2025 at 5:48 AM
Neat AI product for improving technical writing.
Tried it on a 50 page draft of a causal ML paper. Of its top 10 comments, 4 concerned minor technical issues I'd missed (notation error, misapplication of definition, etc.). In my experience, vanilla chatbots wouldn't have caught these.
Tried it on a 50 page draft of a causal ML paper. Of its top 10 comments, 4 concerned minor technical issues I'd missed (notation error, misapplication of definition, etc.). In my experience, vanilla chatbots wouldn't have caught these.
Reposted by Alex Luedtke

Starting to look like I might not be able to work at Harvard anymore due to recent funding cuts. If you know of any open statistical consulting positions that support remote work or are NYC-based, please reach out! 😅
June 4, 2025 at 7:02 PM
Starting to look like I might not be able to work at Harvard anymore due to recent funding cuts. If you know of any open statistical consulting positions that support remote work or are NYC-based, please reach out! 😅
I've advised 15 PhD students—10 were international students. All graduates continue advancing U.S. excellence in research and education. Cutting off this pipeline of talent would be shortsighted.
May 23, 2025 at 3:36 AM
I've advised 15 PhD students—10 were international students. All graduates continue advancing U.S. excellence in research and education. Cutting off this pipeline of talent would be shortsighted.
Reposted by Alex Luedtke

I'm a current Harvard graduate student and I found out today that I had my NSF GRFP terminated without notification. I was awarded this individual research fellowship before even choosing Harvard as my graduate school
May 22, 2025 at 9:38 PM
I'm a current Harvard graduate student and I found out today that I had my NSF GRFP terminated without notification. I was awarded this individual research fellowship before even choosing Harvard as my graduate school
Reposted by Alex Luedtke

Had a great time presenting at #ACIC on doubly robust inference via calibration
Calibrating nuisance estimates in DML protects against model misspecification and slow convergence.
Just one line of code is all it takes.
Calibrating nuisance estimates in DML protects against model misspecification and slow convergence.
Just one line of code is all it takes.

May 19, 2025 at 12:02 AM
Had a great time presenting at #ACIC on doubly robust inference via calibration
Calibrating nuisance estimates in DML protects against model misspecification and slow convergence.
Just one line of code is all it takes.
Calibrating nuisance estimates in DML protects against model misspecification and slow convergence.
Just one line of code is all it takes.
New paper, led by my student Alex Kokot!
We study dataset compression through coreset selection - finding a small, weighted subset of observations that preserves information with respect to some divergence.
arxiv.org/abs/2504.20194
We study dataset compression through coreset selection - finding a small, weighted subset of observations that preserves information with respect to some divergence.
arxiv.org/abs/2504.20194


April 30, 2025 at 12:59 PM
New paper, led by my student Alex Kokot!
We study dataset compression through coreset selection - finding a small, weighted subset of observations that preserves information with respect to some divergence.
arxiv.org/abs/2504.20194
We study dataset compression through coreset selection - finding a small, weighted subset of observations that preserves information with respect to some divergence.
arxiv.org/abs/2504.20194
Reposted by Alex Luedtke

The NIH overhead cut doesn't just hurt universities.
It's deadly to the US economy.
The US is a world leader in tech due to the ecosystem that NIH and NSF propel. It drives innovation for tech transfer, creates a highly-skilled sci/tech workforce, and fosters academic/industry crossfertilization.
It's deadly to the US economy.
The US is a world leader in tech due to the ecosystem that NIH and NSF propel. It drives innovation for tech transfer, creates a highly-skilled sci/tech workforce, and fosters academic/industry crossfertilization.
2. While NSF and NIH indeed have a mission to fund specific research innovations via grantmaking, they do a lot more than that.
Their principal role is support a scientific ecosystem in the United States, that includes everything from education and training to infrastructure and communication.
Their principal role is support a scientific ecosystem in the United States, that includes everything from education and training to infrastructure and communication.
February 8, 2025 at 2:03 AM
The NIH overhead cut doesn't just hurt universities.
It's deadly to the US economy.
The US is a world leader in tech due to the ecosystem that NIH and NSF propel. It drives innovation for tech transfer, creates a highly-skilled sci/tech workforce, and fosters academic/industry crossfertilization.
It's deadly to the US economy.
The US is a world leader in tech due to the ecosystem that NIH and NSF propel. It drives innovation for tech transfer, creates a highly-skilled sci/tech workforce, and fosters academic/industry crossfertilization.
Reposted by Alex Luedtke
Thrilled to share our new paper! We introduce a generalized autoDML framework for smooth functionals in general M-estimation problems, significantly broadening the scope of problems where automatic debiasing can be applied!
Lars van der Laan, Aurelien Bibaut, Nathan Kallus, Alex Luedtke
Automatic Debiased Machine Learning for Smooth Functionals of Nonparametric M-Estimands
https://arxiv.org/abs/2501.11868
Automatic Debiased Machine Learning for Smooth Functionals of Nonparametric M-Estimands
https://arxiv.org/abs/2501.11868
January 22, 2025 at 1:54 PM
Thrilled to share our new paper! We introduce a generalized autoDML framework for smooth functionals in general M-estimation problems, significantly broadening the scope of problems where automatic debiasing can be applied!
Reposted by Alex Luedtke
My traditional end-of-year review: some papers I read and liked in 2024.
donskerclass.github.io/post/papers-...
donskerclass.github.io/post/papers-...
Papers I Liked 2024 | David Childers
This has been another year where I felt like I slacked on my reading, and that probably is genuinely true for the tumultuous last half, but my read folder lists 154, so I can pick out a few that I lik...
donskerclass.github.io
December 31, 2024 at 2:51 PM
My traditional end-of-year review: some papers I read and liked in 2024.
donskerclass.github.io/post/papers-...
donskerclass.github.io/post/papers-...
Welcome, @danielawitten.bsky.social!
November 24, 2024 at 11:04 AM
Welcome, @danielawitten.bsky.social!
Reposted by Alex Luedtke

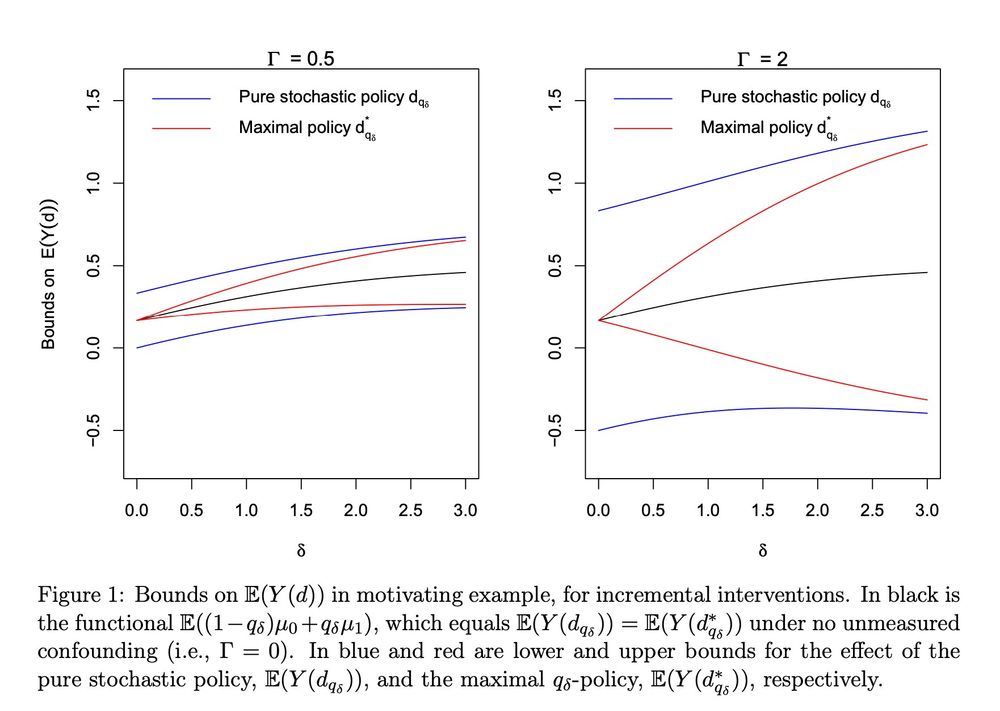
New paper! arxiv.org/pdf/2411.14285
Led by amazing postdoc Alex Levis: www.awlevis.com/about/
We show causal effects of new "soft" interventions are less sensitive to unmeasured confounding
& study which effects are *least* sensitive to confounding -> makes new connections to optimal transport
Led by amazing postdoc Alex Levis: www.awlevis.com/about/
We show causal effects of new "soft" interventions are less sensitive to unmeasured confounding
& study which effects are *least* sensitive to confounding -> makes new connections to optimal transport



November 22, 2024 at 4:39 AM
New paper! arxiv.org/pdf/2411.14285
Led by amazing postdoc Alex Levis: www.awlevis.com/about/
We show causal effects of new "soft" interventions are less sensitive to unmeasured confounding
& study which effects are *least* sensitive to confounding -> makes new connections to optimal transport
Led by amazing postdoc Alex Levis: www.awlevis.com/about/
We show causal effects of new "soft" interventions are less sensitive to unmeasured confounding
& study which effects are *least* sensitive to confounding -> makes new connections to optimal transport
👋 In Tokyo this academic year, on sabbatical at the Institute of Statistical Mathematics.
In town and interested in causal ML? Would love to grab coffee and chat.
In town and interested in causal ML? Would love to grab coffee and chat.
November 12, 2024 at 10:51 AM
👋 In Tokyo this academic year, on sabbatical at the Institute of Statistical Mathematics.
In town and interested in causal ML? Would love to grab coffee and chat.
In town and interested in causal ML? Would love to grab coffee and chat.
Reposted by Alex Luedtke

"The Elements of Differentiable Programming"
link: arxiv.org/abs/2403.14606
Basically: "autodiff - it's everywhere! what is it, and how do you use it?" seems like a good resource for anyone interested in data science, machine learning, "ai," neural nets, etc
#blueskai #stats #mlsky
link: arxiv.org/abs/2403.14606
Basically: "autodiff - it's everywhere! what is it, and how do you use it?" seems like a good resource for anyone interested in data science, machine learning, "ai," neural nets, etc
#blueskai #stats #mlsky

April 2, 2024 at 12:31 AM
"The Elements of Differentiable Programming"
link: arxiv.org/abs/2403.14606
Basically: "autodiff - it's everywhere! what is it, and how do you use it?" seems like a good resource for anyone interested in data science, machine learning, "ai," neural nets, etc
#blueskai #stats #mlsky
link: arxiv.org/abs/2403.14606
Basically: "autodiff - it's everywhere! what is it, and how do you use it?" seems like a good resource for anyone interested in data science, machine learning, "ai," neural nets, etc
#blueskai #stats #mlsky
Do you know someone applying for a PhD in stat/biostat? Suggest they submit their draft application materials for feedback/mentoring!
stat.uw.edu/pre-applicat...
stat.uw.edu/pre-applicat...
PARS | University of Washington Department of Statistics
The Department of Statistics at the University of Washington is launching the pre-application review service (PARS) initiative to provide support and mentorship to PhD applicants from historically marginalized groups.
stat.uw.edu
October 9, 2024 at 1:22 AM
Do you know someone applying for a PhD in stat/biostat? Suggest they submit their draft application materials for feedback/mentoring!
stat.uw.edu/pre-applicat...
stat.uw.edu/pre-applicat...
New paper!
arxiv.org/abs/2405.08675
tldr: automatic differentiation can be used to derive efficient influence functions and construct efficient estimators.
arxiv.org/abs/2405.08675
tldr: automatic differentiation can be used to derive efficient influence functions and construct efficient estimators.




June 25, 2024 at 4:36 PM
New paper!
arxiv.org/abs/2405.08675
tldr: automatic differentiation can be used to derive efficient influence functions and construct efficient estimators.
arxiv.org/abs/2405.08675
tldr: automatic differentiation can be used to derive efficient influence functions and construct efficient estimators.